A Primer On How To Get The Most Out Of Sitemaps
Search crawlers are becoming more and more effective every day in discovering new content pages on websites. But, that process of organic discovery can be slow and spotty, so it’s hardly any solace to sites that publish hundreds of new pages a day, or publish extremely time-sensitive content such as news articles, or publish a […]
Search crawlers are becoming more and more effective every day in discovering new content pages on websites. But, that process of organic discovery can be slow and spotty, so it’s hardly any solace to sites that publish hundreds of new pages a day, or publish extremely time-sensitive content such as news articles, or publish a huge amount of specialized digital media content such as video.
Even with the continuing improvements in organic search for discovering your content, it still takes time for search to find it all. It takes patience on your part, and in many cases, the content found in a crawl has inadequate context to the needed, relevant keywords that make it discoverable to searchers.
Wouldn’t it be cool if a webmaster could just identify a list of content pages you wanted the search engines to crawl, telling them “these are the most important content pages on my site,” and in some cases, even offering a little bit of keyword context to it?
Well, great news! Maybe you missed the memo, but you can use a Sitemap to submit your list of content URLs to the search engines.
Better late than never, but still sweet news, right? What’s that? You already know about Sitemaps? Yeah, well ok, that’s good.
How Well Do You Really Know XML Sitemaps?
But, are you aware of the many different types of Sitemaps you can use, what the differences are between them, what each one’s intended role is, and why you are probably still not doing it right? Ah, now we’re talking. Let’s sit down and have a little refresher talk about Sitemaps.
Sitemaps go back to the mid-2000’s. Google started the idea in 2005; then, other search engines quickly joined the effort, and a common industry supported XML schema was developed in 2006.
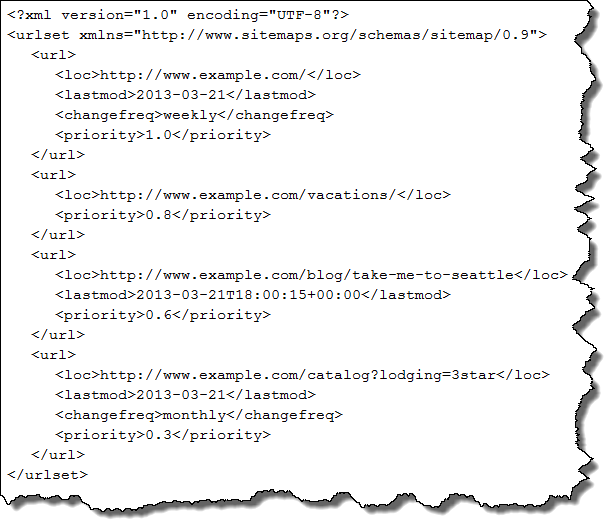
Most Sitemaps are not intended for human reader consumption. Rather, they are designed to be consumed directly by search engines themselves. This is a big difference from your standard webpage!
Note that placing a URL in a Sitemap is considered to be a hint to a search engine. Some people mistakenly believe it is a command to the search engines to index that URL. If only, but not so!
While you may not get all of your URLs indexed from your Sitemap, it’s well worth the effort to create one because it’s much more efficient and effective than waiting for your new site to be fully crawled organically. And, organic crawling is no more promising for indexing, anyway. Each search engine will determine whether or not to index your page after it has been crawled, Sitemap or not. Just think of your Sitemap as your detailed, requested crawling list for search!
Often, Sitemaps are a jumbled mess, and search engines have a hard time parsing non-standard or invalid code, as well as managing URLs that return either HTTP 404, 301 or 302 rather than return HTTP 200.
Bing used to measure the number of non-200 links in the Sitemap, and if it exceeded 1% of the number of URLs submitted, the Sitemap was abandoned. I’m not sure if that is still true today; but frankly, it makes a lot of sense to ensure all of the links in your Sitemaps, which are crawler feeds directly to search, are as clean as possible. More about that later.
Submitting Sitemaps
Unlike the robots.txt file, which has a standardized name and default location (in the site root) and thus, is always read by search when a site is visited, Sitemaps have no standardized name or file location, so they are not read by search by default.
They need to be properly submitted to search for that to happen. You can place a reference to your Sitemap file in your robots.txt file if you wish, but the most authoritative method of submitting your Sitemap is via the Webmaster Tools of Google and Bing.
Of course, you already have search engine Webmaster Tools accounts, right? (It’s a really good idea.) Besides, the search Webmaster Tools also test and reveal any errors in your submitted Sitemap files, and that can be very helpful for optimizing your site’s indexation in search.
XML Sitemaps
The standard XML Sitemap file can use any name you choose to give it and need not be stored at the site root (although that is a reasonable place to put it). The file itself must be a UTF-8 encoded text file, which means URLs that include some special characters must use entity escaping, so the URLs in the Sitemap can be correctly parsed by search. Sitemaps can be saved in uncompressed form and presented as .XML files, or can be compressed in gzip format and presented as .GZ files.
The XML Sitemap protocol has a set of defined XML tags, some required, some optional, that allow webmasters to define a set of information about their pages, including the URL, the date the page was last modified, the expected content change frequency on the page, and the rated priority of the page relative to the other pages listed in the Sitemap.
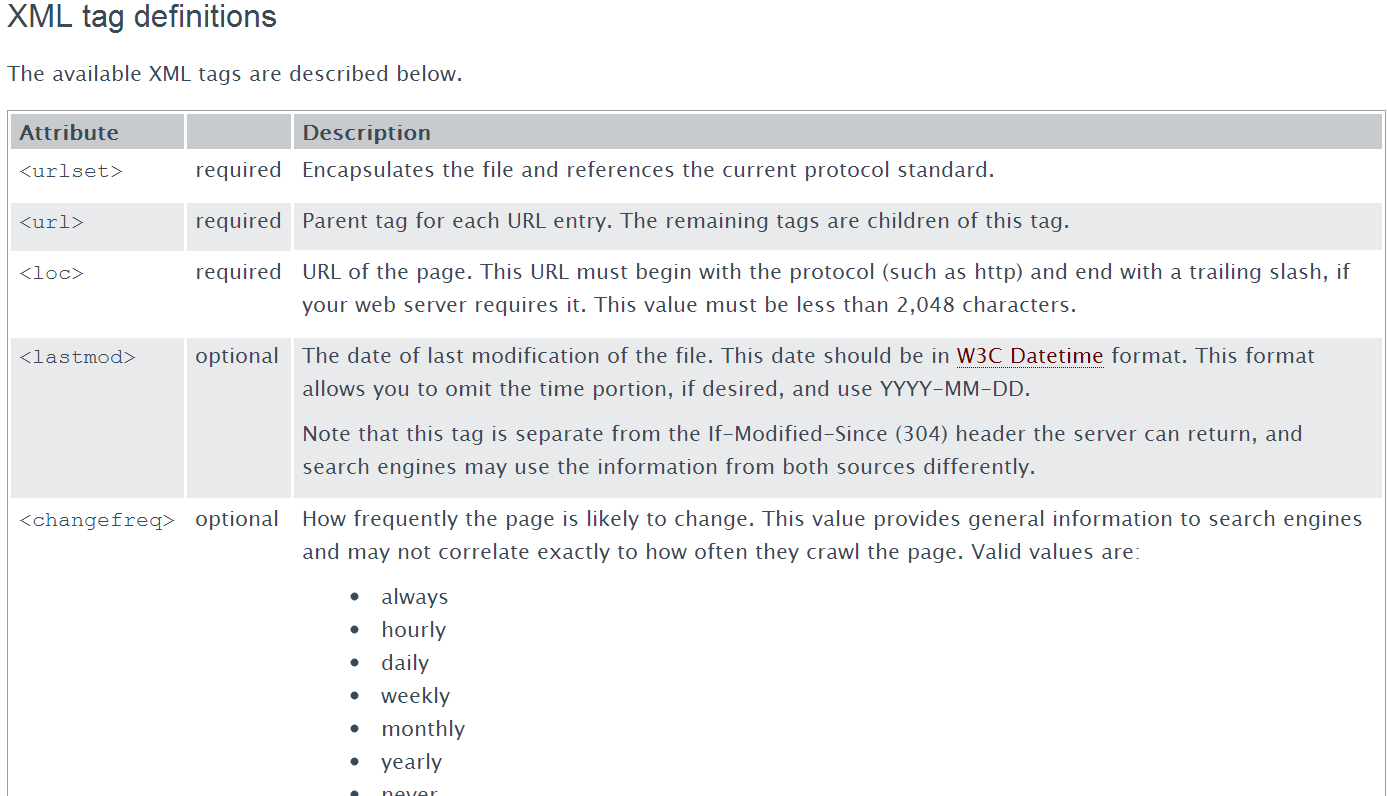
View more XML tags at Sitemaps.org
While some of the optional tags are of little value to search, I know that Bing considers the <priority> tag to be of particular value when assigning their crawler budget. This is not to say that assigning the top value, <priority>1.0</priority>, to every URL in the Sitemap will be of extra value to you. When every day is Christmas, there’s nothing special to any of it, right? Do it right and tell search which URLs in your site are the most valuable to you.
XML Sitemap files have size limitations. They can go up to 10 MB in file size or contain up to 50,000 URL entries. As this size limitation is a problem for enterprise-size sites, the Sitemap Index file is a refinement on the Sitemap XML protocol that enables one Sitemap Index file to reference the URLs of up to 50,000 separate Sitemap files, each of which can list up to 50,000 URLs, for a total possible URL identification of 2.5 billion links (that’s just big enough for most sites these days!).
XML Sitemaps feed the general Web index of the search engines (one of many indexes they maintain – more on that later). This is the most important index to feed, of course, but it’s far from the only game in town. Read on for more.
HTML Sitemaps
HTML sitemaps, aka content archives, are actual webpages that include links to all of the pages in your site. If you have a small site, you might have a one-page HTML sitemap. If your site is an enterprise publishing site, the HTML sitemap is likely designed as content archives, perhaps organized by section, then by publication date (broken out by year, month, then day).
Note that having an HTML sitemap is not a substitute for creating an XML Sitemap for your site. It is a webpage (or series of pages) on your site. Search may eventually crawl all of the links listed there (or maybe not), but it definitely doesn’t regard these pages as a feed.
One valuable aspect of an HTML sitemap is that it links to all of your published content. If you are a large news site and your pages only list the 24-48 hours of news stories, after which time those pages no longer are linked to by the active pages on the site, an XML Sitemap will supply the URL links to be crawled, but that’s not really good enough.
By also using a content archive solution, in this case, you provide at least one link in the active site to each published page. Heck, it even helps your human readers find favorite, older stories. If you don’t have an HTML sitemap content archive, consider how search engines may view your older pages when they see you don’t think they are valuable enough to link to them yourself. Not so good.
Side Note: Have you noted the capitalization difference of XML Sitemap versus HTML sitemap? This is intentional. Capitalizing the S in an XML Sitemap versus not doing so for a HTML sitemap allows users to quickly and consistently understand what is meant when the word is written. Good for you to have noticed!
RSS Feeds
Sitemaps can also be created in other formats, such as RSS feeds or Atom feeds, and it is recommended you create one, especially if your site publishes more than just a few new pages every day.
So why would you do this if you’ve already created an XML Sitemap for your site?
Ah, a good question that deserves a good answer. You see, search will typically visit your site and read your XML Sitemap file on a daily basis (more or less, especially if you consistently publish a lot of new content over time).
But, what happens to that newly published content before the next search site crawl? Not much, at least by way of the XML Sitemap. An RSS feed, however, is the perfect tool for feeding the Freshness Index of the search engines because it is read by search far more often every day. You publish, they crawl. It’s that simple.
Tips for creating your site’s RSS or Atom feeds
- Make sure it contains no more than 500 URLs or up to the last 7 days’ worth of published content links. It’s a freshness update, not your XML Sitemap, so keep it lean and fresh.
- Make sure the URL of the RSS/Atom feed does not change over time (same for your XML Sitemap, for that matter).
The use of date stamps or other incremental notations within these files can cause the URL of the feed to change each time it is generated, and search is very unforgiving about managing ever-changing file names.
News Sitemaps
If you are a blogger who writes about timely events on a regular basis, or perhaps you run a news website about your locality or specific community, you should consider creating a Google News Sitemap. The News indexes of Google and Bing are closed, meaning they don’t crawl the Web randomly looking for content. They crawl their list of approved sites that publish original content that offers value to their readers.
Now, with personalized search these days presenting Universal SERPs that display News modules at the top of the organic SERP listings for many queries, getting into the News index can be a great opportunity to increase the visibility of your content.
Note that Google and Bing don’t want your self-serving sales pitches, your random daily thoughts on street sweepers, or the like. They want valuable content that readers will want to see.
Getting into the News indexes is a bit complicated, so I refer you to start with the Google News Publishers Get Started page. Go through the technical requirements, and pay close attention to how to create a customized Google News Sitemap, which is an addition to the standard XML Sitemap protocol.
But, unlike XML Sitemap for the general Web index, you can (and in some cases, must) add metadata about the news content in the page. This data helps Google identify the relevance of the story.
I also highly recommend that if you do pursue getting into Google News, add the <meta> news keywords tag to your news story pages. Unlike the old <meta> keywords tag, which neither Google nor Bing use anymore to establish keyword relevance, the <meta> news_keywords tag is very much used by Google to establish keyword relevance for news stories (but, not by Bing, sadly).
As an example of its utility, Google cites the famous newspaper headline from the 1929 stock market crash, “Wall Street Lays an Egg” as a text string with almost no keyword relevance to its story. A Web news story using <meta> news_keywords can still use such creative titles, but also feed Google with the actual relevant keywords to help it be found in search queries.
I also recommend that you carefully consider the type of news content you publish. Google doesn’t want to see you republishing syndicated news feeds. They already have that stuff, and you’ll be rejected if your application doesn’t account for that. If your news site publishes both original/heavily edited content as well as syndicated feed content, be sure your Google News Sitemap does not include links to the feed content pages. If you get rejected, you cannot reapply to get into the Google News index for 60 days or so.
Once you have your Google News Sitemap ready, submit it to Google Webmaster Tools, and then apply for admission into the Google News Index. Your application is hand-curated by Google staff, so be careful and thorough in your preparation. The application process is a survey, and they will confirm your answers before allowing you in.
To get into Bing News, you need to send an email request to [email protected]. Your thorough preparation for Google News should help speed things along with Bing News – they even accept Google News Sitemaps! The application process can take several weeks to process (they get to it when they get to it!).
Be thorough, be patient, and if your content is worthy, your efforts will be rewarded. But note: once in, keep up the good work, or you’ll be kicked out.
Video Sitemaps
If your site publishes original video content, search wants to know about it. This is an especially hard content type to index by crawling, as the much needed metadata about the video content is not always available in the page on which it is found. Help search help you by creating a Google Video Sitemap.
Also based on the XML Sitemap protocol, the Google Video Sitemap protocol adds important metadata about each video to help it become relevant to search queries. There are many XML required tags, as well as many optional (and a few “depends”) XML tags to be filled in for each video listed.
Be sure to review the protocol specs carefully and create your video Sitemap. Once created, simply add it to your Sitemaps lists in your search engine webmaster tools accounts.
Note that Bing supports Google Video Sitemaps. Also note that both Google and Bing support media RSS (mRSS) feeds (based on RSS 2.0) for videos.
Mobile Sitemaps
If your site has created a large number of webpages dedicated to serving mobile device browsers, and you are not yet invested in responsive design (where all pages are simultaneously desktop and mobile-device ready via CSS3), then you might want to consider feeding the Google mobile index your dedicated mobile URLs with a Google Mobile Sitemap.
Like others before, the Google Mobile Sitemap is based on the XML Sitemap protocol and adds new tags, identifying listed URLs as mobile content. This one is pretty simple to implement, but note that the industry is quickly moving away from dedicated mobile URLs that duplicate the same content found in URLs for desktop browsers in search indexes, migrating quickly toward using single URLs that work visually and contextually in all presentation modes, from a widescreen desktop monitor to a smartphone.
Image Sitemaps
Google maintains a large image search index, and it is always interested in discovering more great image content. If your site is rich in images, especially original content, and your goal is to get as many of your images indexed as possible, you should consider creating a Google Image Sitemap.

Like the Mobile Sitemap above, the Image Sitemap is an add-on to the standard XML Sitemap protocol. You can publish your image information in your XML Sitemap or create a dedicated Image Sitemap and use a Sitemap Index to capture it as part of your Sitemap feeds to Google. There are only two XML tags that are required, but if you want to provide more metadata about your image content, you can do that as well.
Note that including your site’s images in an Image Sitemap will help define the most important images on your site to Google. They don’t promise to index all of the images you list in the Sitemap or include all of the extra metadata you optionally provide, but they’re more likely to do so if you provide this data in a dedicated feed. They will certainly prioritize indexing the images noted in an Image Sitemap over those not listed in your site.
The images are identified with custom XML tags in the Sitemap within the section of the source webpage’s URL. Note that you can list up to 1,000 images per URL on your site. Even if you choose not to publish an Image Sitemap, you should review Google’s image publishing guidelines to optimize image indexation from your site.
Building A Sitemap
Unless you have a very small site and you want to hand-curate your own Sitemap, you might want to think about automating your Sitemap creation.
Most content management systems (CMS) today offer some type of Sitemap creation tool, even if it’s only XML Sitemaps for the general Web index. If you are a WordPress user, there are many great plugins available for generating Sitemaps for your website.
Bing recently announced a new tool for creating XML Sitemaps for both IIS and Apache web servers. It works as an ISAPI filter by logging the URLs of all outbound pages served on a daily basis, generated by HTTP requests from both end users and third-party search crawlers. It maintains a super-clean, error-free Sitemap Index for your site, adds new differential URL updates every day, removes 404s as they appear, and runs in the background taking up very little in the way of server system resources. A full website Sitemap is generated in just a few days, and is easily maintained automatically. If you want to know more about it, check out the Bing Sitemap Plugin doc.
Learn about the many ways that Sitemaps can enhance the value of your site to search, then put them to good use. If you have great content, search wants to know about it. How much better does it get than to spoon feed the engines with your content URLs in a Sitemap?
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author