Brace yourself: The benefit and shock of analyzing Googlebot crawl spikes via log files [Case Study]
Site owners really don’t know the full story about who, or what, is crawling their sites until they analyze their server logs. Columnist Glenn Gabe shares a case study that illustrates some insights to be gleaned from a server log file analysis.

I recently started helping a site that was negatively impacted by the May 17 algorithm update. The site had been surfing the gray area of quality for a long time, surging with some quality updates, and sometimes dropping. So I started digging in via a crawl analysis and audit of the site.
Once I started analyzing the site, I noticed several strange spikes in pages crawled in the Crawl Stats report in Google Search Console (GSC). For example, Google would typically crawl about 3,000 pages per day, but the first two spikes jumped to nearly 20,000. Then two more topped 11,000.
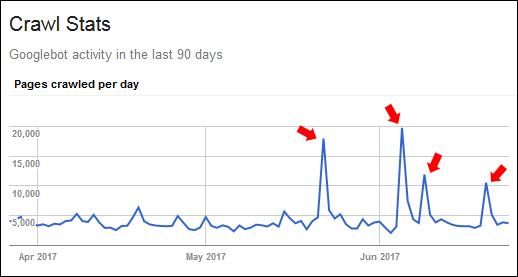
Needless to say, I was interested in finding out why those spikes occurred. Were there technical SEO problems on the site? Was there an external factor causing the spike? Or was this a Googlebot anomaly? I quickly reached out to my client about what I was seeing.
Spikes in crawling: Sometimes expected, sometimes not
I asked my client if they had implemented any large-scale changes based on my recommendations that could have triggered the spike in crawling. They hadn’t yet. Remember, I had just started helping them.
In addition, I had just completed two large-scale crawls of the site and didn’t see any strange technical SEO problems that could be leading Googlebot to crawl many additional pages or resources: coding glitches that could cause Google to crawl many near-duplicate pages, botched pagination, faceted navigation and so on. I did not find any of these problems on the site (at least based on the first set of crawls).
Now, it’s worth noting that Google can increase crawling when it sees large-scale changes on a site — for example, a site migration, a redesign or many URLs changing on the site. Google Webmaster Trends Analyst John Mueller has explained this several times.
The image below shows what that can look like. This is from a site I was helping with an https migration (not the site I’m covering in this post). Notice the spike in crawling right after the migration happened. This is totally normal:

But that’s not what happened in this situation. There were no large-scale changes on the site yet. After reviewing the situation, my decision was clear:
UNLEASH THE LOG FILES!
The power of server logs
Log files contain raw data of site activity, including visits from users and search engine bots. Using logs, you can dig into each visit and event to see which pages and resources were being crawled, the response codes returned, referrers, IP addresses and more. I was eager to take a look, given the spike in crawling.
If you’ve never dealt with log files, you should know they can get quite large. For example, it’s not unusual to see log files that are hundreds of megabytes in file size (or even larger for high-volume sites). Here is one of the log files I was working with. It’s 696MB.

Log, meet the frog
My next move was to fire up my favorite log analysis application, Screaming Frog Log Analyzer (SFLA). Most of you know the Screaming Frog Spider, which is awesome for crawling sites, but some still don’t know that Dan Sharp and his crew of amphibious SEOs have also created a killer log analyzer.
I launched SFLA and imported the logs. My client sent me the log files ranging from a few days prior to each spike to a few days after. They did this for each of the spikes I saw in the crawl stats report in Google Search Console (GSC). Now it was time to dig in. I dragged the log files to SFLA and patiently waited for them to import.

Houston, we have a problem…
When analyzing the first set of logs files, the dashboard in SFLA told an interesting story. The response codes chart showed a huge spike in 404s that Googlebot encountered. That looked to be the problem.
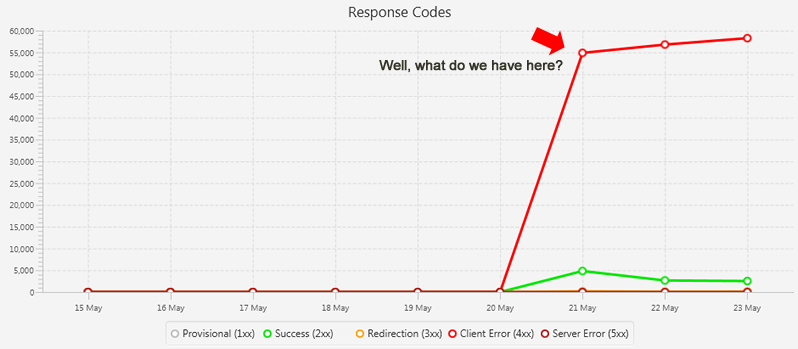
I noticed thousands of events leading to strange URLs that looked like botched pages containing videos, and my client’s site didn’t contain one of those URLs. Most of the 404s during this time period were due to the strange URLs.
But something didn’t look right about some of those “Googlebot” events. More about that next.
The plot thickens: Spoofing
I always warn people before they dig into their log files that they might see some disturbing things. Remember, the logs contain all events on the site, including all bot activity. It’s unfortunately not unusual to see many bots crawling a site to gain intel… or for more nefarious reasons.
For example, you might see crawlers trying to learn more about your site (typically from competitors). You can also see hacking attempts. For example, events from random IP addresses hammering your WordPress login page.
When you first uncover that, you might look like this:

So, here’s the rub with the spike in 404s that I surfaced from “Googlebot.” I quickly noticed many spoofed Googlebot events (from several different IP addresses). Screaming Frog Log Analyzer has a nifty “verify bots” feature that I took full advantage of.
It was interesting to know that the real Googlebot spiked during this time frame (via GSC reporting), while spoofed Googlebots were also hammering the site during that time. But I couldn’t find any verified Googlebot spikes in the log files.
So we collected and researched some of the bad-actor IPs — and saw they are NOT from Google. My client is now dealing with those IPs. That’s a smart thing to do, especially if you see returning visits from specific IPs spoofing Googlebot. We went through this process for the second spike as well.

This was a great example of lifting the hood and finding some crazy problems in your engine (or with the fuel being added to your engine). You could either close the hood in shock vowing to never look again, or you could address the problems for the long term. Sweeping the problems under the rug is never really the solution here.
Will the real Googlebot please stand up?
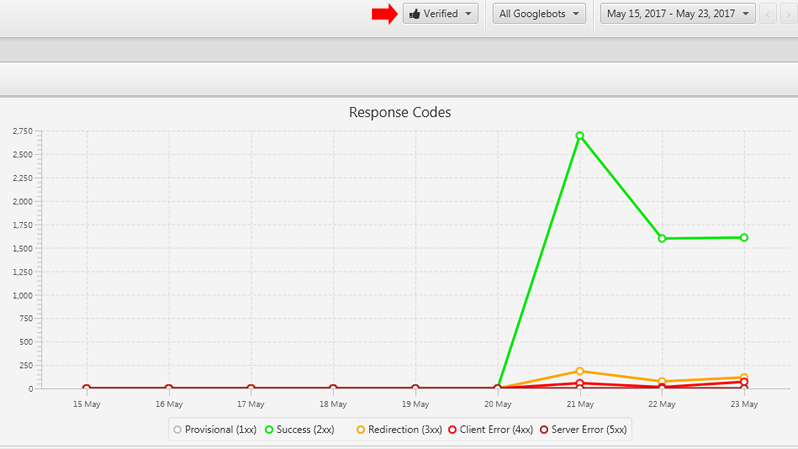
After analyzing the first two spikes, I still didn’t see any verified Googlebot problems. (I’m referring to Google actually crawling the site and not different crawlers spoofing Googlebot.) So, the crawl stats in GSC did spike, but the server logs revealed normal activity from Googlebot proper. It was the spoofed Googlebots that seemed to be causing the problem.
Check out verified Googlebot activity versus spoofed activity below:

Crawl stats return to normal, then spike again
We have been checking the crawl stats reporting in GSC often to monitor the situation (for the real Googlebot). The crawl stats returned to normal for awhile, but spiked a third and fourth time (as seen in the first screen shot I shared above). The latest spike was over 11,000 pages crawled.
Checking the logs revealed many URLs that don’t exist on the site (but not the video URLs from earlier). And these were accessed by Googlebot proper (verified). I was happy to see that we finally caught some real Googlebot problems (and not just spoofed Googlebot issues).
These URLs look completely botched and are sometimes hundreds of characters in length. It looked like a coding glitch that kept appending more characters and directories to each URL being linked to. I sent the information to my client, and they forwarded the information to their lead developer. They initially didn’t know where Google would have found those URLs. I’ll cover that next.
Googlebot and 404s: A nuanced situation for SEO
To be clear, 404s are not a problem if the pages should actually 404. Google’s John Mueller has explained this many times. 404s are completely natural on the web, and they don’t impact quality for a site.
Here’s a video of John Mueller explaining this:
And here’s a page from Google about how Googlebot could encounter 404s on a site:
That being said, both bots and people could be accessing links that lead to 404s, so that could have an impact on usability and performance. And as Mueller explained in the video, “it can make crawling a bit trickier.” Therefore, you should definitely double-check 404s and make sure they should indeed return a 404. But just having 404s doesn’t mean your site will tank from a rankings perspective, get hit by the next major algorithm update and so forth. That’s important to know.
And to state the obvious, any page that 404s will be removed from Google’s index. So that page cannot rank for the queries it was once ranking for. It’s gone, and so is the traffic it was driving. So again, just make sure pages that 404, should 404.
For example, imagine a high-volume page like the one below suddenly 404s (by mistake). As the URL falls out of the index, the site would lose all rankings for that page, including traffic, ad impressions and more.

Google also wrote an article on the Webmaster Central Blog about 404s and if they can hurt your site. Between Mueller’s comment, the support doc and the blog post, you can rest assured that 404s alone will not cause quality problems. But again, it’s important to make sure sinister, spoofed Googlebots aren’t hammering your server to try to impact uptime (and SEO long-term).
I asked my client if the site has seen any performance problems based on the crawl spikes we were seeing, and it was great to hear they hadn’t seen any problems at all. The site is running on a very powerful server and didn’t even bat an eye when “Googlebot” spiked in crawling.
How did Google find those long URLs?
After analyzing the spike in crawling to these long URLs, I could see a connection between the broken URLs and some JavaScript files. I believe Google was finding the URLs (or forming the URLs) based on the JavaScript code.
You’ll notice that Google mentions the possibility of this happening in the support documents I listed above. So if you see URLs being crawled by Google that aren’t present on your site, then Googlebot could be finding those URLs via JavaScript or other embedded content. That’s also important to know.
What we learned (and didn’t learn)
As I said earlier, digging into server logs can be both beneficial and disturbing. On the one hand, you can uncover problems that Googlebot is encountering, and then fix those issues. On the other hand, you can see sinister things, like hacking attempts, spoofed Googlebots crawling your site to gain intel, or other attempts to hammer the server.
Here are some things we learned by going through this exercise:
- We could clearly see spoofed Googlebots crawling the site, and many were hitting strange 404s. My client was able address those rogue IPs that were hammering the server.
- We saw the real Googlebot (verified) crawling what looked to be botched URLs (based on links found via JavaScript). Using this data, my client could dig into technical problems that could be yielding those long, botched URLs.
- We did not find all spikes from Googlebot that were being displayed in GSC. That was strange, and I’m not sure if that’s a reporting issue on Google’s end or something else. But again, we did find some real spikes from verified Googlebot that we addressed.
- And maybe most importantly, my client could clearly see the underbelly of SEO — for example, many spoofed Googlebots crawling a site to gain intel, or possibly for more nefarious reasons. But at least my client knows this is happening now (via data). Now they can form a plan for dealing with rogue bots if they want to.
Summary: Log files can reveal sinister problems below the surface
When you break it down, site owners really don’t know the full story about who, or what, is crawling their sites until they analyze their server logs. Google Analytics will not provide this data. You must dig into your logs to surface bots accessing your site.
So, if you ever find a spike in crawling, and you’re wondering what’s going on, don’t forget about your logs! They can be an invaluable source of data that can help uncover SEO mysteries (and possibly sinister problems that need to be addressed). Don’t be afraid to dig in to find answers. Just remember that you might need to brace yourself.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author