Facebook Graph Search: The Good, The Bad, The UGLY!
Besides covering The Good, The Bad and The Ugly, we’ll also go into The How and The What of Facebook Graph Search, which launched in January 2013. Graph Search was hardly a surprise to many of us, yet its implementation to date has been interesting. If well-understood, it can be leveraged by marketers and brands; […]
Besides covering The Good, The Bad and The Ugly, we’ll also go into The How and The What of Facebook Graph Search, which launched in January 2013.
Graph Search was hardly a surprise to many of us, yet its implementation to date has been interesting. If well-understood, it can be leveraged by marketers and brands; but, if not well-understood, it could lead to some seriously controversial (not pretty or even possibly ugly) issues.
Given that I have a background in the semantic Web field, when Facebook launched the open graph protocol with support announced for RDFa, I was very excited. I avidly followed the “ontology” (or vocabulary) they used; so, when sitting down to write this article, the first thing I did was go to one of my “ontology reader” tools, usually Protégé, and point it to where I always do, namely, Open Graph Protocol.
However, upon visiting the above link that I’d used in the past, I realized that Facebook had pulled a lot of interesting information from that resource, which now provides just attributes. (Useful in their own right.) But do note that this means that plugins like the drupal one here that references the old URL, https://opengraphprotocol.org/schema/ (not redirected) will break!
Depicted in the figure below, is a user-centric version of the Facebook Open Graph schema. To dig deeper, I used a tool called Gruff, from Franz Inc, which provides beautiful visual displays of information in graph databases. I did take several “views” of the information as there were about 804 triple sets (subject, predicate, object ) which probably form the higher level data structure from which Facebook can derive its structured/graph search.

The How: Facebook Graph Search
From the graph above, you can see very clearly what Facebook perceives/defines as what the user is interested in and also what they want to know about the user:
- TV programs they like
- Games they like
- Books they like
- Albums they have and so on and so on
Of perhaps even more interest, is that all Likes are treated the same (See figure below).
However, as I mentioned, the version of OpenGraph I obtained was prior to the January 2013 data lockdown; so, please take my statements as an educated conjecture. This is an important caveat!

If you look at the diagram above, you can see this view is portrayed with respect to the “Open Graph Object.” What this actually tells you, specifically at a higher level, is what “Open Graph Object” is interested in or cares about. Things like:
- Pages
- Users
- Posts
- Accounts
- Groups
- Message Status
- Books
- Movies
- And so on
More about Likes? You can see them graphically depicted in a lot more detail below (using Gruff once again), as predicates in the (subject, predicate, object) structure and searching on it.
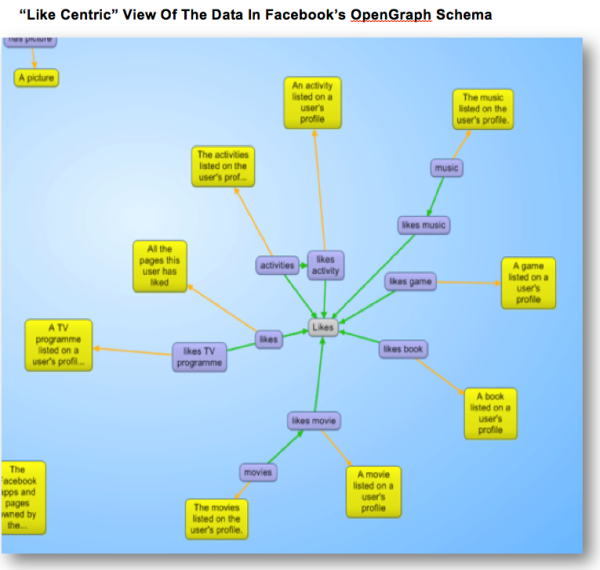
The What: Facebook Graph Search
At this point, you may be asking, what on earth has this to do with me, and in what way can it help me? For one thing, Facebook search clearly searches around its structured data types (defined above) and does this based on “Likes” or “interests,” which you can also see above. It is very clear what type of structured data they are searching on and how they are using the “Likes” and “interests”.
Understanding what the search and social engines do and what makes them happy is paramount to succeeding in any type of search or social campaign. Just as Facebook wants to make their users happy using Graph Search, understanding their intention of “making their users happy” or creating a great user experience is crucial to the success of an SEO- or SEM-oriented agency’s/individual’s goals.
Anything that furthers the goal of the search or social engines will be sure to work in an “SEO campaign” or “social campaign,” respectively. Taking this approach, you can reverse engineer whatever you want to understand/achieve online.
A Word Of Caution (The Ugly)
As you can very clearly see from the above diagrams depicting Open Graph Schema, it is very focused on “Likes” and “interests.” I have selected a couple of examples below of Actual Facebook Graph Searches taken from Tumblr. 
The example above illustrates how an organization could potentially suffer from a negative image by having their employees “Like” racism. I am sure there are those who would also run counter campaigns, for example, using Mechanical Turk with a major e-tail competitor and creating tons of Facebook accounts with employees that Like the opposite of “racism” or “equal opportunity” or whatever synonym you choose. (I could get into hot water here, so will opt out of volunteering any more synonyms).
There are several other blatant examples where Graph Search is inevitably using drill-down techniques (filters or faceted-type search) in their Graphical User Interface to leverage their structured data (as does Google) to provide relevant answers to queries.
However, there is one great difference here; there are potentially disastrous social consequences. (Even if the data is clean and scrubbed, there could be all kinds of social ramifications). I have included another example of actual Facebook Graph searches from Tumblr below, and you can find even more here.
It is clearly wonderful that both the search and social engines are striving to become answer engines and are actually succeeding. Serving up a valid answer for a search engine is clearly cool and useful. Do the social engines need an added complication? A conscience? Failures or errors in determining or creating “a conscience” clearly have long-term and long-reaching ramifications and social impact.
Last, but not least, a couple of oddities I detected in the last day or so.
Sincere thanks to Kinglsey Idehen of OpenLink Software for having both the foresight and ability to maintain backups for all this data; the lost information I retrieved is directly attributed to OpenLink Software.
Just an FYI: I seriously did look for older versions of Facebook’s OpenGraph schema online. Below you can see when all evidence was removed from the Wayback Machine! (The timeline appears to go back to August 2, 2010).
Very, very last, but not least: why on earth is Facebook putting Microdata using Google’s old ontology/vocabulary prior to schema.org on their public pages for folks who Like the pages and more? Example is illustrated below.
Summary & Takeaways!
Lots to make you go “hmmm…” In short:
- Be aware of what you personally like on Facebook.
- Try to retain the perspective (point of view) of a search or social engine if trying to optimize campaigns, pages, websites or whatever for them.
- If you make Facebook happy and you want to succeed with social engines, it will work!
- Also note the differences between Social Search and Generic Search for other types of facts.
- I believe semantic search is orthogonal to social search, and conscience is required in both, but applying the identical principals to social search as to standard search, looking for the perfect tangible object or fact is very different from a social perspective than looking for the perfect ….. ?
I would love to invite discussion on the ramifications of these issues from an SEO perspective or any other perspective!
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author