Five-Step Strategy For Solving SEO Pagination Problems
Pagination has always been a sticky problem for search engines. While not nearly as complex as faceted navigations for SEO, they can certainly cause crawling inefficiencies and excessive duplicate content. They can also create problems with undesirable pages ranking for important terms, in cases where the search engines don’t pick your preferred URL. Fundamentally, pagination […]
Pagination has always been a sticky problem for search engines. While not nearly as complex as faceted navigations for SEO, they can certainly cause crawling inefficiencies and excessive duplicate content. They can also create problems with undesirable pages ranking for important terms, in cases where the search engines don’t pick your preferred URL.
Fundamentally, pagination is an interface problem. A computer should have no problem processing hundreds (if not thousands) of items on a single URL. But people can’t read that much stuff, and long scrolling pages can be a poor user experience.
Here’s where user experience and search engines have a face off, and the user wins: enter pagination.
Historically, we have handled this problem several different ways. Like so much with SEO, the specific implementation depends on a number of factors. We typically use a combination of the following tools:
- rel=”canonical” tags
- meta robots noindex
- parameter handling tools
- robots.txt (rarely, it’s a sledgehammer)
- making pages unique (title, meta description, URL)
Today we can add to this toolset:
- rel=”next”, rel=”prev”
One area that has changed recently is our understanding (through testing, and messaging from Google) of how crawlers interact with pages tagged with rel canonical. Quoting from my article about Maximizing SEO Product Visibility,
“We have traditionally operated on the assumption that URLs annotated with rel canonical wouldn’t be fully crawled. In other words, links within pages wouldn’t be followed, anchor text and PageRank would not be passed, and the URL would simply be ‘soft 301’d’ to its canonical target. However, that may change based on the latest information from Matt Cutts. …
“Cutts recently said that links on pages annotated with rel canonical would still be crawled, based on the overall PageRank of the URL, among other factors. From this information, it appears rel canonical is a totally separate (i.e., distinct) process from crawling. …
“There is a fairly big ramification of this in how pagination is treated. Our methods for handling it typically employ ‘noindex, follow’ on paginated URLs (2, 3, 4, etc.), and no use of rel canonical except to self-reference in cases of duplicate URLs; certainly, no use of rel canonical to reference page 1, since that would prevent links on deeper pages to get crawled.”
No doubt some of that may now change with the introduction of rel next and prev. In fact, we’ve already begun testing use of rel canonical in concert with meta noindex.
Background On SEO & Pagination
Issues with pagination seem to occur most frequently on e-commerce sites, although the problem can pop up on publishing and information sites, too. Typically, we recommended companies default to their “View All” page for visitors. We’ve seen time and again that customers shopping online want to see all the inventory in front of them, at once.
This is why well-crafted search result pages perform so strongly and usually have a conversion rate that surpasses category landing pages with copy, images and more formalized layout. I was happy to see Google echo this advice recently when they announced their preference for View All pages in search results.
However, clients don’t always like this recommendation. First, it can cause latency, especially on large sites with hundreds (if not thousands) of products or items in a category. Second, merchandising and political interests are at play.
Having control over which products are featured on a category are important to these folks, and in some ways, the “View All” takes away this control, making it more of a level playing field for the products rendered. As always with SEO, the business needs take precedence, and recommendations must be catered to the specific situation.
Our Approach For SEO Pagination Problems
Now that rel=next and rel=prev are supported (which is awesome), our testing has begun. We don’t yet know how well this is working, but we will soon. In the meantime, we’re continuing to recommend the following strategy:
- Create a View All page (it isn’t necessary to make this the default view)
- Link to the View All from category- and product-level URLs. Messaging can be simple, something such as “view all products.”
- Here’s where we differ from Google: add a “meta noindex, follow” to the View All and all the pagination URLs. This effectively pulls them from the indices. (Note: We may revisit this strategy and modify it based on the success of rel next/prev and Google’s desire to feature View All URLs in their indices.) Additionally, add rel=”canonical” annotations to these URLs.
- Ensure paginated URLs are made unique: URL, page title and meta description. Why? Because this helps differentiate them and send quality signals. Google should then give more weight to the pages (and their links) if not only the content (e.g. the products listed) is unique, but also the structure of the pages.
- Add the View All and the paginated URLs to your XML sitemaps to ensure crawling. These can be removed after a period of time.
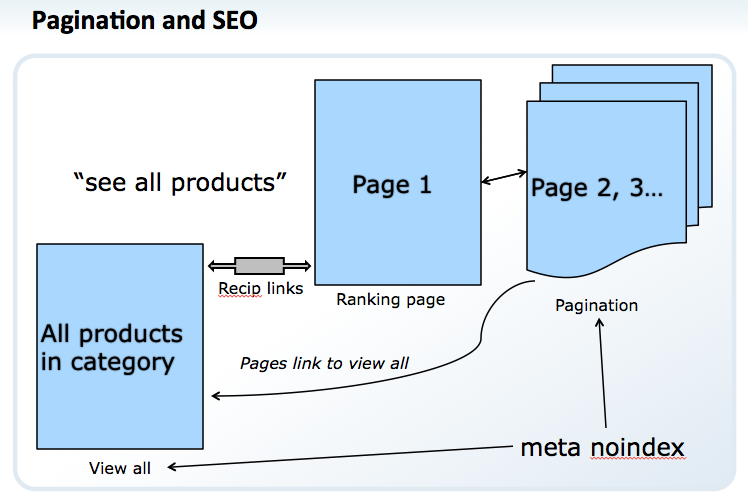
Our SEO solution for pagination, category and product level.
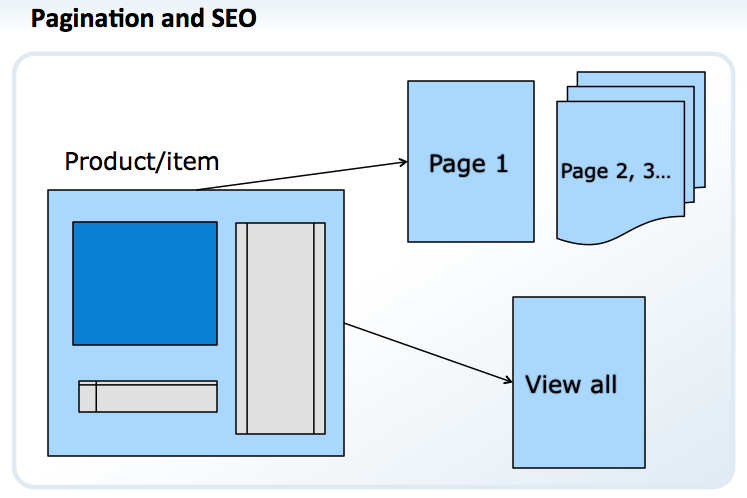
Our SEO solution for pagination, product or item level.
This has worked very well for our clients. The result is that the default category URL (in essence, page 1) ends up ranking best for its targeted terms. Potential duplication is solved, and extra pages are removed from the indices, keeping things clean.
There are potential downsides, too. For one, pages annotated with meta noindex still need to be crawled, so it does nothing for crawl efficiency on very large sites. The second problem is that, with rel next/prev, this strategy (while successful so far) probably will need a refresh.
Finally, there is some concern that using meta noindex and rel=”canonica”l in tandem could cause issues, since the two signals are technically in conflict. Meta rel canonical says, “Soft 301 this to the canonical version and pass all scoring factors.” Meta noindex says, “Crawl this but don’t feature it in search results.”
However, judging by Cutts’ recent comments, those processes are actually separate and distinct. Therefore, they shouldn’t be in conflict. We’ll keep testing.
What are you seeing out there? I look forward to your comments and experiences.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author