George Washington Did What According To Wikipedia???
Many have joked about how Wikipedia seems to rank at the top of practically any Google search that you do. Often, that’s a good thing, as Wikipedia has lots of great information. But a search on george washington today shows a downside. Someone edited the start of the Wikipedia entry about the first US president […]
Many have joked about how Wikipedia seems to rank at the top of practically any Google search that you do. Often, that’s a good thing, as Wikipedia has lots of great information. But a search on george washington today shows a downside. Someone edited the start of the Wikipedia entry about the first US president to be less than flattering. Google spidered the entry, and that material was used to form the description of Washington’s Wikipedia page, as shown below. Look at the second listing:
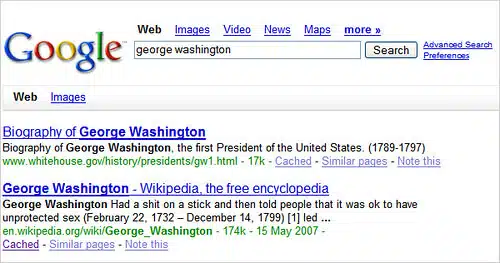
It’s embarrassing for Google, but the fault really lies with Wikipedia, since this text stayed on Washington’s page long enough for Google to catch it. Indeed, it looks to have been on the page for at least a day. It’s gone now, but when I looked about a half hour ago, the text was still there. It will probably take about another day for the description to fall out of Google itself, once the page is recrawled.
FYI, the description does not show at Yahoo or Ask.com because Wikipedia is not in the top result for a search on George Washington there. At Live.com, the Wikipedia page shows but was last visited on May 13, before the insulting text was added.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author