Google Continues To Experiment & Expand Authorship
If one theme was abundantly clear at SMX West in March, it was the question over the importance of authorship and how it might impact future rankings in Google. During the “What’s Needed For SEO Success In 2013 & Beyond?” panel, I asked Matt Cutts if Google planned to expand authorship credit (and potentially the […]
If one theme was abundantly clear at SMX West in March, it was the question over the importance of authorship and how it might impact future rankings in Google.
During the “What’s Needed For SEO Success In 2013 & Beyond?” panel, I asked Matt Cutts if Google planned to expand authorship credit (and potentially the rich snippet) beyond just written content (like blog posts) and begin incorporating other content types.
In reality, content creators could truly author various types of content, including photos for photographers or video for videographers. Just because a piece of content isn’t part of the written medium doesn’t mean that content has no author.
Matt indicated that while the majority of content that Google sees on the Web is written, there are clearly other types of content Google indexes and wants to be able to understand authorship for.
Google is certainly doing its part to infer authorship of content, even when authorship markup has not been applied to a particular page. Over the past six months, there have been several examples of Google erroneously crediting the wrong authors with content, such as when a New York Times article credited Truman Capote with a new article, even though Capote has been deceased for nearly 30 years.
Google has even inferred authorship over other types of semantic markup on the page. On my own site, our archived webinar pages, which are coded with video schema and previously were displaying a video rich snippet, suddenly reverted to authorship instead, even though the page was not coded with author data:
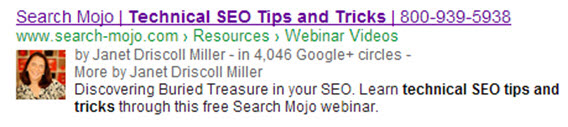
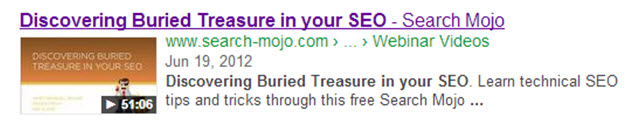
After reviewing the page copy, we realized that this video page contained the words “presented by Janet Driscoll Miller.” Could the word “by” be causing Google to infer that particular line was a byline? We reworded the content of the page, removing the phrase, and waited for Google to re-index the page. Low and behold, Google then returned the rich snippet to a video thumbnail:
A few weeks ago, we also started seeing authorship and video snippets combined on a result:
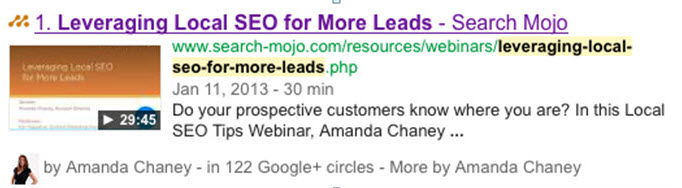
This page contains the word “by” and is also coded with video schema, so it appears that Google is recognizing both in this result. In a recent blog post, Ann Smarty also recognized a similar pattern with the word “by” even in cases where she was not listed as the author, but rather, the editor.
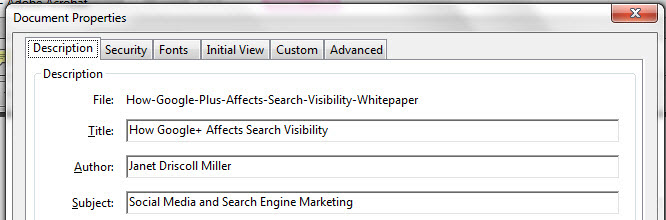
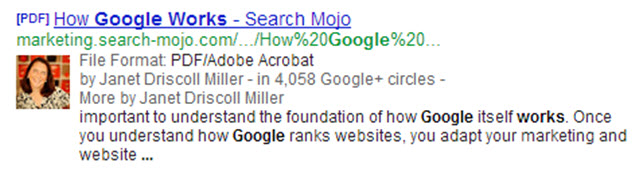
It also now appears that Google has extended authorship to content in PDFs, as well:

This PDF file data lists me both as the author in the file’s meta data, and the cover page of the whitepaper contains the phrase “written by Janet Driscoll Miller.”
So, which does Google seem to be relying on to infer authorship for a PDF – the PDF meta data or the PDF content itself or both? I tested this with an older PDF I had on hand that lists me as the author in the meta data but also lists the author as “written by Search Mojo” in the PDF body copy, therefore not showing an individual author. The meta data authorship alone did not cause Google to generate an author snippet:

However, testing a PDF with the body copy showing a byline with an actual author but where the author meta data from the PDF was blank did yield an author snippet:
So, it appears at this point, Google continues to rely on the content within the body copy, both in PDFs and other website pages, looking for a written byline with an author listed.
In the case where there are two authors listed on a PDF, Google appears to use the first author listed:

So, if you’re prepping content either in PDF or HTML, note that Google is inferring authorship through identifying the word “by” followed by an author name, and you should be cognizant of how you use this combination in your content. Otherwise, you may generate authorship without intending to or Google may accidentally infer authorship that is not correct.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author