Google Hits Mozilla With Spam Penalty Over User Generated Content
Have user generated content on your site? Pay attention to what those users are doing. That’s the takeaway from Google hitting Mozilla with a spam penalty this week, along with another takeaway. Despite Google’s saying it’s being more transparent about spam actions, people clearly find it hard to know what they’re in trouble for. Mozilla […]
 Have user generated content on your site? Pay attention to what those users are doing. That’s the takeaway from Google hitting Mozilla with a spam penalty this week, along with another takeaway. Despite Google’s saying it’s being more transparent about spam actions, people clearly find it hard to know what they’re in trouble for.
Have user generated content on your site? Pay attention to what those users are doing. That’s the takeaway from Google hitting Mozilla with a spam penalty this week, along with another takeaway. Despite Google’s saying it’s being more transparent about spam actions, people clearly find it hard to know what they’re in trouble for.
Mozilla Gets A Penalty
Search Engine Roundtable spotted the latest flare-up in Google’s fight against spam. Chris More, the Web production manager for Mozilla, took to Google’s forums for help in dealing with the penalty notice he received. From his post:
We got this message from Google and I have verified it in the webmaster tools:
Google has detected user-generated spam on your site. Typically, this kind of spam is found on forum pages, guestbook pages, or in user profiles.
As a result, Google has applied a manual spam action to your site.
I am unable to find any spam on https://www.mozilla.org. I have tried a site:www.mozilla.org [spam terms] and nothing is showing up on the domain. I did find a spammy page on a old version of the website, but that is 301 redirected to an archive website.
Has anyone had luck finding out what pages Google feels contain user-generated spam? We don’t even have a database on www.mozilla.org to allow the creation of user-generated content!
Hunting To Know What You Did Wrong
About 12 hours after his post, More got an answer from Google webmaster trends analyst John Mueller. Mueller’s position involves outreach to webmasters on a range of Google search issues. He wrote:
To some extent, we will manually remove any particularly egregious spam from our search results that we find, so some of those pages may not be directly visible in Google’s web-search anymore.
In summary, Google told Mozilla that it has some type of spam issue that was so bad as to generate a penalty. But, Google didn’t explain what exactly this spam was, so that it could be easily removed. Worse, Google may have already removed some of the spam from its own listings, so that a publisher like Mozilla can’t even locate it using Google search.
Not only does this sound crazy, but it also sounds familiar. Last month, the BBC received a similar warning, one about having unnatural links. A puzzled BBC rep took to the forums to ask for help, since the message didn’t explain more in detail and the site has so much content. Eventually, Mueller answered that the warning came from having one single page that was deemed having unnatural links pointing at it and that “granular” action was taken.
A “Granular” Penalty
Granular action? That’s similar to what Mueller wrote at the end of his response to Mozilla:
Keep in mind that we work to be as granular as possible with our manual actions. Personally, I think it’s good to react to a message like that by looking into ways of catching and resolving the cases that get through your existing UGC infrastructure, but in this particular case, this message does not mean that your site on a whole is critically negatively affected in our search results.
In other words, all of Mozilla hasn’t been penalized — only specific parts. It could be a single page. It could be a range of pages. While that sounds reassuring, that the entire site wasn’t hit, the uncertainty over just how much or little was “granularly” effected adds a whole new worry.
Figuring Out What’s Wrong
How to solve the problem? With a manual penalty (versus an algorithmic one), ideally, you have to remove the bad stuff and file a reconsideration request. But, since the manual action notice didn’t say what was wrong, the publisher has to play detective.
In the past, Google was wary about giving details about penalties, because it didn’t want to help spammers know exactly what they did wrong, lest they figure out a way to trick Google without getting caught. But lately, the company has talking about being clearer. Last October, it said that it would share some examples of “unnatural” links that were spotted, when a warning notice went out.
When I spoke with Google’s Jake Hubert earlier this month during his keynote at our SMX Munich conference, I asked about this greater move to transparency that Google’s been talking about. Hubert’s been a big part of that, having been instrumental in creating Google’s new How Search Works area, which includes live examples of spam that’s been removed.
Hubert said that if people file a reconsideration request, they should “get a clear answer” about what’s wrong. There’s a bit of a Catch-22 there. How can you file a reconsideration request showing you’ve removed the bad stuff, if the only way you can get a clear answer about the bad stuff to remove is to file a reconsideration request?
The answer is that technically, you can request reconsideration without removing anything. The form doesn’t actually require you to remove bad stuff. That’s just the general advice you’ll often hear Google say, when it comes to making such a request. That’s also good advice if you do know what’s wrong.
But if you’re confused and need more advice, you can file the form asking for specifics about what needs to be removed. Then have patience. Officially, a response might take several weeks.
Protecting Yourself From Bad UGC
Back to Mozilla, it got help initially from non-Google people on the forum, then Google’s Mueller gave some greater guidance, saying:
I see some pages similar to those that Pelagic (thanks!) mentioned: https://www.google.
com/search?q=site:mozilla.org+ cheap+payday+seo (you’ll usually also find them with pharmaceutical brand-names among other terms). In addition to the add-ons, there are a few blogs hosted on mozilla.org that appear to have little or no moderation on the comments, for example https://blog.mozilla.
org/respindola/about/ looks particularly bad. For these kinds of sites, it may make sense to allow the community to help with comment moderation (e.g., allow them to flag or vote-down spam), and to use the rel=nofollow link microformat to let search engines know that you don’t endorse the links in those unmoderated comments. More tips on handling UGC (and I realize you all probably have a lot of experience in this already) are at: https://support.google.com/
webmasters/bin/answer.py?hl= en&answer=81749
The disappointing thing here is that Mozilla seems to be doing exactly what Google advises to do to avoid problems with comment spam hurting the site. As Dave Naylor noted in the help discussion, Mozilla is using “nofollow” around links in those comments, a mechanism where the links pass along no ranking benefit.
For example, you can see in this post from last year, about Firefox getting new security features, how the comments are loaded with spam:
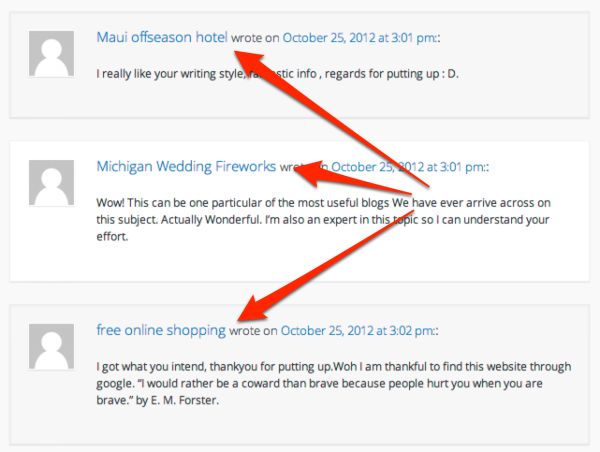
Either there are some terrible parents out there naming their children “Maui Offseason Hotel” and “Free Online Shopping” or someone’s using those names, which link back to websites, in hopes that the links will help the sites rank better.
That’s where nofollow comes in. If you look at the code, you can see that Mozilla is adding the nofollow attribute to these links, which should put it in the clear:

About the only issue I see is that it actually does this as:
rel=”nofollow external”
rather than
rel=”nofollow”
But that really makes no difference. The rel attribute can have multiple values, as Google itself shows on its page about nofollow.
Bottom line, make sure you’re screening your user generated content, and especially be sure you’re adding nofollow to any link you don’t want your site to personally vouch for. Despite the situation with Mozilla, that remains the best defense you have.
Postscript: See our follow-up story, Google: That Mozilla Penalty Only Impacted One Page Out Of 22 Million
Related Articles
- Q&A With Google’s Matt Cutts On How To Use The Link Disavow Tool
- Google Now Reports “Practically 100%” Of Manual Actions
- Google Releases Interactive Infographic: “How Search Works”
- Google Now Shows Live Examples Of Spam Removed From Its Search Results
- Google Sends BBC News A Manual Link Penalty Notification
- Google Penalized One Article On BBC’s Web Site
- Google: Adding Too Many Pages Too Quickly May Flag A Site To Be Reviewed Manually
- How Google’s Disavow Links Tool Can Remove Penalties
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author