Google Warning Against Letting Your Search Results Get Indexed
The days of doing a Google search that brings up results leading to search results from other sites are heading for a close. Matt Cutts, in his Search Results In Search Results post today, points out a change to Google’s guidelines that shows a crackdown on this type of material may begin. More about what I’m talking about below, […]
The days of doing a Google search that brings up results leading to search results from other sites are heading for a close. Matt Cutts, in his
Search Results In Search Results post today, points out a change to Google’s guidelines that shows a crackdown on this type of material may begin. More about what I’m talking about below, plus the question of whether Google should do the same with paid listings.
Over time, more and more pages seem to show up in Google search results that are merely lists of search results from those sites. To illustrate this,
consider a search for dvd players:
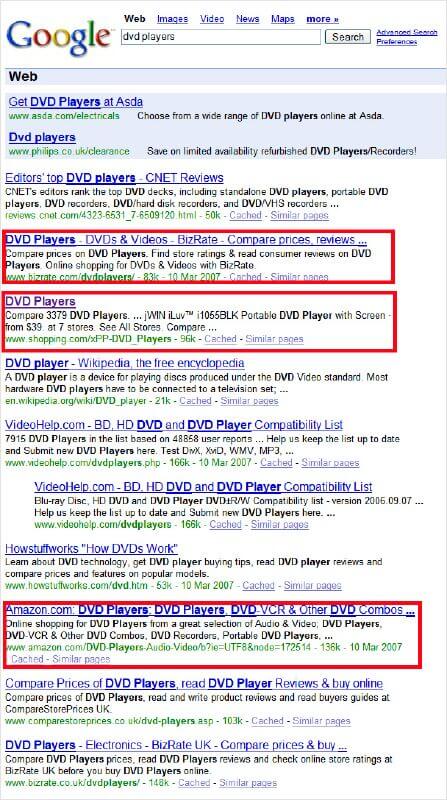
In the screenshot above, you can see links to BizRate, Shopping.com and Amazon that I’ve outlined in red. Each of those pages has one thing in common. The “content” is simply a list of all the DVD players they currently have for sale.
Matt’s post suggests that Google’s going to take a harder line against picking up content like this — that material that is nothing but a bunch of
search results. The new Google guidelines on inclusion of search results content say:
Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.
Does failing to do this mean your pages will get pulled? Well, this is a “technical guidelines” of the type designed to help site owners understand how
to get indexed. In contrast, there are also “quality guidelines” where Google spells out stuff that will get you removed. Both types of guidelines are listed on the overall Webmaster Guidelines page. But while this material may not have been put under the quality guidelines, the tone of Matt’s post plus his statement there:
It’s still good to clarify that Google does reserve the right to take action to reduce search results (and proxied copies of websites) in our own search results.
Pretty much tells me it’s not something Google wants people doing anymore.
Now let me start on how you might comply with the new guideline, and the difficulty with it in some cases, beginning with Google itself. At Google, when you do a search, the URL changes to something like this:
See the parts in bold? All searches at Google go in the /search area. It’s not actually a physical area at Google. There is no “/search” directory on
the server holding all these answers. It’s simply something Google does to make it easier to track search queries. The query terms themselves are shown after the “q=” part.
In general, these queries would never show up in any search engine results, not even Google. That’s because search engines don’t come to search boxes and start entering words randomly. They follow links. So the only way they get to a page of search results is if there’s a link that will generate them.
Oops! The example above is a link that generates search results. That’s why Google prevents the page from being indexed by doing this in its
robots.txt file:
User-agent: *
Disallow: /search
The part in bold says that nothing in the /search area should get spidered. The first line makes this applicable to all search engines.
Now let’s look at Search Engine Land. You can search here, too. When you do, the search looks like this:
Practically no one links to our search results. But now thanks to the new Google guidelines, out of the blue, I have to go block off the /fastsearch area
or potentially be seen as spamming Google. What a pain. It’s especially a pain because as I said, practically no one links to our search results. Google’s
pretty much not spidering them, but now I’ve got more work to do — albeit not a lot.
Let’s get more complicated. Remember Shopping.com? If you do a search for DVD players over there, the URL looks something like this:
To stay on Google’s good side, the /xFS area needs to be blocked off. However, that area isn’t what’s showing up currently in Google. Instead, this is
Now technically, that’s a page within Shopping.com, not a search query that’s been issued. No one did a keyword search to make the page appear. It’s not a “search results page” triggered by an actual search. Still, it’s basically the same thing. That page brings back the same information than an actual
“query-created” page does. So does it have to go? And if so, it raises a bunch of questions I’ve been meaning to revisit, such as can you do a robots.txt file that matches only the first few characters of a page name (with Shopping.com, you’d need to wipe out any “xpp-” prefixed pages).
How about BizRate? Do a search there for dvd players, and you get the same URL as in Google:
So unlike Shopping.com, there’s no difference between the URL driven by an actual query and the one that Google found by crawling (in other cases, such as “sony dvd players,” BizRate does use a more query-constructed URL).
That leads me to the next point. When I say “found by crawling,” I’m talking about the fact that lots of sites have wizened up over the years to embed lots of links on their sites that generate search results as I’ve illustrated above. Shopping.com, BizRate, Amazon — those are examples of companies that have ensured their search results can be crawlable. Back in 2005, Chris Pirillo demonstrated such savvy when making sure that any search on the Gada.be (now TagJag) got turned into a crawlable subdirectory. That got him banned, then restored.
I’ve long expected that these sites were playing a losing game with Google and the other major search engines, in that this type of material indeed
sometimes adds little value to searchers. If Google runs its own shopping search engine, as it does — Froogle — why wouldn’t I do a Froogle search. More to the point, it makes much more sense for Google to give me shopping search results from Froogle than from a bunch of assorted other shopping search engines.
There are some arguments against this, of course. First — that Google shouldn’t favor its own shopping product over others. Cutting out search results
from rivals could be seen as Google shoring up its own business prospects. Second, Froogle can suck at times (and so can the rivals, of course). Only
showing Froogle results could mean searchers at Google get less results or representation.
My feeling is that at its core, Froogle is a better way to seek products than Google. It scans across a variety of merchants, so it makes sense to be for
Google to be pointing there. If Best Buy has a good price, I don’t want to have to search Google to get to Shopping.com to get to Best Buy. I should be able to search at Google, have it kick in Froogle results if they’re appropriate automatically, and get me to Best Buy faster.
The complication is that in other areas, Google doesn’t have a good vertical search product. So on a travel search, does it make sense for “search query” results to go away?
Another complication is that Google is not saying that product pages themselves have to go away. Let’s go back to Shopping.com. Here’s a page about the Panasonic DMR-ES45VS DVD recorder. Does that get blocked off? Arguably, no — since it does explain what the product is, can connect you
to more details and consumer reviews, along with buying guides. Then again, when you see this at the bottom of the page:
 That makes it hard to work up a lot of sympathy that the aim of this page is to inform people about this product and rather than just to get found on Google and other search engines. Plus, it does contain search results (and paid listings as well), making the quality in light of the guideline changes harder to assess.
That makes it hard to work up a lot of sympathy that the aim of this page is to inform people about this product and rather than just to get found on Google and other search engines. Plus, it does contain search results (and paid listings as well), making the quality in light of the guideline changes harder to assess.
With an Amazon product page, like this one, the argument in favor of it staying in Google is much stronger. Amazon isn’t a shopping search engine but more a merchant — you can buy this directly from them. And it’s a good page describing the product, with lots of consumer reviews (over 70 of them).
The new policy also impacts what are known as “scraper” sites, those sites that simply use automated tools to get back matching search results from Google or other search engines as “content fodder” where a bunch of ads (usually from Google) get shoved at the top of the page. Google made changes to its ad system last year to try and make these types of sites less lucrative for those running them. Now the new editorial guidelines give Google more teeth to yank the sites out of search results. And few people are going to be upset about that loss.
In contrast, the new policy is a can of worms that’s been opened for shopping and other sites that have learned to turn product search results into crawlable content. At the moment, I think we’re in watch-and-see mode as to how aggressively or selectively Google applies removal. If you’re concerned, start looking at your robots.txt files now. If you’re a long-term thinker, understand the writing is clearly on the wall for sites that pretty knowingly have milked their search results to pull in Google traffic. Start planning something new. I’ll also revisit this after we get some inevitable discussion and questions raised, to see about more clarity when the dust settles.
I’ll also close with this. If listing a bunch of search results is bad for the organic/editorial listings, they also should be bad for the paid listings.
Everything I showed above, where a link brings you to product search results? The same thing happens in paid search results. Shouldn’t those go as well? And if not, the crackdown on editorial results will inevitably raise complaints the move is being done to shore up ads.
NOTE: If you saw a malware warning on Jan. 31, 2009, this was due to an error that briefly impacted all web sites. See Google Gets Fearful, Flags Entire Internet As Malware Briefly, for more.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author