How To Build Your Own Enterprise SEO Datastore
I hereby swear to not use the phrase “big data” again in this post. Enterprise SEO is all about the data. More accurately, it’s all about data storage. If you can look back over a year, pull out different metrics and see which ones correlate to success, you’re one step closer to repeating that success. […]
I hereby swear to not use the phrase “big data” again in this post.
Enterprise SEO is all about the data. More accurately, it’s all about data storage.

If you can look back over a year, pull out different metrics and see which ones correlate to success, you’re one step closer to repeating that success. If you realize at the end of the year it would’ve been realllllly nice to know page speed numbers across the whole site, well, you’re sunk.
So why are so many ‘big players’ still using Excel as their main data storage tool?
Portent’s not exactly ‘enterprise’ scale, but we store a lot of information for a lot of different clients. Sometimes, we even need to retrieve it. So here’s the solution I’ve built, in broad terms.
- It cost a total of $5,000 to set up; that includes my time
- It costs $100/month to host
- I only touch it if I need the data
- For the basic stuff, it uses Excel as the front end
If you want me to get more detailed, I can write future columns on each individual component.
The Requirements
I built this tool myself. I know, I’m a CEO; I’m not supposed to do this kind of thing. But I’m also a geek, and this was a hell of a lot of fun. Here were the requirements I wrote down when I started:
- Can store and retrieve hundreds of millions of records, without causing server meltdowns
- Allows easy Excel import
- Built on technology I already know: Python, LINUX, MySQL and/or MongoDB
- Keep different clients’ data separate
- But allow global analysis across all clients, if desired
- Never make me cry
Thus armed, I got to work.
The Servers
If you care about this kind of stuff: I’m running this system on two Ubuntu LINUX servers. One server runs the Python code and MySQL database (which is quite small, see the next section). The other runs MongoDB. If we ever hit the point where we need more oomph, we’ll spread MongoDB across multiple servers. It’s good at that.
The Database(s)
I ended up using a hybrid: MySQL stores the usual client stuff, like account names, site addresses and such. This kind of dataset won’t grow too large, and one client will only have so many websites, and it benefits from using MySQL’s relational structure.
MongoDB stores things like daily/hourly Facebook data, Google Analytics exports and the kind of stuff that just keeps growing. Why? Because MongoDB is a ‘NoSQL’ database. It stores everything in a flattened list-type format. That makes it a bit speedier for straight-up requests like “Show me all of the visitors, by day, for www.mysite.com, since 2011.”
Here’s a really basic look at the structure:

That’s not a database layout. It just shows how the two databases ‘talk’ to each other: MySQL stores the information used to access and retrieve data. MongoDB actually stores the data itself. MongoDB actually has about 30 different collections (in NoSQL, they call ‘tables’ collections, instead, just to be different) at the moment.
The beauty of the NoSQL system is that we can add fields and collections as needed, without screwing up the previous data. I won’t even try to explain why – I’m too much of a noob. Just keep in mind that NoSQL = lots of flexibility. Which can be a good or bad thing.
The Code
Then came the hard part: I had to actually get the data from each source and into my database.
Working with some APIs is a cinch. For example, pulling in data from Twitter was relatively easy. Here’s a quick example in Python. It grabs my account information from Twitter and prints it:
import twitter
import time
wait_period = 3600
screen_name = ‘portentint’ # that’s me
# you’ll need to get these by creating a Twitter API account
CONSUMER_KEY = ”
CONSUMER_SECRET = ”
ACCESS_TOKEN = ”
ACCESS_SECRET = ”
t = twitter.Api(consumer_key = CONSUMER_KEY, consumer_secret = CONSUMER_SECRET, access_token_key = ACCESS_TOKEN, access_token_secret = ACCESS_SECRET)
response = t.GetUser(screen_name)
try:
print response # response is in JSON. Since I’m using MongoDB, I can just dump it into the database
except twitter.TwitterError, e:
error = str(e)
if error == ‘Rate limit exceeded. Clients may not make more than 350 requests per hour.’:
print “Rate limit exceeded. Waiting for the next hour.”
time.sleep(wait_period)
else:
print str(e)
Code like this powers the entire tool. The Facebook code is more complicated. The Google Analytics code is more complicated still. But other tools, like SEMRush, were far easier. And, once they’re built, you set ’em to run and let them do their jobs.
The key is to build the data collection tools you can now, and start collecting that data now. Don’t wait until you have ‘every metric’ collected and stored, because there’s always a new metric, or a new API. You’ll never launch. Only used storage is useful.
Making It All Work
I thought about building a big, fancy-schmancy reporting tool, but realized I’ve already got one: Excel.
Microsoft Excel has a cool but almost undocumented tool called Web Query. With it, you can directly import a comma- or tab-delimited file into your spreadsheet.
- Create a script that generates and prints a comma- or tab-delimited file with the data you want. Test it! Make sure it’s generating the output you need.
- Create a text file. Use the template below as your guide.
- In Excel, click Data > Get External Data > Run Saved Query.
- Choose the file you created.
The template:
WEB
1
[web address of script that generates your delimited file ]
Formatting=none
PreFormattedTextToColumns=True
ConsecutiveDelimitersAsOne=True
SingleBlockTextImport=False
DisableDateRecognition=False
DisableRedirections=False
After a minute or two, your data will appear in the spreadsheet. You can format it, generate graphs, etc., as needed. The best part is, you only have to do it once.
To update your data, you can open the Excel sheet and click Data > Refresh. It’ll update your sheet, and add any new rows.
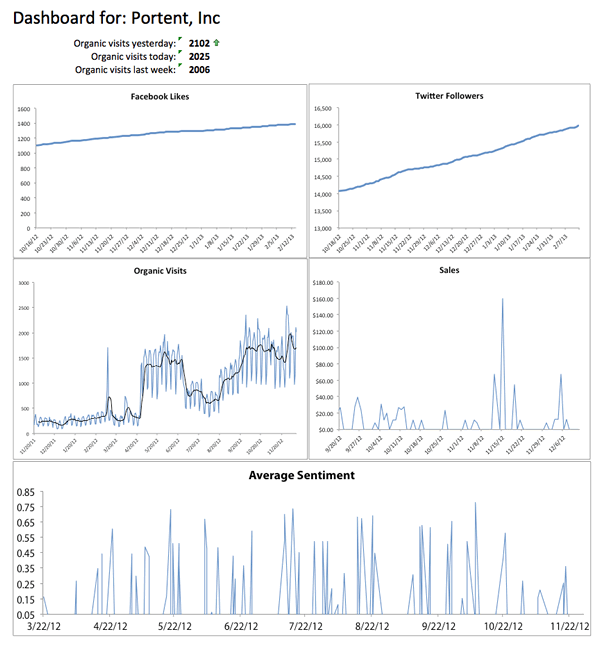
Here’s a very simple dashboard I use for Portent:
Security
If you’re in an organization where security matters a lot, you don’t want to be shooting delimited files around the Web willy-nilly. Someone in IT will definitely come knocking.
At Portent, we generate random keys that have to be included in the Web query template. The server checks for the result and makes sure it matches our key generator. If it doesn’t, you can’t grab any data.
That’s pretty basic — you can get fancier. But, it prevents any accidental data dumps.
Other Stuff To Think About
Other things we’ve tested with this kind of quick-and-dirty data warehouse include:
- Grabbing catalog sales data for cross-channel analysis
- Scaling to a lot more records (billions) – it gets ugly
- Grabbing seemingly random data, like weather, to check for sales drivers
- Importing SalesForce leads information
The possibilities are endless. The point is to start now.
What You Don’t See Can Make You Awesome
The dashboard is pretty. But, the real power in this approach is that we have a lot of data at our fingertips for comparison. With a few custom queries, we can compare things like:
- Sentiment and use of images in Facebook posts
- Organic visits and Twitter followers
- Instances of duplicate content and organic visits
- Instances of duplicate content and site performance
- Adwords quality score and bid cost
…
You get the idea.
Yes, noodling around with things like Python and LINUX can be a bit spooky. Do it anyway.
A few days’ of effort gives us access to piles of great data, for years. While the dashboard is cool, the ability to research and measure across lots of different channels is better. And, never having to tell your boss, “We weren’t recording that data,” is priceless.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author