SEO Nightmare: When NoIndex Goes Bad
Columnist Eric Enge discusses common issues that arise from improper implementation of the noindex tag.

In the right time and place, the noindex tag can be a wonderful thing. Unfortunately, there are times where it can cause problems.
Over the past few years, I have had the chance to work on a number of sites with page counts running into the hundreds of millions. The reasons why people allow their sites to grow to such sizes are many and varied. Here are some of the more common reasons why this ends up happening:
- The publisher is trying to maximize their ability to rank on long-tail terms.
- The publisher believes that offering a massive level of refinements is good for the user experience.
- The site uses an unconstrained tagging system that allows any combination of tags (even clearly illogical combinations) to create unique new pages.
- The site implementation has bugs in it that result in pages being unintentionally created.
When sites grow this large, it often means that many of the pages have very little redeeming value, or that the differences between groups of pages in a given section are nearly trivial.
Consider, for example, a page about “Size 10 blue left-handed bottle washing widgets” and “Size 10 green left-handed bottle washing widgets.” Users may want to choose their color, but that should not really require the creation of an entirely new web page. I have seen situations where the ratio of total pages to arguably useful pages is as high as 10:1!
The problem with having pages like this is that it can cause your site to be flagged by Google as thin content. This could mean a loss of visibility due to the Panda algorithm or even a manual penalty. Neither of these is a good thing!
Noindexing Not The Answer
One way to avoid the penalty scenario is to put the noindex tag on the pages that you do not wish to be included in Google’s index. Assuming that you can identify all of the pages that might cause Google concern, this will remove the risk of the manual penalty or being hit by the Panda algorithm, but this is not enough. Let’s explore the three main reasons why:
1. Dilution Of PageRank Focus. One common scenario is that the “bad” pages are linked to within a list of products.
When this is handled properly, the links in this list point to pages that are very closely related and highly relevant to the page the links are on and worth indexation, as shown here:
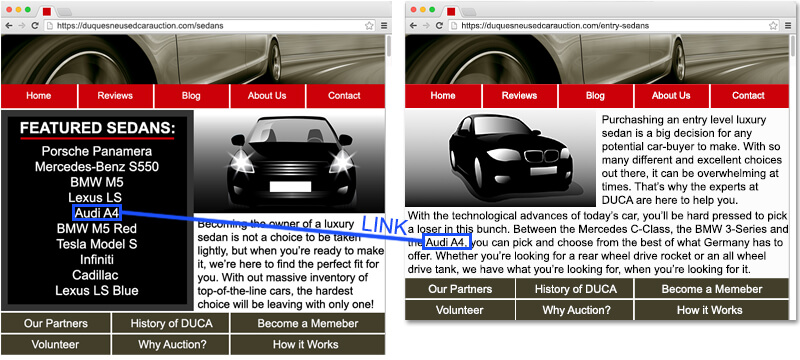
Now chances are that every page of your site is going to have some links that point to your home page, your “about us” page, your “contact us” page, a privacy policy, and other less topically focused pages such as those.
Don’t get me wrong, those links are an important part of your site structure, so having them there is a good thing. However, the links to those product pages within a topically relevant navigation path (“Topically Relevant Links to Key Money Pages”) are truly precious. You don’t want to waste them.
The problem starts when some of the links in the product list are pages that are not worthy of being indexed. You can solve the penalty related problems with the noindex tag, but you end up wasting some of that PageRank. Here is an example page to illustrate the problem:
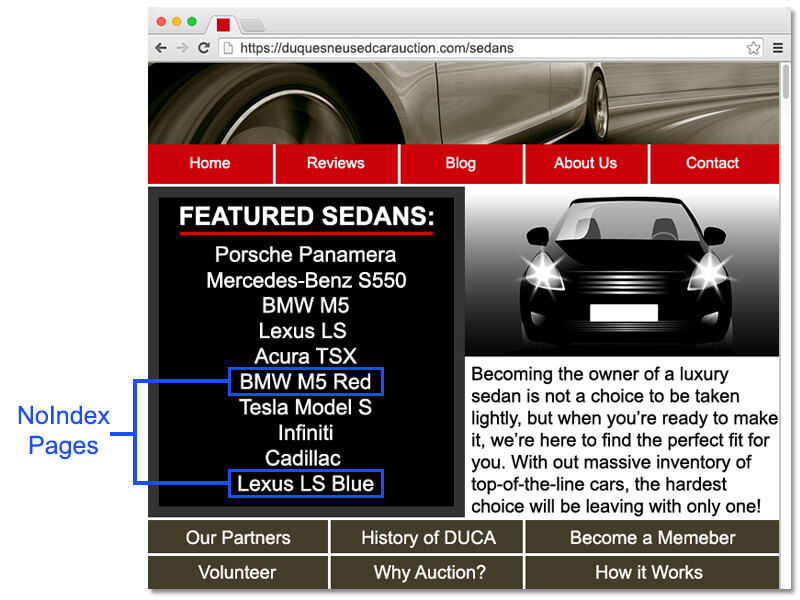
In the example image above, 20% of our Topically Relevant Links to Key Money Pages are pointing to a noindexed page. This PageRank is basically completely wasted. Why? Let’s take a look at what happens on that noindexed page:

Some of the PageRank is consumed by the noindexed page itself, and even though the noindexed page can still pass the rest of the PageRank out to other pages via links, the great majority of those links are going to pages other than your key money pages as I showed in the example image above.
2. PageRank Passed Into Never-Never Land. Wasting the PageRank from Topically Relevant Links to Key Money Pages is bad enough, but it’s not the only problem. On very large sites, you can have a situation where Google does not crawl your entire site, as shown here:
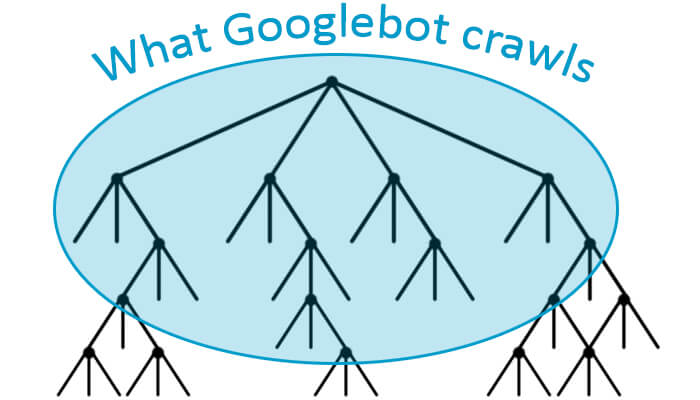
As shown in this image, Google reaches the point where the crawling stops. It simply has decided that there are too many pages on the site for it to go any further. Yet the pages at the bottom of the tree where the crawling stops are still passing the PageRank they have to other pages that Google has not, and will not, crawl. That PageRank is effectively passed into never-never land, and it’s wasted as well.
3. Chews Up Crawl Bandwidth. Google still crawls pages with the NoIndex tag on the page. If you have a large percentage of pages on your site that are noindexed, Google will spend time crawling those pages instead of crawling pages that it might actually rank for you.
This can hurt you when you make major changes on your site that you want Google to see and process, or when you add a new section to the site. For most sites, Google only crawls a small portion of the site on a given day, so having it spend time on a part of their “crawl budget” on pages that have no meaning to them can greatly slow down the process of discovering the great new changes you made.
Rel=Canonical Not So Good Either
An alternative solution to the NoIndex tag is to implement Google’s rel=canonical tag to tell Google that a given page is to be considered a copy or a subset of another page. In principle, this is great, because it would preserve all of the PageRank associated with the page, and pass it back to the page linked to in the tag. There are two problems with this:
- Rel=canonical is meant to be used only in cases where the page with the tag on it is a strict copy or subset of the page which the tag links to. Using it in situations where this is not the case is not advised.
- Even if the pages you are trying to deal with are strict subsets of pages you want to keep, Google considers rel=canonical to be a suggestion, and it may choose to ignore the suggestion. This is unfortunately, not that uncommon, and in my experience happens a lot in these very large web site situations.
Sometimes You Just Have To Bite The Bullet
Sometimes you have just have to take on the task of cleaning the mess up. It can also pay huge dividends, as shown in this traffic chart:

We reduced the page count on this site by more than 90%, from hundreds of millions of pages to tens of millions. It looks like Google liked it!
A significant development effort will be necessary in order to straighten this sort of situation out; however, my experience is that the rewards usually justify the effort.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author