Structured Data Markup Was Inevitable, But Is It An Admission Of Failure?
The movement toward structured data markup (i.e., increasing use of standards like Open Graph, Schema.org, RDFa, etc.) has bothered me for awhile, but I could not exactly put my finger on the issues. A few weeks ago at SMX East, there were some great presentations on these topics, and I finally realized that I have […]
The movement toward structured data markup (i.e., increasing use of standards like Open Graph, Schema.org, RDFa, etc.) has bothered me for awhile, but I could not exactly put my finger on the issues.
A few weeks ago at SMX East, there were some great presentations on these topics, and I finally realized that I have many major reservations about the proliferation and use of these standards, on many levels (mostly from a publisher perspective; for end-users they are generally a very positive development).
What Are These Standards?
They sound complicated, but in layman’s terms, I would say: think of them as being similar to additional meta-tags on a page, similar to a meta-description or meta-keywords, but often in XML format, which convey certain structured information about various objects.
Like meta-tags, these are intended to be machine-readable, but not necessarily presentable to humans in a browser. Much of the rich information showing up in search engine results (such as reviews, prices, etc.) are being enabled by publishers (i.e., website owners) exposing their data using these standards.
Figure 1 shows some structured data that Google displays in its search results already. Search for [schema.org], [microformats], or [open graph], if you’d like to learn more.
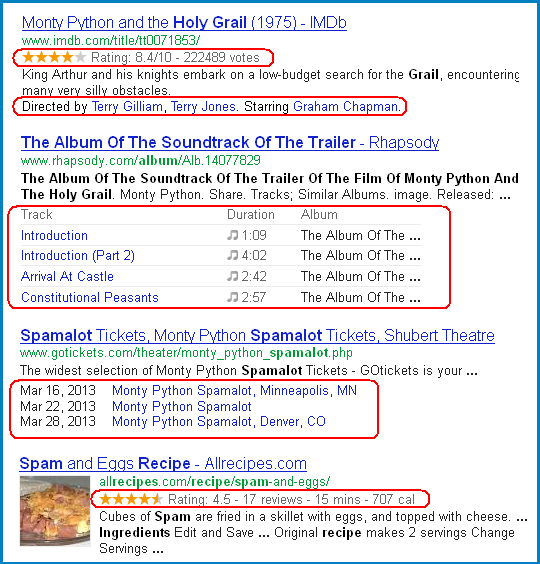
Figure 1 – Example of Structured Markup Showing up in Search Results
Why These Are Bad For Publishers From A Search Standpoint
By showing rich information in the search results, Google and others can get users to navigate to the information they need more quickly. Another way of thinking about this is, they are essentially denying publishers the navigational clicks that users would have given them, had they navigated to the site and then had to poke around.
For example, showing a Movie showtime in a SERP denies the publisher the opportunity to try to get the viewer to purchase a ticket for pickup at the box office; the user may see the showtime and then move on to their next task, simply buying the ticket at the theater.
But Aren’t Publishers Who Implement Microformats Getting More Traffic?
Yes, this seems to be the consensus, although it’s not clear why. It could be that the search engines are intentionally favoring pages that expose information in this way (which seems likely), or it could also be that (as someone in the audience at one of the SMX East talks brought up), the use of these schemas may simply make the publisher do a better job of organizing and exposing their information.
For instance, if you’re using schema markup that exposes name, address, and phone number, you’re unlikely to forget including your phone number (it acts as a sort of checklist) and it will likely make you also expose the phone number in your HTML for users to see.
Either way, publishers who use structured data markup are reporting higher organic traffic; but think about it for a minute; clearly, this must be at the expense of others who are not using them and are experiencing lower traffic as a result.
What worries me is: what happens when everyone (or at least the top 10 search results) are all using structured data markup? At that point, an argument for higher traffic will not hold water — it’s no advantage if everyone is doing it.
Microformats Make It Possible For Anyone To Steal Your Content
Microformats make your information that much more easily scraped and parsed by sites that you don’t want taking your information, not just by search engines – scrapers, even competitors who want to monitor your pricing, and so on.
Why is it OK for a search engine to show my pricing information in a SERP, but it’s not OK for my competitor to show it on their website?
Microformats, by freely allowing search engines to show information provided in them, seem to be on a legal slippery slope – how are you supposed to delineate between accepted uses and non-accepted uses, when there is no mechanism for doing so?
Where Does It Stop?
Anyone who’s familiar with schemas from the IT world, such as SNMP, DMI, USB, etc., can attest to their usefulness, but these are schemas created for very specific purposes.
The problem with using schemas to describe information about objects on the Internet is: the entire world is essentially exposed on the Internet. The Internet has information about recipes, tress, celebrities, maybe even eventually, the freckle on your left finger.
If the industry pushes towards structuring information on the Internet, what that really is accomplishing is structuring data about everything in the world. If you don’t believe me, take a look at the full hierarchy on schema.org — it looks like a slippery slope to me with no end in sight, this hierarchy will very likely continue to be fleshed out and expanded over time.
Microformats Are Anti-Human & An Admission Of Failure
Yes, you read that right. According to Genesis, God had Adam name all of the animals. He didn’t tell Adam to name, catalog, index, organize, and label every object in the Garden down to the level of tree 5 is a parent of branch 6 which is a parent of twig 4 which is a parent of leaf 3 which has the properties green and serrated.
I was always under the impression that the search engines were soaking up all the Ph.Ds in the fields of machine learning and artificial intelligence so they could have computers figure things out for us.
For instance, I would have thought that someone at Google would, by now, have written a program to examine a webpage, determine that it’s a recipe, and parse it out and figure out the ingredients, steps, and times. Instead, it seems that Google’s solution is instead, hey, it would be great if you would just mark up and label all the information in your recipes – thanks.
I thought that’s what computers were for in the first place, figuring stuff out! Computers should infer meaning, not have humans label meaning.
The phrase Semantic Web, which is used to refer to these schema’s role, is, in my opinion, the biggest technology misnomer of all time — there’s nothing semantic about them. It should be called the we failed to understand actual meaning so we’re going have everyone label everything instead Web.
The best Google can do with all these Ph.Ds is to tell us: hey everyone, please mark up everything in the world because that will make things so much easier for us.
Really? Why did you bother hiring all those people, is that the best you guys can come up with?
But Your CMS Will Take Care of All That, You Don’t Have To Do It Yourself
You can argue that it’s not a waste of human effort because your CMS will take care of this. While that’s somewhat true, engineers created the CMS to be aware of whatever the particular schema was.
Your DBA or Web Developer worked to integrate your back-end data in a structured way with the CMS. And for the particular schema at hand to be developed, people from all over the world had to fly to Paris, or wherever, for some meetings, and argue and haggle over what properties the object would have, and where it would sit in the hierarchy. This is all human effort.
Microformats Divorce Machine Readable Data From Human Readable Data
If you think about it, by exposing data on your Web page for a machine to read, which you are not showing to a human, it’s almost like cloaking — you’re presenting different information to a spider than you are to the user. Of course, you should show the user the same data, but in a nice presentable HTML format.
How is this different from cloaking? In fact, as search engines get smarter at parsing this data, I’m sure some bright folks will start to put checks in place — hey, this guy is saying one thing to us but saying something different to humans.
Then publishers will have to start worrying about running reports to identify which pages on a website have schema information that doesn’t match the rest of the content on the page. More complexity we didn’t need.
Microformats Are Redundant! Microformats Are Redundant!
Why why list the same data multiple times on a page in different formats? While you’re at it, why don’t you throw a bunch of hreflang tags on your page? Maybe you can get it to be four or five times as long as it needs to be with as much junk as possible on it; that should be great for your page load speed time!
The great thing about the HTML standard was, it included everything that was sufficient, but only those things that were necessary – why are we now moving toward saying the same thing on a page over and over again, in all these different formats?
In A World of Microformats, Robots.Txt Is Not Enough
It’s important that major improvements in one area be matched by improvements in supporting areas. For instance, now that Google has Universal Search, wouldn’t it be great if the AdWords Keyword Tool actually told you something about Universal Results? (Fail!). That’s a minor example of a supporting area that failed to keep up with a megatrend.
With schemas, the key supporting area that is failing to keep up, in my opinion, is the robots.txt format.
Somehow, search engines appear to have gotten society (and in some cases, courts) to consider your “robots.txt file as being the equivalent of some sort of machine-readable legal agreement.
Personally, I view this as a ridiculous position — I’m sure the major search engines are constantly crawling sites whose Terms and Conditions expressly forbid using a program to read the site — but search engines have used robots.txt as a fig leaf for either showing or not showing content in SERPs on a Yes/No basis.
Now that Microformats are proliferating and we’re being indoctrinated that if something is structured, it can be shown in a SERP, what is to prevent the search engine from showing anything that’s marked up in this way in the SERP? Why not mark all the content as paragraph 1, paragraph 2, and paragraph 3, and just give them the whole thing?
The robots.txt format, in my opinion, needs to evolve so publishers can specify how their information, on a granular basis, can be used, not just whether their information can be used. Ideally, robots.txt should be a fragmented thing that lives on each page, and each tiny piece of content should be able to specify the publisher’s intent for its usage.
A History Lesson – SGML
Remember SGML? Most of you don’t. SGML was (maybe still is, I don’t know) a structured markup language that was put together for a variety of purposes, but when I encountered it in the early 90’s it seemed to be driven primarily by the technical writing community, for the purpose of making manuals and spec sheets machine readable.
I was in the semiconductor industry at the time, and SGML was simultaneously all the rage for the technical writing community as well as sort of the bane of it — because it was a huge, bloated standard that appeared to have been designed by some out-of-control committees that went way over the top.
Fortunately, HTML, which is sort of a tiny nephew to SGML, used some of the conventions of SGML, but was created as a much more simplified markup language for describing simpler hypertext documents. Then, when Tim Berners-Lee conceived the Internet at CERN, all you really needed was a title tag, some content, a few bold and paragraph tags, and — boom — you could have a webpage.
What’s going on with this Schema stuff is a return to the SGML approach — management by committee, huge bloated hierarchical class/property standards, and an Internet that is going to become unnecessarily complex.
If You’re A Large Company, You Need To Drive These Standards
Some of these standards, and decisions about their adoption, are actually going to involve life-and-death decisions for companies. If you don’t believe me, go back in time and ask FTP Software, the provider of a popular TCP/IP stack for Microsoft Windows, what they thought when Microsoft decided to include its own TCP/IP stack in Windows!
If you’re a travel provider, you should be worried about search engines increasingly providing travel search information right on the search results page – so you probably should be worried about any schemas being worked on in the field of travel information.
What about insurance providers? Real Estate? Credit Reports? If you don’t want to get disintermediated by a large search engine, you might want to get involved in the standards process… and not always to make it successful.
This is sort of the dirty little secret of the standards world you won’t read about in news articles, but many standards committee members often actually have a fiduciary responsibility to their company to make sure that any standard that is ratified is a failure, or leaves out key pieces of data so their company can still continue to dominate its market space.
Don’t believe me? Get involved in a standards committee involving a dominant market player and just observe their behavior!
A Positive Unintended Consequence
This was mentioned by one of the panelists: once the entire world has been categorized and marked up, it will be much easier to make a new search engine, because there won’t be much it will have to actually understand anymore.
As these schemas proliferate, presumably some interesting startups will be created that leverage this data in interesting ways; ten years from now we will no doubt be surprised at another two or three big players that have sprung up from nothing around this megatrend.
Conclusion
So, in short: in my opinion, from a publisher’s perspective, these emerging structured data markup standards allow search engines, competitors, and scrapers to more easily steal your content; may in the long run deny you clicks, result in unnecessary page bloat, unnecessarily complicate things; and are setting the industry back twenty-five years in terms of making humans structure data rather than having computers infer structure.
However, it looks like they are great for end-users and are inevitable, so you’d better get on the bandwagon!
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author