3 Components Of Geo-Targeting Excellence For 2014
Smart use of the geo-targeting controls through Enhanced Campaigns in AdWords will prove to be the single largest opportunity for paid search marketers in 2014. Geo-targeting is nothing new. It has been a foundational element for local and regional businesses since the very early days of AdWords. What Enhanced Campaigns gives us is the ability […]
Smart use of the geo-targeting controls through Enhanced Campaigns in AdWords will prove to be the single largest opportunity for paid search marketers in 2014.
Geo-targeting is nothing new. It has been a foundational element for local and regional businesses since the very early days of AdWords. What Enhanced Campaigns gives us is the ability to take a very sophisticated approach to geo-targeting and apply dynamically calculated bid modifiers at unprecedented scale.
Up to this point, advertisers with substantial keyword lists operating over a range of geographies have had to take one of two far from ideal shortcuts:
- Get granular with geographies with only a small subset of head keywords
- Cut the geographic map into very few pieces
Getting granular in a comprehensive fashion, simply wasn’t feasible given constraints on both the number of campaigns allowed and the volume of work required to maintain that degree of replication. We were also limited by the information disconnect: the geographies we could infer from IP mapping weren’t necessarily the geographies Google saw.
Google is now giving us click-level geographic insights, and with the mechanical limitations of the system removed, the only limits to highly sophisticated geo-targeting are the imagination of the marketer and the capabilities of the platforms they use.
The Promise Of Geo-Targeting
Granular bid targeting capabilities are exciting because they give us the ability to better match our bids to the value of traffic. If the location of the user impacts the value of the traffic the way that the query and the device do, then we’d like to have a good way to comprehensively address those differences. We’d like to bid more aggressively for the better traffic and more conservatively for the lower quality traffic that is currently not differentiable.
The Enhanced Campaign structure allows us to set up to 10,000 geo-based bid modifiers for each campaign. This opens the door to a level of targeting precision we have not yet enjoyed, meaning more bang for marketing bucks.
Addressing Sparse Data Concerns
Some in the space will object: “Bidding by keyword already gets us into significant challenges with sparse data on the torso and tail; trying to determine granular geo-modifiers by campaign will only add to this same problem.”
Sparse data is a real challenge, but looking at the way sophisticated systems address this problem with keywords will serve as a model for how we can layer in geography. For most accounts, the vast majority of keywords don’t generate enough data within any reasonable period of time to make statistically significant measurements of their value without recourse to clustering mechanisms. Clustering allows us to understand how “similar” keywords perform.
For keywords, “similarity” can be thought of hierarchically like themes, product categories/sub-categories, travel destinations, etc. However, sophisticated systems use more nuanced, non-hierarchical, notions of similarity. Keywords may have attributes that make them similar to other keywords thematically, but may also share attributes of keywords that are not in the same ad group or campaign. Smart systems assess how different attributes and combinations of attributes contribute to performance variations observed in the data. This leads to more efficient and effective use of valuable marketing dollars.
For example: “discount laptop bags” and “cheap leather clutch” likely aren’t in the same ad group or campaign, but they share the common attribute of being “low price focused.” That “low price focused” attribute may make “discount laptop bags” perform more like “cheap leather clutch” than “full-grain leather laptop bags.”
With respect to geo-targeting, this same logic will apply. As we see it, there are three different components of playing the geo-targeting game well.
Component 1: Contiguous Hierarchies
Looking for meaningful commonalities by understanding the relationship between geographic regions is a starting point. The ZIP code “90210” is in Beverley Hills, which in turn is in Greater Los Angeles, which is part of Southern California, which is part of California, etc. We may not have enough data about that campaign’s performance in a particular ZIP code to create a modifier, but expanding to the city, metro area, region, state, etc., allows us to get the smallest region possible to have statistically meaningful data.
Contiguous hierarchies allow us to get a basic approach to dynamically calculated modifiers rolling.
(Wonky minutiae: Be careful. ZIP codes are not always the smallest biddable region. In rural areas many cities/towns may be served by a single postal code.)
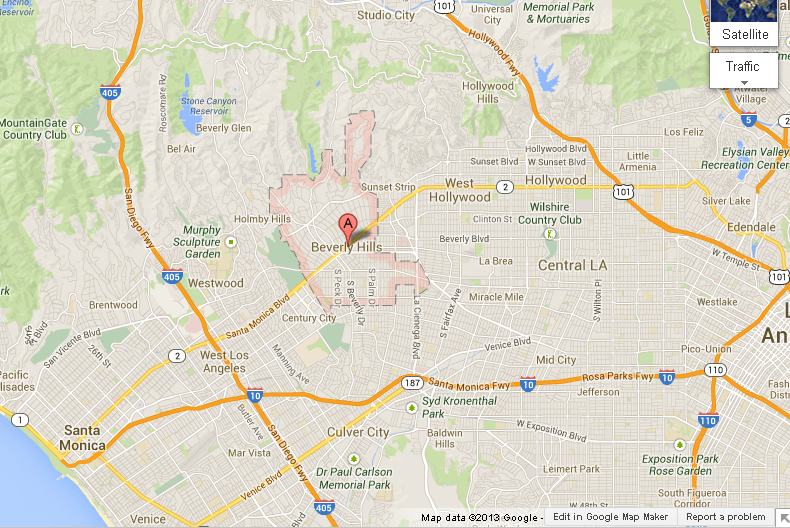
Component 2: Non-Contiguous Regional Commonalities
The problem with simply expanding the region to DMA or state is that Greater Los Angeles contains many disparate neighborhoods, each with hugely different consumers and consumer behavior. A far better mechanism for aggregation is to look for demographic commonalities that may carry more predictive power.
Rancho Sante Fe, California and Indian River Shores, Florida are 3,000 miles apart but have in common the fact that they’re among the highest income addresses in the US. Atlanta and San Francisco don’t have much in common, but both are “big cities.” It is not hard to imagine that income levels, home ownership rates, average daytime temperature, population density, etc., could all have a material impact on traffic value.
Using publicly available information about geo regions to create non-contiguous clusters gives us another lens through which we can understand the factors that influence value. It may be that it is combinations of contiguous regions and non-contiguous commonalities that are the best predictors of value.
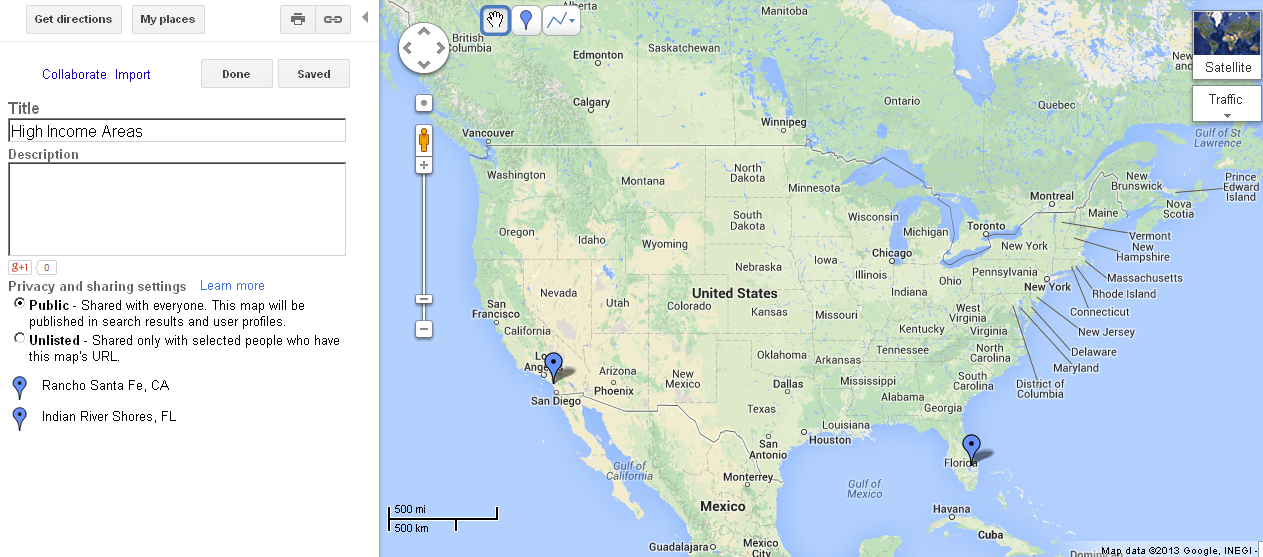
Component 3: Advertiser Specific Clusters
Each advertiser may have geographic commonalities that are meaningful only to them. For some e-commerce companies, shipping costs change dramatically depending on the proximity of the shipping destination to a distribution center. That geographic dimension — “low cost shipping” vs. “high cost shipping” — may have a huge impact on conversion rates, but it’s a cluster that doesn’t map the same way for any two advertisers.
Proximity to my brick-and-mortar stores is obvious. Less obvious might be the impact of proximity to your arch-rival’s stores. Are clicks on your paid search ads driving foot traffic to your competitors’ stores? What about those geographies that represent the overlap? Perhaps Kohl’s is best served pushing bids in proximity to their stores, but not if it’s near a Marshall’s as well? We don’t know until we look at the data.
Stats modeling can find amazing connections given a mountain of data and a ton of time. Providing tags for geographies that we think might impact performance can help the models find gold much more efficiently. Having a smart analyst guide the machine is tremendously valuable, here.

Conclusion
Similar to keywords, there are different geographic attributes and combinations thereof which statistical modeling can help us to understand. Understanding the impact on value of geographic and proximity effects is key to unlocking the next level of paid search performance.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author