Common Search: The open source project bringing back PageRank
Columnist JR Oakes explains Common Search, a great open source tool for understanding how search engines work, which has a hidden gem for those of us who miss checking our PageRank score.
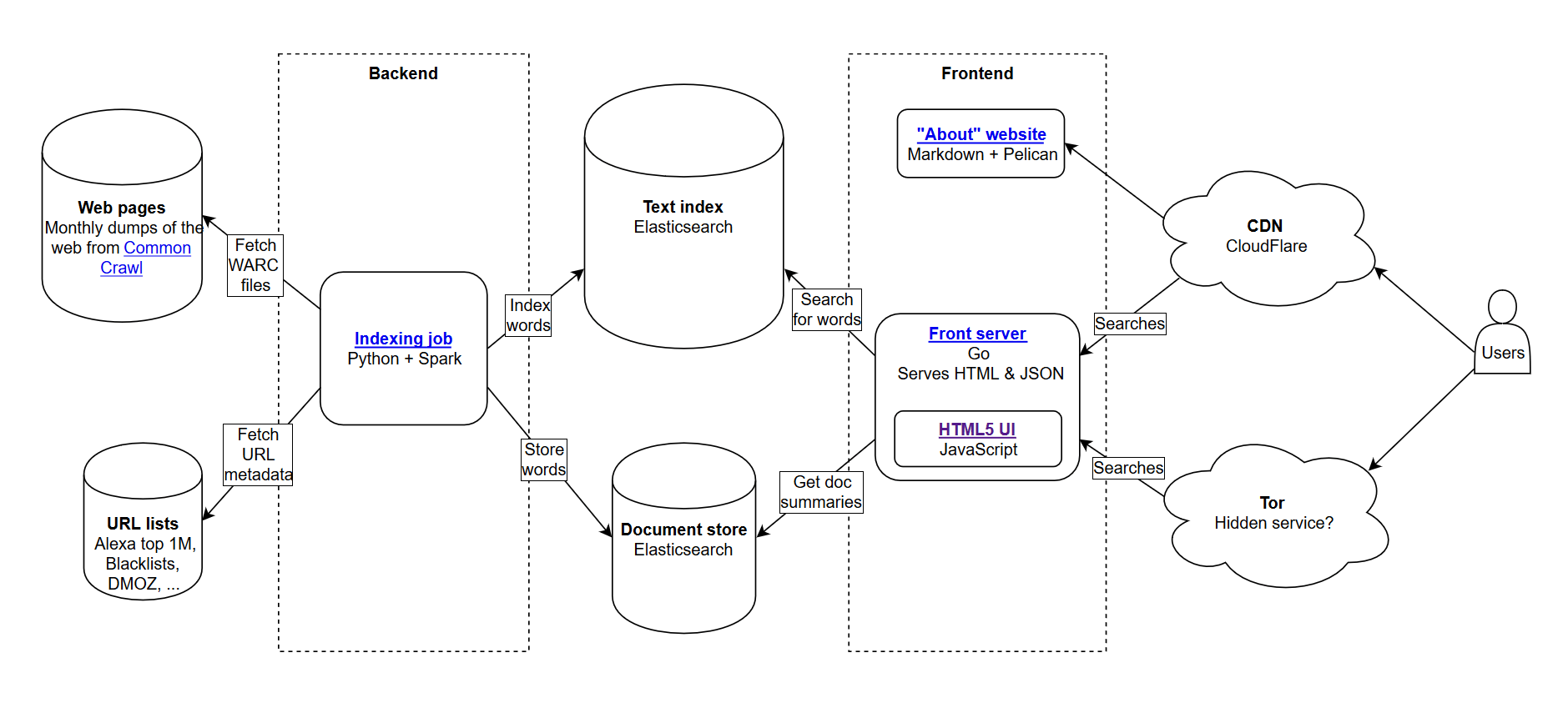
Over the last several years, Google has slowly reduced the amount of data available to SEO practitioners. First it was keyword data, then PageRank score. Now it is specific search volume from AdWords (unless you are spending some moola). You can read more about this in Russ Jones’s excellent article that details the impact of his company’s research and insights into clickstream data for volume disambiguation.
One item that we have gotten really involved in recently is Common Crawl data. There are several teams in our industry that have been using this data for some time, so I felt a little late to the game. Common Crawl data is an open source project that scrapes the entire internet at regular intervals. Thankfully, Amazon, being the great company it is, pitched in to store the data to make it available to many without the the high storage costs.
In addition to Common Crawl data, there is a non-profit called Common Search whose mission is to create an alternative open source and transparent search engine — the opposite, in many respects, of Google. This piqued my interest because it means that we all can play, tweak and mangle the signals to learn how search engines operate without the huge time investment of starting from ground zero.
Common Search data
Currently, Common Search uses the following data sources for calculating their search rankings (This is taken directly from their website):
- Common Crawl: The largest open repository of web crawl data. This is currently our unique source of raw page data.
- Wikidata: A free, linked database that acts as central storage for the structured data of many Wikimedia projects like Wikipedia, Wikivoyage and Wikisource.
- UT1 Blacklist: Maintained by Fabrice Prigent from the Université Toulouse 1 Capitole, this blacklist categorizes domains and URLs into several categories, including “adult” and “phishing.”
- DMOZ: Also known as the Open Directory Project, it is the oldest and largest web directory still alive. Though its data is not as reliable as it was in the past, we still use it as a signal and metadata source.
- Web Data Commons Hyperlink Graphs: Graphs of all hyperlinks from a 2012 Common Crawl archive. We are currently using its Harmonic Centrality file as a temporary ranking signal on domains. We plan to perform our own analysis of the web graph in the near future.
- Alexa top 1M sites: Alexa ranks websites based on a combined measure of page views and unique site users. It is known to be demographically biased. We are using it as a temporary ranking signal on domains.
Common Search ranking
In addition to these data sources, in investigating the code, it also uses URL length, path length and domain PageRank as ranking signals in its algorithm. Lo and behold, since July, Common Search has had its own data on host-level PageRank, and we all missed it.
I will get to the PageRank (PR) in a moment, but it is interesting to review the code of Common Crawl, especially the ranker.py portion located here, because you really can get into the driver’s seat with tweaking the weights of the signals that it uses to rank the pages:
signal_weights = {
"url_total_length": 0.01,
"url_path_length": 0.01,
"url_subdomain": 0.1,
"alexa_top1m": 5,
"wikidata_url": 3,
"dmoz_domain": 1,
"dmoz_url": 1,
"webdatacommons_hc": 1,
"commonsearch_host_pagerank": 1
}
Of particular note, as well, is that Common Search uses BM25 as the similarity measure of keyword to document body and meta data. BM25 is a better measure than TF-IDF because it takes document length into account, meaning a 200-word document that has your keyword five times is probably more relevant than a 1,500-word document that has it the same number of times.
It is also worthwhile to say that the number of signals here is very rudimentary and obviously missing many of the refinements (and data) that Google has integrated in their search ranking algorithm. One of the key things that we are working on is to use the data available in Common Crawl and the infrastructure of Common Search to do topic vector search for content that is relevant based on semantics, not just keyword matching.
On to PageRank
On the page here, you can find links to the host-level PageRank for the June 2016 Common Crawl. I am using the one entitled pagerank-top1m.txt.gz (top 1 million) because the other file is 3GB and over 112 million domains. Even in R, I do not have enough machine to load it without capping out.
After downloading, you will need to bring the file into your working directory in R. The PageRank data from Common Search is not normalized and also is not in the clean 0-10 format that we are all used to seeing it in. Common Search uses “max(0, min(1, float(rank) / 244660.58))” — basically, a domain’s rank divided by Facebook’s rank — as the method of translating the data into a distribution between 0 and 1. But this leaves some definite gaps, in that this would leave Linkedin’s PageRank as a 1.4 when scaled by 10.

The following code will load the dataset and append a PR column with a better approximated PR:
#Grab the data
df <- read.csv("pagerank-top1m.txt", header = F, sep = " ")
#Log Normalize
logNorm <- function(x){
#Normalize
x <- (x-min(x))/(max(x)-min(x))
10 / (1 - (log10(x)*.25))
}
#Append a Column named PR to the dataset
df$pr <- (round(logNorm(df$V2),digits = 0))

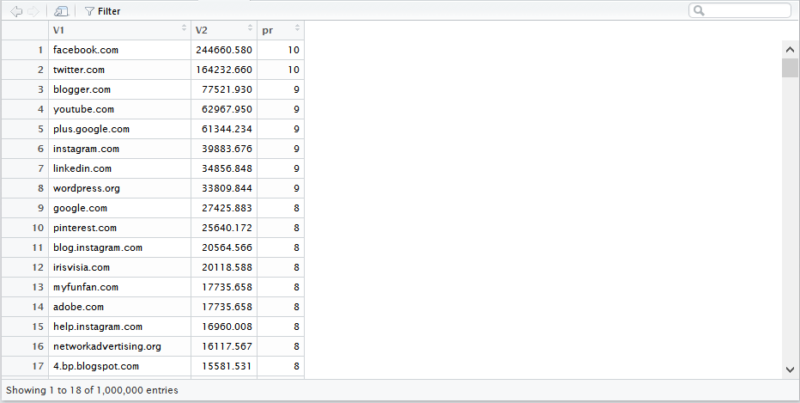
We had to play around a bit with the numbers to get it somewhere close (for several samples of domains that I remembered the PR for) to the old Google PR. Below are a few example PageRank results:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Here is a plot of 100,000 random samples. The calculated PageRank score is along the Y-axis, and the original Common Search score is along the X-axis.

To grab your own results, you can run the following command in R (Just substitute your own domain):
df[df$V1=="searchengineland.com",c('pr')]
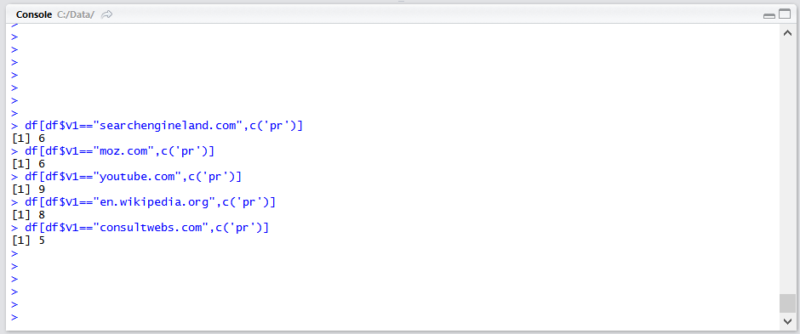
Keep in mind that this dataset only has the top one million domains by PageRank, so out of 112 million domains that Common Search indexed, there is a good chance your site may not be there if it doesn’t have a pretty good link profile. Also, this metric includes no indication of the harmfulness of links, only an approximation of your site’s popularity with respect to links.
Common Search is a great tool and a great foundation. I am looking forward to getting more involved with the community there and hopefully learning to understand the nuts and bolts behind search engines better by actually working on one. With R and a little code, you can have a quick way to check PR for a million domains in a matter of seconds. Hope you enjoyed!
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author