Could Google passage indexing be leveraging BERT?
How Google leverages BERT depends on the use of the term ‘Passage Indexing’ (although it’s identified as a ranking update).
It’s been 12 months since Google announced a new update called BERT in production search and there should be no surprise the recent Search On event, falling almost on the eve of production BERT’s first birthday, included so much talk of huge progress and breakthroughs using AI and BERT during the past year.
A recap on what BERT is
To recap, the Google BERT October 2019 update is a machine learning update purported to help Google better understand queries and content, disambiguating nuance in polysemous words via greater understanding of “word’s meaning” (context). The initial update impacted just 10% of English queries as well as featured snippets in territories where they appeared.
Importantly, that initial BERT search update was for disambiguation primarily, as well as text extraction and summarisation in featured snippets. The disambiguation aspect mostly applied to sentences and phrases.
Within a month or so of BERT’s production search announcement, roll out began to many more countries, albeit still only impacting 10% of queries in all regions.
Initially the October 2019 announcement caused quite a stir in the SEO world, not least because, according to Google, when announcing BERT, the update represented the “biggest leap forward in the past five years, and one of the biggest leaps forward in the history of search.”
This was clearly the most important announcement since RankBrain and no exaggeration — and not just for the world of web search. Developments related to BERT during the preceding 12 months for the field of natural language understanding (a half century old area of study), had arguably moved learnings forward more in a year than the previous fifty combined.
The reason for this was another BERT — a 2018 academic paper by Google researchers Devlin et al entitled “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Note, I will be referencing several academic papers here. You will find a list of sources and resources at the end of this article
BERT (the paper) was subsequently open-sourced for others in the machine learning community to build upon, and was unquestionably a considerable contributor to the World’s dramatic computational linguistics understanding progress.
BERT’s basic idea is it uses bi-directional pre-training on a context window of words from a large text collection (En Wikipedia and BookCorpus) using a transformer “attention” mechanism so as to see all of the words to the left and to the right of a target in a sliding context window simultaneously for greater context.
Once trained, BERT can be used as a foundation and then fine-tuned on other more granular tasks, with much research focus on downstream natural language understanding and questions and answering.
An example for clarity of the ‘context window’ for ‘word’s meaning’
Since the scope of a context window is an important concept I have provided an example for illustration:
If a context window is 10 words long and the target word is at position 6 in a sliding “context window” of 10 words, not only can BERT see words 1-5 to the left, but also words 7-10 to the right at the same time using attention “word pairs” quadratically.
This is a big advancement. Previous models were uni-directional, meaning they could only see words 1-5 to the left, but not 7-10 until they reached those words in the sliding window. Using this bi-directional nature and simultaneous attention provides full context for a given word (within the constraints of the length of the window of course).
For example, the word “bank” is understood differently if the other words within the context window also include “river” or “money.” The co-occurring words in the context window add to the meaning and suddenly “bank” is understood as being a “financial bank” or a “river bank.”
Back to the October 2019 Google BERT update announcement
The October 25, 2019, production search announcement followed what had been a frenetic BERT-focused year in the language research community.
In the period between 2018 and 2019 all manner of the Sesame Street character named BERT-type models appeared, including ERNIE, from Baidu. Facebook and Microsoft were also busy building BERT-like models, and improving on BERT at each turn. Facebook claimed their ROBERTA model was simply a more robustly trained version of BERT. (Microsoft says it’s been using BERT in Bing since April 2019,)
Big tech AI teams leapfrogged each other in various machine learning language task leaderboards, the most popular amongst them SQuAD (Stanford Question and Answer Dataset), GLUE (General Language Understanding Evaluation), and RACE (Reading Comprehension from Evaluations); beating human language understanding benchmarks as they went.
But what of 2020?
Whilst the SEO world has been quieter of late on the topic of BERT (until this month), enthusiasm in the deep learning and natural language processing world around BERT has accelerated, rather than waned in 2020.
2019 / 2020’s developments in AI and natural language understanding should absolutely make SEOs up their BERT-stalking game once more. Particularly in light of developments this week, in particular, following announcements from Google’s Search On online event.
BERT does not always mean the ‘BERT’
An important note before we continue:
“BERT-like” — a descriptive term for pre-training a large unlabelled text model on “language” and then using transfer learning via transformer technologies to fine-tune models utilizing a range of more granular tasks.
Whilst the 2019 Google update was called BERT, it was more likely a reference to a methodology now used in parts of search and the machine learning language field overall rather than a single algorithmic update per say, since BERT, and BERT-like even in 2019 was becoming known in the machine learning language world almost as an adjective.
Back to Google’s AI in search announcements
“With recent advancements in AI, we’re making bigger leaps forward in improvements to Google than we’ve seen over the last decade, so it’s even easier for you to find just what you’re looking for,” said Prabhakar Raghavan during the recent Search On event.
And he was not exaggerating, since Google revealed some exciting new features coming to search soon, including improvements to mis-spelling algorithms, conversational agents, image technology and humming to Google Assistant.
Big news too on the BERT usage front. A huge increase in usage from just 10% of queries to almost every query in English.
“Today we’re excited to share that BERT is now used in almost every query in English, helping you get higher quality results for your questions.”
(Prabhakar Raghavan, 2020)
Passage indexing
Aside from the BERT usage expansion news, one other announcement in particular whipped the SEO world up into a frenzy.
The topic of “Passage Indexing,” whereby Google will rank and show specific passages from parts of pages and documents in response to some queries.
Google’s Raghavan explains:
“Very specific searches can be the hardest to get right, since sometimes the single sentence that answers your question might be buried deep in a web page. We’ve recently made a breakthrough in ranking and are now able to not just index web pages, but individual passages from the pages. By better understanding the relevancy of specific passages, not just the overall page, we can find that needle-in-a-haystack information you’re looking for. This technology will improve 7 percent of search queries across all languages as we roll it out globally.”
(Prabhakar, 2020)
An example was provided to illustrate the effect of the forthcoming change.
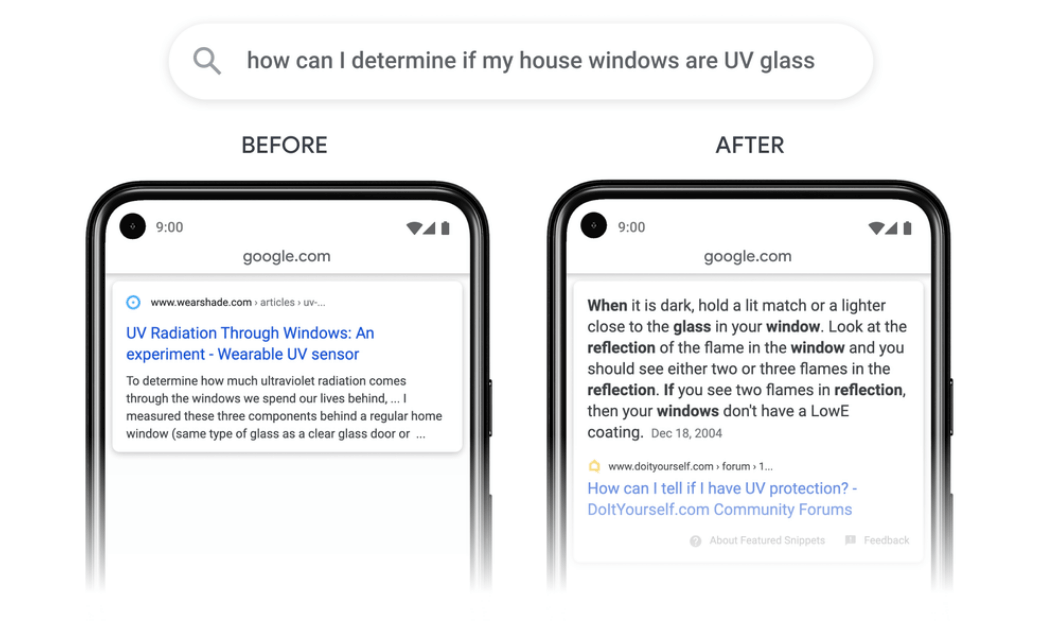
”With our new technology, we’ll be able to better identify and understand key passages on a web page. This will help us surface content that might otherwise not be seen as relevant when considering a page only as a whole….,” Google explained last week.
In other words, a good answer might well be found in a single passage or paragraph in an otherwise broad topic document, or random blurb page without much focus at all. Consider the many blog posts and opinion pieces for example, of which there are many, with much irrelevant content, or mixed topics, in a still largely unstructured and disparate web of ever increasing content.
It’s called passage indexing, but not as we know it
The “passage indexing” announcement caused some confusion in the SEO community with several interpreting the change initially as an “indexing” one.
A natural assumption to make since the name “passage indexing” implies…erm… “passage” and “indexing.”
Naturally some SEOs questioned whether individual passages would be added to the index rather than individual pages, but, not so, it seems, since Google have clarified the forthcoming update actually relates to a passage ranking issue, rather than an indexing issue.
“We’ve recently made a breakthrough in ranking and are now able to not just index web pages, but individual passages from the pages,” Raghavan explained. “By better understanding the relevancy of specific passages, not just the overall page, we can find that needle-in-a-haystack information you’re looking for.”
This change is about ranking, rather than indexing per say.
What might those breakthroughs be and where is this headed?
Whilst only 7% of queries will be impacted in initial roll-out, further expansion of this new passage indexing system could have much bigger connotations than one might first suspect.
Without exaggeration, once you begin to explore the literature from the past year in natural language research, you become aware this change, whilst relatively insignificant at first (because it will only impact 7% of queries after all), could have potential to actually change how search ranking works overall going forward.
We’ll look at what those developments are and what might come next.
Passage indexing is probably related to BERT + several other friends… plus more new breakthroughs
Hopefully more will become clear as we explore the landscape below since we need to dig deeper and head back to BERT, the progress in NLP AI around big developments closely related to BERT, and in the ranking research world in the last year.
The information below is mostly derived from recent research papers and conference proceedings (including research by Google search engineers either prior to working at Google, or whilst working at Google) around the information retrieval world, (the foundational field of which web search is a part).
Where a paper is referenced I have added the author and the year despite this being an online article to avoid perception of rhetoric. This also illustrates more clearly some of the big changes which have happened with indication of some kind of timeline and progress leading up to, and through 2019 and 2020.
Big BERT’s everywhere
Since the October 2019 announcement, BERT has featured EVERYWHERE across the various deep learning research industry leaderboards. And not just BERT, but many BERT-like models extending upon or using a BERT-like transformer architecture.
However, there’s a problem.
BERT and BERT-like models, whilst very impressive, are typically incredibly computationally expensive, and therefore, financially expensive to train, and include in production environments on full ranking at scale, making the 2018 version of BERT an unrealistic option in large scale commercial search engines.
The main reason is BERT works off transformer technology which relies on a self-attention mechanism so each word can gain context from seeing the words around it at the same time.
“In the case of a text of 100K words, this would require assessment of 100K x 100K word pairs, or 10 billion pairs for each step,” per Google this year. These transformer systems in the BERT world are becoming ubiquitous, however this quadratic dependency issue with the attention mechanism in BERT is well known.
More simply put: the more words added to a sequence, the more word combinations need to be focused on all at once during training to gain a full context of a word.
But the issue is “bigger is definitely better” when it comes to training these models.
Indeed, even Jacob Devlin, one of the original BERT authors in this presentation on Google BERT confirms the effect of the model size with a slide saying; “Big models help a lot.”
Big BERT-type models mostly have seemed to improve upon SOTA (State of the Art) benchmarks simply because they are bigger than previous contenders. Almost like “Skyscraper SEO” which we know is about identifying what a competitor has already and “throwing another floor on (dimension or feature),” to beat by simply doing something bigger, or better. In the same way, bigger and bigger BERT-like models have been developed merely by adding more parameters and training on more data in order to beat previous models.
Huge models come from huge companies
The most impressive of these huge models (i.e. those which beat SOTA (State of the Art) on the various machine learning leaderboards tend to be the work of research teams at the huge tech companies, and primarily the likes of Microsoft (MT-DNN, Turing-NLG), Google (BERT, T5, XLNet), Facebook (RoBERTa), Baidu (ERNIE) and Open AI (GPT, GPT-2, GPT-3).
Microsoft’s Turing-NLG recently dwarfed all previous models as a 17 billion parameter language model. It’s used in Bing’s autosuggest and other search features. The number of parameters is illustrated in the image below and shows Turing-NLG compared to some of the other industry models.

GPT-3
Even 17 billion parameters is nothing though when compared with OpenAI’s 175 billion parameter language model GPT-3.
Who can forget the sensationalized September 2020 Guardian newspaper piece about GPT-3 designed to shock, entitled “This entire article was written by a robot. Are you scared yet human?“
In reality this was merely next sentence prediction at massive scale, but to the layperson unaware of developments underway in the natural language space, it is no wonder this article was met with such a kerfuffle.
Google T5
Google’s T5 (Text-to-Text Transfer Transformer), (a more recent transformer based language model than BERT), released in February 2020, had a mere 11 billion parameters.
This was despite being pre-trained by a Google research team on a text collection made up of a huge web crawl of petabytes of billions of web pages dating back to 2011 from The Common Crawl, and aptly named C4, because of the four C’s in the name ‘Colossal Clean Crawled Corpus, due to its size.

But with big and impressive models comes expense.
BERT’s are expensive (financially and computationally)
The staggering cost of training SOTA AI models
In an article entitled “The Staggering Cost of Training SOTA (State of The Art) AI Models,” Synced Review explored the likely costs involved in training some of the more recent SOTA NLP AI models with figures ranging from hundreds per hour (and training can take many hours), to hundreds of thousands total cost to train a model.
These costs have been the subject of much discussion, but it is widely accepted, regardless of the accuracy of third party estimations, the costs involved are extortionate
Elliot Turner, founder of AlchemyAPI (Acquired by IBM Watson) surmised the cost to train XLNet (Yang et al, 2019), a combined work between Google Brain team and Carnegie Mellon released in January 2020, was in the region of $245,000.


This sparked quite a discussion on Twitter, to the point where even Google AI’s Jeff Dean chipped in with a Tweet to illustrate the offset Google were contributing in the form of renewable energy:

And herein lied the problem, and likely why BERT was only used on 10% of queries by Google at production launch in 2019, despite the territorial expansion.
Production level BERT-like models were colossally expensive from both a computational and financial perspective.
Challenges with longform content and BERT-like models
Transformer limitations
There’s another challenge too with practically scaling BERT-like models, and that relates to the length of sequences available in order to maintain word’s context. Much of this is tied to how large the context window is in the transformer architecture.
The size of a transformer’s window of a word’s context is crucial because “context” can only take into consideration words within the scope of that window.
Welcome “reformer”
To help with improving upon the available size of transformer context windows in January 2020, Google launched “Reformer: The Efficient Transformer.”
From an early 2020 VentureBeat article entitled Googles AI Language Model Reformer Can Process The Entirety of Novels: “…Transformer isn’t perfect by any stretch — extending it to larger contexts makes apparent its limitations. Applications that use large windows have memory requirements ranging from gigabytes to terabytes in size, meaning models can only ingest a few paragraphs of text or generate short pieces of music. That’s why Google today introduced Reformer, an evolution of Transformer that’s designed to handle context windows of up to 1 million words.”
Google explained the fundamental shortfall of transformers with regards to a context window in a blog post this year: “The power of Transformer comes from attention, the process by which it considers all possible pairs of words within the context window to understand the connections between them. So, in the case of a text of 100K words, this would require assessment of 100K x 100K word pairs, or 10 billion pairs for each step, which is impractical.”
Google AI chief Jeff Dean has said that larger context would be a principal focus of Google’s work going forward. “We’d still like to be able to do much more contextual kinds of models,” he said. “Like right now BERT and other models work well on hundreds of words, but not 10,000 words as context. So that’s kind of [an] interesting direction,” Dean told VentureBeat in December.
Google also acknowledge the weakness generally in current ranking systems (even aside from transformer or reformer based models), with regards to longer content, in its follow up clarification tweets about the new passage indexing development this past week:
“Typically, we evaluate all content on a web page to determine if it is relevant to a query. But sometimes web pages can be very long, or on multiple topics, which might dilute how parts of a page are relevant for particular queries….,” the company said.
The computational limitations on BERT are currently 512 tokens, making BERT-like models unfeasible for anything longer than passages.
BERT was not feasible for large scale production in 2018/2019
So, whilst BERT may have been a “nice to have,” in reality in it’s 2018 / 2019 format it was unrealistic as a solution to assist with large scale natural language understanding and full ranking in web search, and really only used on the most nuanced of queries with multiple meanings in sentences and phrases, and certainly not in any scale.
But it’s not all bad news for BERT
Throughout 2019 and 2020 there have been some big leaps forward aimed at making BERT-type technologies much more useful than an impressive “nice to have.”
The issue of long document content is being addressed already
Big Bird, Longformer and ClusterFormer
Since the majority of the issues for performance appear to be around this quadratic dependency in transformers and its impact on performance, and expense, more recent work seeks to turn this quadratic dependency to linear, with the most prominent amongst them Longformer: The Long Document Transformer (Beltagy, 2020) and Google’s Big Bird (Zaheer et al, 2020).
The Big Bird paper abstract reads: “The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization.”
Not to be outdone, in mid-October, Microsoft researchers (Wang et al, 2020) presented their paper on Cluster-Former. The Cluster-Former model is SOTA on Google’s Natural Questions “Long Answer” Leaderboard. Both of these models also seek to address the limitations with long form content.

And now ‘performers’ provide a rethink on transformers
Also very recently (October, 2020), a combined work between Google, Cambridge, DeepMind and Alan Turing Institute was published to address the efficiency and scale issues with the transformer architecture overall in a paper entitled “Rethinking Attention with Performers” (Choromanski et al, 2020), proposing a complete revisit to the fundamental way in which the attention mechanism works, designed to slash the costs of transformer type models.
Synced Review reported on this on October 2, 2020.

But these are all very, very recent pieces of work, and likely far too new to have much imminent impact on the passage indexing situation (for now), so they’re “probably” not the breakthroughs which Google referred to when announcing passage indexing.
There will certainly be a lag between long form content models such as Big Bird and ClusterFormer and significant improvements in long documents for the likes of BERT et al, in production search.
So, for now it seems natural language researchers and search engines have had to work with shorter sequences than long form content (e.g. passages).
So, back to the current situation.
Addressing unsolved areas of NLP models
Much of the focus in 2019 and 2020 seems to have been on addressing unsolved areas of NLP models Jacob Devlin referenced in his presentation that I mentioned earlier. These are:
- Models that minimize total training cost vs. accuracy on modern hardware.
- Models that are very parameter efficient (e.g. for mobile deployment).
- Models that represent knowledge/context in latent space.
- Models that represent structured data (e.g. knowledge graph).
- Models that jointly represent vision and language.
Whilst there has been work in several of the areas around BERT in the list, and knowledge graphs in particular, for the focus of this article we should continue to explore the training costs and parameter efficiency points Devlin itemized.
Making BERT more efficient and useful
The first item on Devlin’s list has seen good progress, with much research dedicated to creating models able to be used more economically and possibly feasible in a production environment.
More efficient models
Whilst 2020 has seen a wave of large models appear, almost simultaneously a wave of more efficient, distilled BERT-like models appeared amongst the research community aimed at maximising effectiveness retention whilst also reducing expense associated with efficiency.
DistilBERT, ALBERT, TinyBERT and ELECTRA: Minimal loss for maximum gain
Significant examples of efficiency improvements include Hugging Face’s DistilBERT, Google’s AlBERT(a lite BERT) and TinyBERT (a teacher / student type BERT model where knowledge is transferred from a large teacher BERT to a small student BERT (TinyBERT). Google introduced ELECTRA too, which utilized a different type of mask technology to improve performance considerably whilst maintaining the majority of effectiveness again.
According to Google AI, “ELECTRA matches the performance of RoBERTa and XLNet on the GLUE natural language understanding benchmark when using less than ¼ of their compute and achieves state-of-the-art results on the SQuAD question answering benchmark. These improvements are as a result of utilizing more efficient methods than masking 15% of words when training a BERT model, which is very computationally expensive.”
Each of the aforementioned adaptations are much more efficient than the original BERT model, with a minimal loss in effectiveness.
An ‘army’ of research engineers and free data
Another boost to progress comes in the form of a whole research community once more taking up the challenge (literally) involved in improving machine language understanding.
But willing participants need data to train better models.
As Devlin stated in his presentation, he believes “Near-term improvements in NLP will be mostly about making clever use of ‘free’ data.”
Whilst there are growing sources for plenty of free datasets around for data scientists to utilize (think Kaggle acquired by Google in 2017) for example; arguably the largest data scientist community with millions of registered users undertaking machine learning competitions). However, “real world” type data for “real” natural language research, based on the real everyday web and queries in particular, less so.
Nevertheless, the sources of “free” natural language data is growing and whilst there are now several, much of the data gifted to the natural language research community is by search engines to spur research.
MSMARCO (Microsoft)
Since 2016 MSMARCO datasets have been one of the predominant training exercises for fine-tuning models.
Microsoft’s MSMARCO, was initially a dataset of 100,000 questions and answers from real anonymized Bing search engines and Cortana assistant query submissions but has been expanded ten-fold to over 1,000,000 questions and answers. Furthermore, MSMARCO’s features have been extended to include additional training tasks extending beyond general natural language understanding and question and answer tasks.
Google natural questions (Google)
Like MSMARCO, Google has its own natural language question and answer dataset composed of real user queries to Google’s search engine, along with a leaderboard and tasks to undertake, called “Google Natural Questions.”
“The questions consist of real anonymized, aggregated queries issued to the Google search engine. Simple heuristics are used to filter questions from the query stream. Thus the questions are “natural” in that they represent real queries from people seeking information.”
(Kwiatkowski et al, 2019)
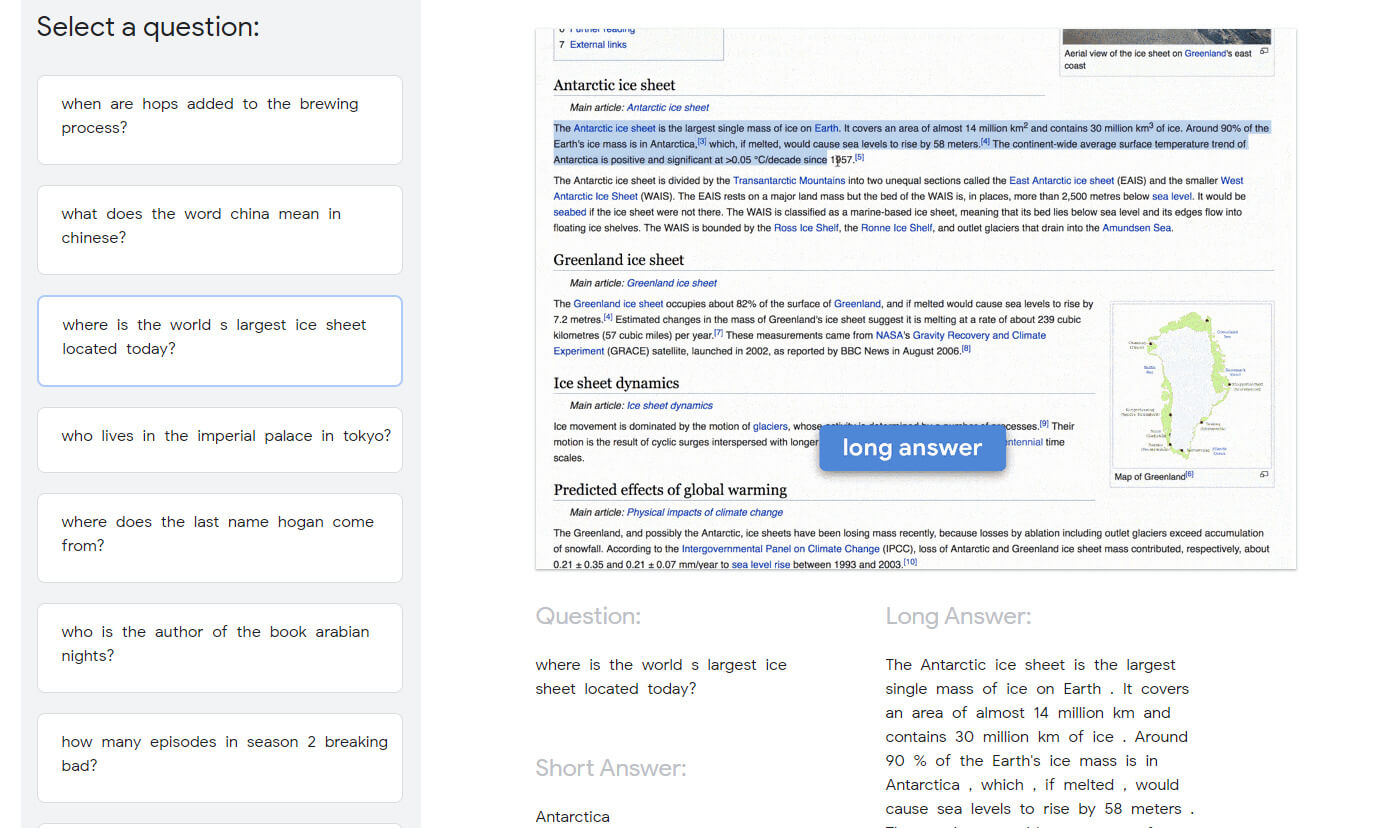
On Google Natural Questions, researchers have to train their models to read the entire page before finding both a long answer and a short answer in a single paragraph from Wikipedia. (visualization below)
TensorFlow C4 dataset – Colossal Clean Crawl
A more recent dataset is C4 (Colossal Clean Crawl of Common Crawl) mentioned earlier when introducing T5. Whilst the original BERT’s language pre-training was on 2.5 billion words of the English Wikipedia and BookCorpus (800 million words), language From Wikipedia is not representative of everyday natural language since far less of the web consists of the same semi-structured well-linked structure. C4 takes the pre-training via real world natural language to something much more akin to reality and was used to pre-train Google’s T5 model.
C4 Clean Colossal Crawl Dataset is made up of a “colossal” petabyte sized crawl of billions of pages of The Common Crawl (huge samples of the “real web” since 2011), cleaned of boilerplate (swear words, javascript notifications, code, and other such distractions to remove “noise”). Again, the dataset was made available after cleaning for others to learn from.
Much NLP research has switched to passages and ranking
Passage retrieval and ranking has become one of the favourite areas of research over the past couple of years.
Retrieving parts of documents, AKA passage retrieval, or sub-document retrieval, in information retrieval is not new, as such. See the image below of an example information retrieval sub-document retrieval system patent from way back in 1999. (Evans, 1999)

We can also find IR research papers from 2008 and earlier on the topic of passage ranking, for example, “Re-ranking Search Results Using Document-Passage Graphs” (Bendersky et al, 2008), and there will certainly be many more.
We can also see passage retrieval was an active area of research in early 2018 with videos on YouTube:

You’ll see all of the “Features for Passage Ranking” in the screenshot above though were very much based around “counts” of entities, n-grams, query words (keywords), and words, words, words. Keywords everywhere.
But that was in June 2018 so there could be plenty of difference between the weights of the features that mattered in June 2018 and now.
…and that was before BERT.
BERT has been a big contributor to passage ranking research enthusiasm, and likely due to the aforementioned issues with BERt’s transformer architecture inefficiency and length constraints.
“As we’ve already discussed extensively, BERT has trouble with input sequences longer than 512 tokens for a number of reasons. The obvious solution, of course, is to split texts into passages.” (Lin et al, 2020)
But there is also another reason why passage ranking has become a popular machine learning activity for researchers with BERT.
MSMARCO’s Passage Ranking Task and Leaderboard
Since October 2018 a Passage Ranking task on MS MARCO and associated leaderboard has been present and attracted large numbers of entries from language researchers, including those at major tech companies such as Facebook, Google, Baidu and Microsoft.
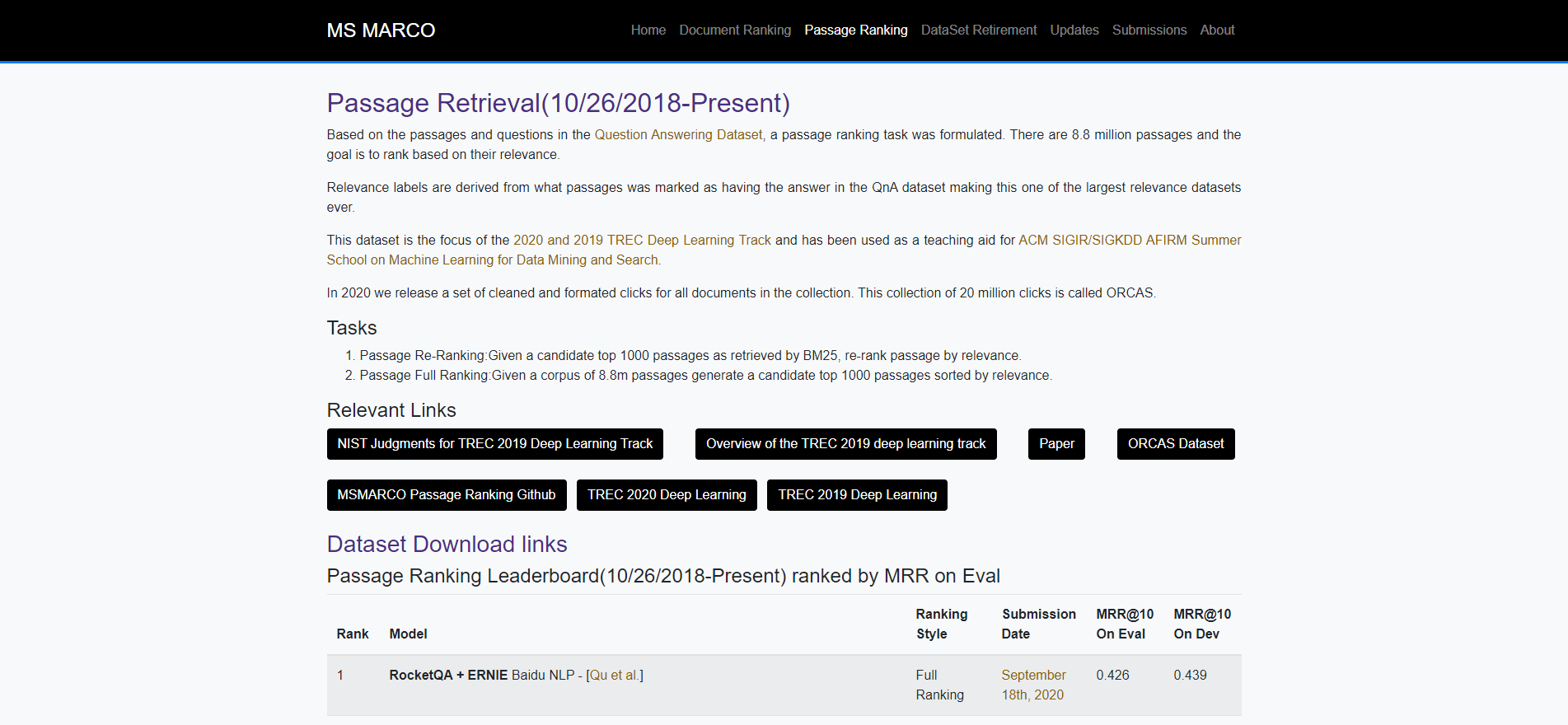
Indeed, only this past week, as MS MARCO announced on Twitter they were retiring their Question and Answering task leaderboard soon since there was limited progress in that area currently and emphasised they would be keeping the Passage Ranking task in place since that was where the focus was now.

In the MS MARCO Passage Ranking Task a dataset of 8.8 million passages is provided.
According to the MS MARCO Website:
“The context passages, from which answers in the dataset are derived, are extracted from real web documents using the most advanced version of the Bing search engine. The answers to the queries are human generated if they could summarize the answer.”
The Passage Ranking Task is split into two parts.
- Passage Re-Ranking: Given a candidate top 1000 passages as retrieved by BM25, re-rank passage by relevance.
- Passage Full Ranking: Given a corpus of 8.8m passages generate a candidate top 1000 passages sorted by relevance.
Some of the breakthroughs
And that now brings us nicely on to where the breakthroughs in ranking might be which were referenced by Google in Search On this past week.
It’s probably not just the passage ranking itself which is the breakthrough Google refers to, but rather breakthroughs in passage ranking and other “novel” findings discovered as a by-product of much activity in the passage retrieval research space, as well as new innovations from this research combined with current Google approaches to ranking (e.g. Learning to Rank (LeToR) with TensorFlow for example), plus plenty of developments within their own research teams separate to passage ranking specifically, and the industry improvements in AI overall.
For example, ROBERTA (more robustly trained BERT), and ELECTRA (Google, 2020) with its more efficient masking technique. There are other big breakthroughs too, which we will come to shortly.
In the same way the research community jumped on board with question and answering and natural language understanding overall, with iterative improvements resulting in BERT and friends, so too now big focus is on improving efficiencies and effectiveness in ranking, with a particular emphasis on passages.
Passages are smaller after all and within BERT’s constraints since it’s easy to chop a longer document up into several pieces.
And it does look like there are very significant developments.
In order to understand progress more fully we need to look at how ranking systems work as an industry standard overall, because it’s not quite as simple as a single fetch from the index it seems.
Two-stage ranking system
In two stage ranking there is first full ranking (the initial ranking of all the documents), and then re-ranking (the second stage of just a selection of top results from the first stage).
In information retrieval (and web search), two stage ranking is about firstly retrieving a large collection of documents using either a simple, classical retrieval algorithm such as BM25, or a query-expansion algorithm, a learning to rank algorithm, or a simple classifier approach.
A second stage is then carried out with greater precision and more resources over a list of top retrieved results from the first stage, likely using a neural re-ranker.
We do not have to go far through the research literature to find many confirmations of two (or multi stage) stage ranking systems as an industry standard.
“State-of-the-art search engines use ranking pipelines in which an efficient first-stage uses a query to fetch an initial set of documents from the document collection, and one or more re-ranking algorithms improve and prune the ranking.”
(Dai, 2019)
“Two step document ranking, where the initial retrieval is done by a classical information retrieval method, followed by a neural re-ranking model, is the new standard. The best performance is achieved by using transformer-based models as re-rankers, e.g., BERT.”
(Sekulic et al, 2020)
“Prior to two stage learning to rank a document set was often retrieved from the collection using a classical and simple unsupervised bag-of-words method, such as BM25.”
(Dang, Bendersky & Croft, 2013)
Note that BM25 stands for Best Match 25 Algorithm and is often favoured over the much talked about TF:IDF, and is so named because it was the 25th attempt at a particular ranking type algorithm which was the best match for the task of the time (trivia).
Whilst we can’t be sure Google and other search engines use BM25 of course, in any capacity, for those interested to learn ElasticSearch provides a good overview of the BM25 algorithm. However, it is still taught in many information retrieval lectures so relevant to some extent.
In the case of production search, it is likely something much more advanced than simply BM25 overall, but likely the more advanced and expensive resources are used in the second stage, rather than the initial fetch. Frederic Dubut from Bing confirmed Bing uses LambdaMART which is a Learning To Rank algorithm in much of its search engine (although he did not comment on whether this was in the first stage or second stage of ranking, or all ranking stages). Papers authored by researchers from Google state: “LambdaRank or its tree-based variant LambdaMART has been one of the most effective algorithms to incorporate ranking metrics in the learning procedure.” (Wang et al, 2018)
The main point is that it’s likely more powerful than systems used in research due to more resources (capacity / financial), however, the principles (and foundational algorithms) remain the same.
One caveat is that some commercial search engines may also be using “multi-stage” ranking neural models.
Referring to multi-stage ranking pipelines, Nogueria et al, wrote in 2019: “Known production deployments include the Bing web search engine (Pedersen, 2010) as well as Alibaba’s e-commerce search engine.”
They added further explained, “Although often glossed over, most neural ranking models today . . . are actually re-ranking models, in the sense that they operate over the output of a list of candidate documents, typically produced by a “bag of words” query. Thus, document retrieval with neural models today already uses multi-stage ranking, albeit an impoverished form with only a single re-ranking stage.”
Two stage indexing is not two stage ranking
A further clarification. We know of two stage indexing / rendering and Google has provided plenty of information on the two stage indexing situation, but that is not two stage ranking nor is it really two stages of indexing.
Two stage ranking is entirely different.
First stage of two stage ranking: full ranking
In Two Stage Learning to Rank (Dang et al, 2013), a list of documents are first ranked based on a learned “model of relevance” containing a number of features and query expansions then the model is trained to recall documents based on this “model of relevance” in first recall phases.
The first stage of two stage ranking is really about retrieving as many potentially relevant pages as possible. This first stage likely expands something like BM25, a tf (term frequency) based approach, with various query expansion terms and perhaps classification features since, according to Vang et al, 2013, “it is better to fetch more documents in the initial retrieval so as to avoid missing important and highly relevant documents in the second stage.” (Vang et al, 2013).
On the topic of “Learning to Rank” and expanding the query set to include query expansion, Vang et al write; “This query expanded model is thought to outperform simple bag-of-words algorithms such as BM25 significantly due to including more documents in the initial first stage recall.” (Vang et al, 2013).
Two stage learning to rank for information retrieval
On “Learning to Rank”:
“We first learn a ranking function over the entire retrieval collection using a limited set of textual features including weighted phrases, proximities and expansion terms. This function is then used to retrieve the best possible subset of documents over which the final model is trained using a larger set of query- and document-dependent features.”
(Vang et al, 2013)
Whilst the 2013 paper is older, all the more reason why progress will have improved upon this, since the two stage system is still ‘the industry standard.’
Second stage of two stage ranking: Reranking
From this list of retrieved documents a second pass is performed on a specified top-X number of documents, known as top-K from the retrieved document list and fine tuned for precision using machine learning techniques. You’ll often see in information retrieval papers the term P@K (Precision at K) which refers to the levels of precision in the top K against a “gold standard” or “ground truth” of relevance (K being a number, e.g. P@10 would mean the number of accurate results judged to meet the user’s information needs in relation to a query in the top 10 results retrieved).
A good explanation of evaluation metrics such as P@K (and there are a number of others) is provided in this information retrieval lecture slide.
The second stage of two stage ranking is where precision is much more important, and much more resource is expended, whilst also possibly adding further measures of relevance to really separate the gold in top ranks.
The importance of ranking more precisely those documents selected for inclusion in stage 2 is key, and precision in the highly ranked results, even more so, since the probability of these results being seen by search engine users is high.
As the adage goes, “only SEOs look beyond page two of search results”.
In “Two Stage Learning to Rank for Information Retrieval” Dang et al say:
“At run-time, in response to user queries, the Stage A model is used again to retrieve a small set of highly ranked documents, which are then re-ranked by the Stage B model. Finally, the re-ranked results are presented to the user”
(Dang et al, 2013)
To summarize, efficiency and effectiveness combined are the main driver for two stage ranking processes. Use the most computationally expensive resources on the most important documents to get the greater precision because that’s where it matters most. Full ranking is stage one with reranking as stage two for improvements on the top-K retrieved from the full collection.
As an aside, it is also probably why Google’s Danny Sullivan said in a May tweet, “If you are in the top 10 you are doing things right.”
Since, the top 10 is likely the most important part of Top-K in the re-ranked “precision” stages, and maximum features and precision ‘learning’ will have been undertaken for those results.
Improving the second stage of ranking (precision) has been the focus
Given the importance of the second stage of ranking for precision the majority of research into ranking improvements focuses on this stage – the reranking stage.
Making the BEST use of BERT, for now
We know BERT in its 2018 / 2019 format was limited. Not least by sequence length / context window limitations, as well as expense, despite smaller models appearing.
How to make BERT something better than a “nice to have” dealing only with the most nuanced of disambiguation needs in web search at sentence level, and into something usable in a meaningful capacity? Something which many researchers could jump on board with too?
BERT repurposed as a passage ranker and re-ranker
Aha… BERT As a passage ranker.
Once more to reinforce BERT’s limitations and ideal current use: “BERT has trouble with input sequences longer than 512 tokens for a number of reasons. The obvious solution, of course, is to split texts into passages,” per Lin et al this year.
One of the biggest breakthrough areas of research and development has been in the repurposing of BERT as a reranker, initially by Nogueria and Cho in 2019, in their paper “Passage Reranking with BERT,” and then others.
As Dia, 2019, points out in a 2019 paper: “BERT has received a lot of attention for IR, mainly focused on using it as a black-box re-ranking model to predict query-document relevance scores.”
On their 2019 paper “Passage Reranking with BERT,” Nogueira & Cho said they “describe a simple re-implementation of BERT for query-based passage re-ranking. Our system is the state of the art on the TREC-CAR dataset and the top entry in the leaderboard of the MS MARCO passage retrieval task, outperforming the previous state of the art by 27% (relative) in MRR@10.”
“We have described a simple adaptation of BERT as a passage re-ranker that has become the state of the art on two different tasks, which are TREC-CAR and MS MARCO.”
I spoke to Dr Mohammad Aliannejadi, author of several papers in the field of information retrieval and a post-doctoral researcher in Information Retrieval at The University of Amsterdam, exploring natural language, mobile search and conversational search.
“At the moment, BERT as a reranker is more practical, because full ranking is very hard and expensive,” Dr Aliannejadi said. “And, the improvements in effectiveness does not justify the loss of efficiency.”
He continued, “One would need a lot of computational resources to run full-ranking using BERT.”
BERT and passages
Subsequently, passage re-ranking (and increasingly passage re-ranking with BERT), is now amongst the favourite 2020 topics of the information retrieval and machine learning language research world, and an area where significant progress is being made, particularly when combined with other AI research improvements around efficiency, scale and two stage ranking improvements.
Passages and BERT (for the moment) go hand in hand
One only has to look at the table of contents in Lin et al’s recently published book “Pretrained Transformers for Text Ranking: BERT and Beyond” (Lin et al, 2020) to see the impact passage ranking is having on the recent “world of BERT,” with 291 mentions of passages, as Juan Gonzalez Villa pointed out:

Google research and passage ranking / reranking
Naturally, Google Research have a team which has joined the challenge to improve ranking and reranking with passages (Google TF-Ranking Team), competing on MSMARCO’s leaderboard, with an iteratively improving model (TFR-BERT), revised a number of times.
TFR-BERT is based around a paper entitled “Learning-to-Rank with BERT in TF-Ranking” (Han et al, 2020), published in April and with its latest revision in June 2020. “In this paper, we are focusing on passage ranking, and particularly the MS MARCO passage full ranking and re-ranking tasks,” the authors wrote.
“…we propose the TFR-BERT framework for document and passage ranking. It combines state-of-the-art developments from both pretrained language models, such as BERT, and learning-to-rank approaches. Our experiments on the MS MARCO passage ranking task demonstrate its effectiveness,” they explained.
TFR-BERT – BERT-ensemble model — Google’s ensemble of BERTs
Google Research’s latest BERT’ish model has evolved into an ensemble of BERTs and other blended approaches – a combination of parts of other models or even different full models, methods and enhancements grouped.
Many BERTs as passage rankers and rerankers are actually ‘SuperBERT’s
Since much of the code in the BERT research space is open source, including plenty from major tech companies such as Google, Microsoft and Facebook, those seeking to improve can build ensemble models to make “SuperBERT.”
2020 has seen a wave of such “SuperBERT” models emerge in the language model space, and across the leaderboards.
The use of BERT in this way is probably not like the BERT that was used in just 10% of queries. That was probably for simple tasks such as disambiguation and named entity determination on very short pieces of text and sentences to understand the difference between two possible meanings in the words in queries. There is actually a BERT called SentenceBERT from a paper entitled “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks” (Reimers & Gurevych, 2019), but this does not mean that SentenceBERT was used in the 10% of queries mentioned in 2019 of course.
The main point is, passage ranking with BERT is BERT completely repurposed to add contextual meanings to a training set of passages in two stages. Full ranking and then re-ranking, and probably quite different in use to the 10% implementation in production search from 2019.
On the subject of “SuperBERTs” an SEO community friend (Arnout Hellemans) refers to my dog BERT as “SuperBERT,” so it seemed an appropriate excuse to add a picture of her.

Learning-to-rank with BERT in TF-Ranking (han et al, 2020)
Han et al, 2020, explain the additional integrations which take the original BERT and TF-Ranking model to an ensemble which combines ELECTRA and RoBERTa with BERT and TF-Ranking approaches through five different submissions to the MS MARCO passage ranking leaderboard.
TF-Ranking is described as a “TF-Ranking: A Scalable TensorFlow Library for Learning-to-Rank” (Pasumarthi et al, 2019)
“This paper describes a machine learning algorithm for document (re)ranking, in which queries and documents are firstly encoded using BERT, and on top of that a learning-to-rank (LTR) model constructed with TF-Ranking (TFR) is applied to further optimize the ranking performance. This approach is proved to be effective in a public MS MARCO benchmark.”
(Han et al, 2020)
“To leverage the lately development of pre-trained language models, we recently integrated RoBERTa and ELECTRA.”
(Han, Wang, Bendersky, Najork, 2020)
Whilst ELECTRA was published by Google, as you may recall, RoBERTa was published by Facebook.
But we can also see an additional element mentioned as well as RoBERTa, BERT, TF-Ranking and ELECTRA from the paper extract. Mention of DeepCT.
According to the “Learning-to-rank with BERT in TF Ranking” paper:
“The 5 Submissions of Google’s TFR-BERT to the MS MARCO Passage Ranking Leaderboard were as follows:
- Submission #1 (re-ranking): TF-Ranking + BERT (Softmax Loss, List size 6, 200k steps)
- Submission #2 (re-ranking): TF-Ranking + BERT (Ensemble of pointwise, pairwise and listwise losses)
- Submission #3 (full ranking): DeepCT Retrieval + TF-Ranking BERT Ensemble
- Submission #4 (re-ranking): TF-Ranking Ensemble of BERT, RoBERTa and ELECTRA
- Submission #5 (full ranking): DeepCT + TF-Ranking Ensemble of BERT, RoBERTa and ELECTRA
Whilst early submission were simply BERT and TF-Ranking (TensorFlow Ranking), with RoBERTa and ELECTRA added later to another leaderboard submission, the biggest gains seem to be the adding of DeepCT with sharp improvements between submissions 3 and 5 on the Full Ranking Passage Ranking task, although Deep-CT is not mentioned on the paper abstract.

Google’s SuperBERT ensemble model (evolved from TFR-BERT) is performing well on MS MARCO both full ranking and reranking passage ranking leaderboard.
You can see it here currently (October 2020) at position 5 in the image below entitled:
DeepCT + TF-Ranking Ensemble of BERT, ROBERTA and ELECTRA (1) Shuguang Han, (2) Zhuyun Dai, (1) Xuanhui Wang, (1) Michael Bendersky and (1) Marc Najork – 1) Google Research, (2) Carnegie Mellon – Paper and Code
Also note Dai has now been added to the Google TF-Ranking team members on the leaderboard submission from April onwards, although not listed on the original paper.

Digging in to the body of the “Learning-to-rank with BERT in TF-Ranking” paper we see the following: “We discovered that DeepCT helps boost the re-ranking of BM25 results by a large margin, and a further combination of both BM25 and DeepCT re-ranked lists brings additional gains.”
Looking at the model revisions which include DeepCT specifically, Han et al continue: “With Submission #3, we achieved the second best overall performance on the leaderboard as of April 10, 2020. With the recent Submission #5, we further improved our previous performance, and obtained the third best performance on the leaderboard as of June 8, 2020 (with tens of new leaderboard submissions in between)”
Also, it’s important to remember the sharp improvements are on the Full Ranking task, rather than the ReRanking task. Note both of the Full Ranking tasks include DeepCT, but the ReRanking tasks do not.
- 5 – DeepCT + TF-Ranking Ensemble of BERT, ROBERTA and ELECTRA (1) Shuguang Han, (2) Zhuyun Dai, (1) Xuanhui Wang, (1) Michael Bendersky and (1) Marc Najork – 1) Google Research, (2) Carnegie Mellon – Paper and Code. Full Ranking June 2, 2020
- 11 – DeepCT Retrieval + TF-Ranking BERT Ensemble 1) Shuguang Han, (2) Zhuyun Dai, (1) Xuanhui Wang, (1) Michael Bendersky and (1) Marc Najork – (1) Google Research, (2) Carnegie Mellon University – Paper [Han, et al. ’20] Code. Full Ranking April 10, 2020
- 14 – TF-Ranking Ensemble of BERT, ROBERTA and ELECTRA (1) Shuguang Han, (2) Zhuyun Dai, (1) Xuanhui Wang, (1) Michael Bendersky and (1) Marc Najork – 1) Google Research, (2) Carnegie Mellon – Paper and Code. ReRanking June 2, 2020
- 25 – TF-Ranking + BERT(Ensemble of pointwise, pairwise and listwise losses)TF-Ranking team (Shuguang Han, Xuanhui Wang, Michael Bendersky and Marc Najork) of Google Research – Paper [Han, et al. ’20] and [Code]. ReRanking March 30, 2020
DeepCT
DeepCT appears to be a secret sauce ingredient responsible for some significant gains in quick succession in the MS MARCO full ranking task leaderboard for the Google TF-Ranking Research team. Recall the full ranking stage relates to the first stage of the two stage task.
In the case of MS MARCO it’s the ranking of the 8.8 million passages provided, with re-ranking relating to fine-tuning the top 1000 results retrieved from that initial first ranking stage.
So DeepCT is the difference to the first stage full ranking here, which is the first stage.
So just what is DeepCT and could it be significant to more than just passage ranking leaderboards?
DeepCT stands for “Deep Contextualized Term Weighting Framework” and was proposed in a paper entitled “Context Aware Term Weighting For First Stage Passage Retrieval.” (Dai, 2020)
The Inventor of DeepCT, Dai, describes the framework as: “DeepCT, a novel context-aware term weighting approach that better estimates term importance for first-stage bag-of-words retrieval systems.”
But that doesn’t really do it justice since there is plenty more to DeepCT than one first suspects.
Greater context in passages, an alternative to tf (term frequency) and improved first stage ranking with DeepCT
Dai, DeepCT’s inventor, shows DeepCT not only improves first stage ranking results and adds a context-awareness to terms in passages, but also when combined with BERT Re-ranker (in the second stage) (Bert repurposed as a re-ranker by Nogueria and Cho, 2019) is very effective in both improving precision in “intent-aligned” ranking results for passages, coupled with efficiency, and shows potential for scale to production environments, without much modification to existing architectures.
Indeed, DeepCT seems very effective in passage-indexing which is a ranking process, but in DeepCT’s case there is an “index” element involved, but not as we know it in the SEO space (and papers on the topic of DeepCT do reference passage indexing).
At the moment DeepCT’s use is limited to the default BERT 512 tokens but that is ideal for passages, and passages are parts of documents of anyway since they really are just chopped up documents. Therefore, normal documents become a group of passages with sequences usually well within the 512 token scope limitations of BERT.
To reiterate Lin’s quote from earlier: “As we’ve already discussed extensively, BERT has trouble with input sequences longer than 512 tokens for a number of reasons. The obvious solution, of course, is to split texts into passages.”
Why is DeepCT so significant?
Whilst DeepCT is limited currently within the constraints of the 512 token limitations of BERT, and therefore passages, DeepCT could constitute a ranking “breakthrough.”
Importantly, DeepCT not only seeks to provide a context-aware passage ranking solution but also begins to address some long standing information retrieval industry-wide issues around long established ranking and retrieval models, and systems. These developments could extend far beyond the limited focus of DeepCT and the passage indexing update we are concerned with today, particularly as other improvements around efficiency and context windows begin to be addressed in BERT-like systems and transformers.
The problem with term frequency (tf) in passages
The first issue DeepCT seeks to address relates to the use of tf (term frequency) in first stage ranking systems.
As Dai points out: “State-of-the-art search engines use ranking pipelines in which an efficient first stage uses a query to fetch an initial set of documents, and one or more re-ranking algorithms to improve and prune the ranking. Typically the first stage ranker is a bag-of-words retrieval model that uses term frequency (tf ) to determine the document specific importance of terms. However, tf does not necessarily indicate whether a term is essential to the meaning of the document, especially when the frequency distribution is flat, e.g., passages. In essence, tf ignores the interactions between a term and its text context, which is key to estimating document-specific term weights.”
Dai suggests a word “being frequent” does not mean “being relevant” in a given passage content, whilst also confirming the fundamental role bag-of-words approaches has had in legacy and at the same time highlighting the shortcomings of current systems.
“The bag-of-words plays a fundamental role in modern search engines due to its efficiency and ability to produce detailed term matching signals,” says Dai. “Most bag-of-words representations and retrieval models use term weights based on term frequency (tf ), for example tf.idf and BM25. However, being frequent does not necessarily lead to being semantically important. Identifying central words in a text also requires considering the meaning of each word and the role it plays in a specific context.”
Dai describes frequency-based term weights as a “crude tool” (albeit they have been a huge success), since tf does not differentiate between words which are central to the overall text meaning and words which are not, and particularly so in passages and sentences, and proposes a need to understand word’s meaning within the context of text content as a “critical problem.”
“Frequency-based term weights have been a huge success, but they are a crude tool,” Dai and Callan wrote in 2019. “Term frequency does not necessarily indicate whether a term is important or central to the meaning of the text, especially when the frequency distribution is flat, such as in sentences and short passages”
Dai further noted, “To estimate the importance of a word in a specific text, the most critical problem is to generate features that characterize a word’s relationships to the text context.”
The problem with multi stage ranking systems
The second problem relates to efficiencies and computational costs in first stage ranking systems, and subsequently the focus of deep-learning research being concentrated on re-ranking (the fine-tuning, second, or later stages of ranking in the case of multi-stage ranking systems), in recent times, due to computational expenses in deep learning, rather than full ranking (the initial first stage).
“Most first-stage rankers are older-but-efficient bag-of-words retrieval models that use term frequency signals, and much of the research work on ranking has been focused on the later stages of ranking – the fine-tuning stages,” said Dai in 2019.
Dai suggests the computational (and subsequently financial) costs associated with first stage ranking limits the use of complex deep learning which might otherwise overcome the “lack of central” focus on terms in relation to other surrounding text in passages (word’s context).
“Classic term frequency signals cannot tell whether the text is centered around a term or just mentions that term when discussing some topic. This issue is especially difficult in first-stage full-collection ranking, where complex features and models are too expensive to apply,” Dai wrote.
We know improvements to the first stage of ranking was a primary rationale for the research undertaken in “Two Stage Learning to Rank in Information Retrieval.” Even then they acknowledge the vast majority of research into ranking is on the second stage (re-ranking, hence their work motivation was designed to improve the first stage with a better initial yield using e.g. query expansion techniques for better fine tuning (Vang et al, 2013).
There are likely many others who have sought to address this first stage ranking improvements further as well, but the primary focus has certainly been on stage two for the aforementioned reasons around the importance of the highly ranked top-K results probability to be seen, combined with computational / financial expense.
This focus on second stage results has also continued even as BERT was repurposed as a passage and researchers were enthused to follow the BERT re-ranking path for passages.
Improving the first stage of ranking AND gaining word’s context in passages too
DeepCT seeks to make inroads to solve both of these issues simultaneously.
First stage ranking improvements with DeepCT
Dai’s work with DeepCT focuses on the first stage of retrieval, whilst also aiding downstream re-ranking stages significantly.
“Most of the prior neural-IR research, including recent research on leveraging BERT for IR, focused on re-ranking stages due to the complexity of neural models. Our work adds the ability to improve existing first-stage rankers. More accurate first stage document rankings provide better candidates for downstream re-ranking, which improves end-to-end accuracy and/or efficiency.”
“Although much progress has been made toward developing better neural ranking models for IR, computational complexity often limits these models to the re-ranking stage. DeepCT successfully transfers the text understanding ability from a deep neural network into simple signals that can be efficiently consumed by early-stage ranking systems and boost their performance.”
(Dia, 2020)
A new alternative to term frequency using BERT – tfDeepCT
In this first stage of ranking, Dai also focuses on moving toward more contextual understanding of words in passages than merely their counts(tf).
Dai proposes an alternative to tf term frequency with a part of the Deep Contextualized Term Weighting Framework called “tfDeepCT.”
Instead of merely counting term frequency, tfDeepCT identifies a deep contextual meaning and context for the words in a passage.
Using BERT representations, DeepCT assigns an importance score to words based on their centrality and importance to the topic given their context in a passage. DeepCT assigns a higher weight to important terms and suppresses low importance or off-topic terms in the passage.
These weights are then assigned to an ordinary inverted index with no new posts added but with a replacement for tf called tfDeepCT (the weighted terms based on their contextual importance in a passage as deemed by BERT’s transformer attention architecture).
DeepCT-Index
This is called DeepCT-Index.
“tfDeepCT is used to replace the original tf in the inverted index. The new index, DeepCT-Index, can be searched by mainstream bag-of-words retrieval models like BM25 or query likelihood models. The context-aware term weight tfDeepCT is expected to bias the retrieval models to central terms in the passage, preventing off-topic passages being retrieved. The main difference between DeepCT-Index and a typical inverted index is that the term weight is based on tfDeepCT instead of tf. This calculation is done offline.”
(Dai, 2020)
IMPORTANT – This does not mean that this is a new document indexing situation. Passage indexing is about passage ranking. On the subject of the forthcoming passage indexing overall, Google has made it clear the new passage indexing changes ahead relate to a ranking change, and not an indexing change to documents. Passages are not going to be indexed separately as well as, or instead of, documents according to Google’s recent clarifications.
DeepCT-Index (if used) appears to propose simply adding alternative ranking weights to the existing index but which replaces tf with tfDeepCT for passages.
Dai also makes it clear in the literature around DeepCT that “No new posting lists are created.”
But also refers to the use of DeepCT for passage indexing: “Section 3 describes the Deep Contextualized Term Weighting framework (DeepCT), its use for passage indexing (DeepCT-Index).”
IMPORTANT — I’d like to caveat this by saying DeepCT-Index is a central piece to the DeepCT framework in the literature. Google Research has acknowledged the use of DeepCT in their research paper “Learning to Rank with BERT in TF-Ranking” in both the acknowledgements section and throughout the paper.
“We would like to thank Zhuyun Dai from Carnegie Mellon University for kindly sharing her DeepCT retrieval results.”
(Han et al, 2020)
DeepCT is also part of the current research model submissions for full ranking currently submitted to MS MARCO passage ranking leaderboard.
However, it does not mean it is in production, nor will be. but it does show promise and a new and interesting direction, not only for the use of BERT with passage ranking for greater contextual search, but for more efficient and effective “context-aware,” improved search overall, since if implemented it will likely lead to far greater resources at scale being used on the whole end-end-end ranking system.
Even more so given the significant results received lately in the passage ranking leaderboards and the results reported in the papers presented by Dai around the DeepCT Framework. The inventor of DeepCT has also now joined the Google TF-Ranking team and is listed on the lately submissions of models on the MS MARCO passage ranking leaderboards.
Some of the legacy challenges which appear to be overcome by DeepCT in the results in both the current TFR-BERT research model and in Dai’s papers could be seen as “a breakthrough in ranking.”
Recall from last week’s Search On event Google’s Prabhakar Raghavan, when announcing “passage indexing” and saying, “We’ve recently made a breakthrough in ranking.”
DeepCT kind of sounds like it could perhaps be quite a significant breakthrough in ranking.
So how does DeepCT work?
Instead of using term frequency in the first stage of information retrieval / ranking, DeepCT appears to propose to replace term frequency (TF) with tfDeepCT. With DeepCT, word’s contextual meaning is identified as an alternative to simply counting the number of times a keyword is mentioned in a passage, using deep contextualized representations through BERT transformers.
Important words in context are weighted more even if they are mentioned less and an importance score is assigned given the context of the word in a paragraph or particular context, since words have different meanings at different times and in different scenarios. More important words to the passage and the topic (central terms) are scored with a higher importance score, whereas words which are less important are given a lower score and / or suppressed entirely if they are off-topic or contribute nothing to the importance of the passage.
A strong bias is generated towards words which are “on-topic” with a suppression of “off-topic” words.
To quote Ludwig Wittgenstein in 1953, “The meaning of a word is its use in the language.”
Whilst some commentary has been added by me to the content to follow I did not want to distort the meanings in the technical explanations of DeepCT due to my limited understanding on the new and complex topic of DeepCT, therefore primarily DeepCT explanations are quotes from Dai’s paper.
DeepCT, tfDeepCT and DeepCT-Index
The fundamental parts of DeepCT seem to be:
- tfDeepCT – An alternative to term frequency which replaces tf with tfDeepCT
- DeepCT-Index – Alternative weights added to an original index, with no additional postings. Weighting is carried out offline, and therefore does not add any latency to search engine online usage
- DeepCT-Query – An updated bag-of-words query which has been adapted using the deep contextual features from BERT to identify important terms in a given text context or query context.
According to Dia:
“We develop a novel DeepCT-Index that offline weights and indexes terms in passage-long documents. It trains a DeepCT model to predict whether a passage term is likely to appear in relevant queries. The trained model is applied to every passage in the collection. This inference step is query-independent, allowing it to be done offline during indexing. The context-based passage term weights are scaled to tf -like integers that are stored in an ordinary inverted index that can be searched efficiently by common first-stage retrieval models”
“Analysis shows the main advantage of DeepCT over classic term weighting approaches: DeepCT finds the most central words in a text even if they are mentioned only once. Non-central words, even if mentioned frequently in the text, are suppressed. Such behavior is uncommon in previous term weighting approaches. We view DeepCT as an encouraging step from “frequencies” to “ meanings.”
(Dia, 2020)
Dai, highlights the novel nature and effectiveness of DeepCT:
“Analysis shows that DeepCT’s main advantage is the ability to differentiate between key terms and other frequent but non-central terms.”… “DeepCT-Index aggressively emphasizes a few central terms and suppresses the others.”
“When applied to passages, DeepCT-Index produces term weights that can be stored in an ordinary inverted index for passage retrieval. When applied to query text, DeepCT-Query generates a weighted bag-of-words query. Both types of term weight can be used directly by typical first-stage retrieval algorithms. This is novel because most deep neural network based ranking models have higher computational costs, and thus are restricted to later-stage rankers.”
“This paper presents a novel approach that runs DeepCT at offline index time, making it possible to use it in first-stage retrieval where efficiency is crucial. Our approach applies DeepCT over each passage in the corpus, and stores the context-aware term weights in an ordinary inverted index to replace tf. The index can be searched efficiently using common bag-of-words retrieval models such as BM25 or statistical query likelihood models.”
(Dai, 2020)
To emphasise the efficiency of DeepCT, tfDeepCT and DeepCT-Index
“No new posting lists are created, thus the query latency does not become longer. To the contrary, a side-effect …is that tfDeepCT of some terms becomes negative, which may be viewed as a form of index pruning.”
(Dai, 2020)
DeepCT-Index could make neural ranking practical “end-to-end?”
It seems computational expense even when using BERT in the re-ranking stage and the latency issues caused are a significant bottleneck to using them at scale in production environments. Dai stresses the huge benefit to improving the first stage with DeepCT, and thereby reducing the burden at the re-ranking stage.
The main point is, improving the first stage has the potential to both dramatically improve the first stage and the second stage. Indeed, greatly improved first stage might well reduce the need for second stages and multi-stages dramatically, Dai claims, and compares DeepCT’s performance to a standard BM25 first-stage ranking system.
“The high computational cost of deep neural-based re-rankers is one of the biggest concerns about adopting them in online services. Nogueira et al. reported that adding a BERT Re-Ranker, with a re-ranking depth of 1000, introduces 10× more latency to a BM25 first-stage ranking even using GPUs or TPUs. DeepCT-Index reduces the re-ranking depth by 5× to 10×, making deep neural based re-rankers practical in latency-/resource-sensitive systems”
(Dai, 2019)
This development is as a result of DeepCT not adding any latency to the search system since nothing is added further per say.
“DeepCT-Index does not add latency to the search system. The main difference between DeepCT-Index and a typical inverted index is that the term importance weight is based on TFDeepCT instead of TF.”
(Dai, 2020)
DeepCT results
Dai, emphasises the uncommon results achieved using DeepCT and in particular as an alternative to term frequency measures, which have been in use for many years, and makes the case that the results illustrated by DeepCT clearly show other term importance signals can be generated beyond term frequency.
“It is uncommon in prior research for a non-tf term weighting method to generate such substantially better rankings. These results show that tf is no longer sufficient, and that better term importance signals can be generated with deep document understanding.”
(Dai, 2020)
But not only is DeepCT impressive for first stage ranking but the improved first stage results naturally feed forward to better second stage rankings, whilst also finding the central meanings in passages using tfDeepCT and DeepCT-Index.
“Experimental results show that DeepCT improves the accuracy of popular first-stage retrieval algorithms by up to 40%. Running BM25 on DeepCT-Index can be as effective as several previous state-of-the-art rankers that need to run slow deep learning models at the query time. The higher-quality ranking enabled by DeepCT-Index improves the accuracy/efficiency tradeoff for later-stage re-rankers. Analysis shows that DeepCT is capable of finding the central words in a text even if they are mentioned only once. We view DeepCT as an encouraging step from “frequencies” to “ meanings.”
(Dai, 2020)
Here are some of the results of the capabilities from the DeepCT experiments as a contextual aware first stage ranker curated from various parts of the DeepCT (Dai, 2020) papers:
- A BM25 retrieval on DeepCT-Index can be 25% more accurate than classic tf -based indexes, and are more accurate than some widely-used multi-stage retrieval systems.
- These results indicate that it is possible to replace some pipelined ranking systems with a single-stage retrieval using DeepCT-Index.
- A single-stage BM25 retrieval from DeepCT-Index was better than several reranking pipelines
- It is more accurate than feature based LeToR (Learning to Rank), a widely used reranking approach in modern search engines
- The improved first stage ranking further benefits the effectiveness and efficiency of downstream re-rankers.
- DeepCT-Index reduces the re-ranking depth by 5× to 10×, making deep neural based re-rankers practical in latency-/resource-sensitive systems
- Ranking with DeepCt in the first stage, provided more relevant passages to a reranker for better end to end ranking.
- DeepCT had higher recall at all depths, meaning a ranking from DeepCT provided more relevant passages to a reranker.
- For BERT ReRanker, DeepCT enabled it to achieve similar accuracy using much fewer passages…meaning that the reranker can be 5-10× more efficient. In summary
- DeepCT puts relevant passages at the top, so that downstream rerankers can achieve similar or higher accuracy with much smaller candidate sets, leading to lower computational cost in the retrieval pipeline
A breakthrough in first stage ranking using word’s context rather than just keyword frequencies or similar?
The results achieved with DeepCT could be seen as “a breakthrough in ranking.” Certainly DeepCT represents a step toward improvement in “end-to-end-ranking” (albeit for passages at the moment), and could surely be seen as progress, particularly when coupled with a breakthrough in identifying the contextual meanings using deep learning representations with the ability to simply add weights to the current tf terms and replacing them with tfDeepCT?
And Dai does seem to shake things up in her claims effectively saying tf is no longer sufficient and it’s time for a revisit to the current systems of old:
She makes the case that term frequency is not sufficient any more.
“Results from this paper indicate that tf is no longer sufficient. With recent advances in deep learning and NLP, it is time to revisit the indexers and retrieval models, towards building new deep and efficient first stage rankers.”
(Dai, 2020)
And summarises her case as follows:
“The higher-quality ranking enabled by DeepCT-Index improves the accuracy/efficiency tradeoff for later-stage re-rankers. A state-of-the-art BERT-based re-ranker achieved similar accuracy with 5× fewer candidate documents, making such computation-intensive re-rankers more practical in latency-/resource-sensitive systems. Although much progress has been made toward developing better neural ranking models for IR, computational complexity often limits these models to the re-ranking stage. DeepCT successfully transfers the text understanding ability from a deep neural network into simple signals that can be efficiently consumed by early-stage ranking systems and boost their performance. Analysis shows the main advantage of DeepCT over classic term weighting approaches: DeepCT finds the most central words in a text even if they are mentioned only once. Non-central words, even if mentioned frequently in the text, are suppressed. Such behavior is uncommon in previous term weighting approaches. We view DeepCT as an encouraging step from “frequencies” to “meanings.”
“There is much prior research about passage term weighting, but it has not been clear how to effectively model a word’s syntax and semantics in specific passages. Our results show that a deep, contextualized neural language model is able to capture some of the desired properties, and can be used to generate effective term weights for passage indexing. A BM25 retrieval on DeepCT-Index can be 25% more accurate than classic tf -based indexes, and are more accurate than some widely-used multi-stage retrieval systems. The improved first stage ranking further benefits the effectiveness and efficiency of downstream re-rankers.”
(Dai, 2020)
Back to Google’s passage indexing announcement
Let’s just revisit the key message from Google during the Search On event about passage-indexing: “With our new technology, we’ll be able to better identify and understand key passages on a web page. This will help us surface content that might otherwise not be seen as relevant when considering a page only as a whole….”
Which sounds similar to Dai: “A novel use of DeepCT is to identify terms that are central to the meaning of a passage, or a passage-long document, for efficient and effective passage/short-document retrieval.”
Back to the Search On event: “This change doesn’t mean we’re indexing individual passages independently of pages. We’re still indexing pages and considering info about entire pages for ranking. But now we can also consider passages from pages as an additional ranking factor….”
Which may be this (but on the same index), as a weighted contextual ranking factor applied at a passage level within the current document index.
Remember Dai, 2020, makes it clear no further postings are created in DeepCT-Index. Nothing changes to the index, but perhaps different contextual measures are added using BERT and perhaps tfDeepCT adds that context. (Note, I have no proof of this beyond the literature and the current TFR-BERT model submissions):
“This paper also presents a novel approach that runs DeepCT at offline index time, making it possible to use it in first-stage retrieval where efficiency is crucial. Our approach applies DeepCT over each passage in the corpus, and stores the context-aware term weights in an ordinary inverted index to replace tf. The index can be searched efficiently using common bag-of-words retrieval models such as BM25 or statistical query likelihood models.”
(Dai, 2019)
What could be the significance of DeepCT to passage-indexing?
Well, if DeepCT were used, it may just mean those “counts of keywords” and “some of the counts of x, y and z” in the features referred to in the 2018 video on passage retrieval may not be quite as important as SEOs hoped, when passage indexing rolls out later this year since DeepCT (if it is used), might take a different approach to those in YouTube videos from 2018 on passage retrieval.
I mean, seriously, how many entities and keywords could one stuff into a passage in text anyway without it being spammy?
That’s not to say things from 2018 are not important, because there is also work going on with BERT and knowledge bases which might impact, and furthermore the work on T5, by Google explored whether models like BERT could augment knowledge in its parameters from simply a large crawl of the web. As too, does some other work of Dai, in HDCT (Dai, 2019) which is another framework for passage retrieval and indexing. There Dai, does appear to give weights to the positions of passages in a document and also the passage deemed the “best” in a document too. Titles and inlinks are seen as indicators of importance too in HDCT.
But Google has not chosen to include HDCT in their submitted TFR-BERT and I suspect (opinion) that it is related to the potential for spam in models which merely weight terms by how many inlinks and keywords in page titles. But, that is just my opinion.
If DeepCT is used, it really will be about providing a rich depth of compelling and authoritative content with focus and structure in sections on a page. The semantic headings and page title will likely also help of course, but after all there is only so much one can do with those features to differentiate oneself from competitors.
One other point
You’ll also notice many of the 2018 videos on passage retrieval are around the topic of “Factoid Search,” which is not the same as “open domain answers,” which are longer, less simple to provide answers to, and much more nuanced.
The answers to factoid questions are easy to find in knowledge bases compared with nuanced complex open-domain questions such as the one in the passage indexing example provided by Google. Those types of questions require understanding of the true context of each work, and likely only met by contextual term understanding models such as BERT which did not appear until late 2018 in the first place. Answering more complex open domain questions might well constitute the 7% of queries mentioned as the starting point during the Search On event since this is not high.

If DeepCT (or future iterations of DeepCT), is used in production search passage ranking it could have the potential to bring huge efficiencies to first stage ranking and improved second stage ranking overall in search engines (particularly, as with all things, it will be built upon and improved further by the research world).
DeepCT, or innovations similar to DeepCT could also be the secret sauce which take search engines truly from “keyword counts (tf)” in first stage retrieval to much more capable of understanding word’s meaning. Initially in passages, but then… who knows?
We’ve heard already about the efficiency problems involved with first stage ranking and the need to only use deep learning at the later stages as a re-ranker, but things may be about to change. Furthermore, search engines have relied on first stage rankings involving systems such as term frequency for many years according to plenty of literature, and that too may be about to change.
That’s not to say a passage, or document without a single relevant word is going to rank easily, because it “probably” won’t, although we do know now that it’s not just words on a page which add value.
BERT everywhere
Whilst we know now BERT is used in nearly all queries, the use of BERT for passage indexing and the initial 7% of queries, could be more prevalent, and increasingly so into the future, if, and when, passage indexing expands to impact more queries.
BERT everywhere would likely be a prerequisite if DeepCT were used in order to build the tfDeepCT embeddings in the index.
That said, BERT and other neural networks are likely not always needed anyway on very short or navigational queries.
There’s not a lot of natural language understanding needed for the query “red shoes” or “ASOS dresses,” after all, since the intent is usually quite clear, aside from whether the query requires different media to a simple ten blue links (e.g. images).
But, as mentioned DeepCT may not even be in the production mix
At this stage however, Google may simply be happy enough with BERT as a re-ranker on long open-domain questions rather than factoid questions which are easier to answer, but that doesn’t really feel like “a breakthrough in ranking” since passage ranking has been around for quite some time, albeit the re-ranking element is fairly recent.
In any event, even without DeepCT, given the overwhelming use of BERT and BERT-like systems in passage re-ranking it is “probably” part of the forthcoming passage update.
So, where to next and why just 7% of queries?
So, we know BERT was being used, at least in part for 10% of queries, and it was probably in the second stage of ranking (re-ranking) because of computational costs, and probably only on the most nuanced of queries, and probably not as a passage re-ranker or ranker but as a sentence level disambiguation task tool and text summarization (featured snippets).
We know that neural ranking approaches with BERT and other deep neural networks have been too computationally expensive to run at the first stage of search across the search industry and there have been limitations on the number of tokens BERT can work with – 512 tokens. But 2020 has been a big year and the developments to scale natural language machine learning attention systems have included such innovations as Big Bird, Reformer, Performers and ELECTRA plus T5 to test the limitations of transfer learnings, making huge inroads. And those are just projects Google is involved with in some capacity. Not to mention the other big tech search companies.
Whilst much of this work is very new, a year is a long time in the AI NLP research space so expect huge changes by this time next year.

Regardless of whether DeepCT is used in the forthcoming production search passage indexing feature, it is highly likely BERT has a strong connection to the change, given the overwhelming use of BERT (and friends) as a passage reranker in the research of the past 12 months or so.
Passages, with their limited number of tokens, if taken as stand alone pieces, on can argue, by their nature, limit the effectiveness of keywords alone without contextual representation, and certainly, a keyword stuffed passage to overcome this would be a backwards step rather than a move away from the keyword-esque language search engines are trying to move away from.
By using the contextual representations to understand word’s meaning in a given context intent detection of searchers is greatly improved.
Whilst there are currently limitations for BERT in long documents, passages seem an ideal place to start toward a new intent-detection led search. This is particularly so, when search engines begin to “Augment Knowledge” from queries and connections to knowledge bases and repositories outside of standard search, and there is much work in this space.
What does this mean for SEOs?
As you may recall, the Frederic Dubut of Bing video from early 2020 and remember that Bing have been using BERT since last April and also claim to be using something BERT like everywhere in their search engine systems. Whilst Bing may not have the same search market share as Google, they do have an impressive natural language understanding research team, well respected in their space.
Frederic said it was time for SEOs to focus on intent research practices, but I do not believe that meant we should not consider words, since after all, language is built on words. Even DeepCT does not claim to be able to understand intent without words. But Frederic was perhaps advising SEOs to move away from the keyword-esque type “x number of keyword mentions on a page” approaches and more toward aligning increasingly with truly understanding the intent behind information needs.
That said, structure and focus in content has ALWAYS mattered, and never more so than now when contextual clarity will be even more important in writing, plus subtopics throughout a long form document as a whole will be an important part of that, since passages will likely be these long documents chopped into parts.
Clear section headings and focus to meet an information need at each stage are undoubtedly always going to be useful, despite this not necessarily being an SEO ‘thing’. I’d certainly be revisiting those spurious blog posts with little topical centrality and improving them to add further value as a first point of advice.
Plus, the use of <section> in html5 is not there for no reason after all.
The Mozilla Foundation provides a great example of the use of this ‘standalone’ section markup and content combined.

Also, don’t just rely on rank trackers to understand intent. The SERPs and the types of sites ranking and the content within them are undoubtedly the best measure of what you should be talking about in your passages to meet informational needs. It’s not always what you expect.
These developments with BERT everywhere (and passages if BERT and DeepCT is used), reinforce that further.
As Google’s Prabhakar Raghavan said, “This is just the start.”
He is not wrong.
Whilst there are currently limitations for BERT in long documents, passages seem an ideal place to start toward a new ‘intent-detection’ led search. This is particularly so, when search engines begin to ‘Augment Knowledge’ from queries and connections to knowledge bases and repositories outside of standard search, and there is much work in this space ongoing currently.
But that is for another article.
References and sources
Beltagy, I., Peters, M.E. and Cohan, A., 2020. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
Bendersky, M. and Kurland, O., 2008, July. Re-ranking search results using document-passage graphs. In Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval (pp. 853-854).
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J., Mohiuddin, A., Kaiser, L. and Belanger, D., 2020. Rethinking Attention with Performers. arXiv preprint arXiv:2009.14794.
Clark, K., Luong, M.T., Le, Q.V. and Manning, C.D., 2020. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555.
Dai, Z. and Callan, J., 2019. An Evaluation of Weakly-Supervised DeepCT in the TREC 2019 Deep Learning Track. In TREC.
Dai, Z. and Callan, J., 2019, July. Deeper text understanding for IR with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 985-988).
Dai, Z. and Callan, J., 2019. Context-aware sentence/passage term importance estimation for first stage retrieval. arXiv preprint arXiv:1910.10687.
Dai, Z. and Callan, J., 2020, July. Context-Aware Term Weighting For First Stage Passage Retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 1533-1536).
Dai, Z. and Callan, J., 2020, April. Context-Aware Document Term Weighting for Ad-Hoc Search. In Proceedings of The Web Conference 2020 (pp. 1897-1907).
Devlin, J., Chang, M.W., Lee, K. and Toutanova, K., 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Evans, D.A., Claritech Corp, 1999. Information retrieval based on use of sub-documents. U.S. Patent 5,999,925.
Han, S., Wang, X., Bendersky, M. and Najork, M., 2020. Learning-to-Rank with BERT in TF-Ranking. arXiv preprint arXiv:2004.08476.
Joshi, M., Choi, E., Weld, D.S. and Zettlemoyer, L., 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551.
Karpukhin, V., Oğuz, B., Min, S., Wu, L., Edunov, S., Chen, D. and Yih, W.T., 2020. Dense Passage Retrieval for Open-Domain Question Answering. arXiv preprint arXiv:2004.04906.
Kitaev, N., Kaiser, Ł. and Levskaya, A., 2020. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451.
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K. and Toutanova, K., 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7, pp.453-466.
Lin, J., Nogueira, R. and Yates, A., 2020. Pretrained Transformers for Text Ranking: BERT and Beyond. arXiv preprint arXiv:2010.06467.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L. and Stoyanov, V., 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Nguyen, T., Rosenberg, M., Song, X., Gao, J., Tiwary, S., Majumder, R. and Deng, L., 2016. Ms marco: A human-generated machine reading comprehension dataset.
Nogueira, R. and Cho, K., 2019. Passage Re-ranking with BERT. arXiv preprint arXiv:1901.04085.
Nogueira, R., Yang, W., Cho, K. and Lin, J., 2019. Multi-stage document ranking with BERT. arXiv preprint arXiv:1910.14424.
Pasumarthi, R.K., Wang, X., Li, C., Bruch, S., Bendersky, M., Najork, M., Pfeifer, J., Golbandi, N., Anil, R. and Wolf, S., 2018. TF-Ranking: Scalable TensorFlow Library for Learning-to-Rank.(2018). arXiv. arXiv preprint arXiv:1812.00073.
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W. and Liu, P.J., 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
Search On with Google. 2020. Search On with Google 2020. [ONLINE] Available at: https://searchon.withgoogle.com/. [Accessed 25 October 2020].
Sekulić, I., Soleimani, A., Aliannejadi, M. and Crestani, F., 2020. Longformer for MS MARCO Document Re-ranking Task. arXiv preprint arXiv:2009.09392.
seroundtable.com. 2020. Google Says Being On The First Page Of Search Means You Are Doing Things Right. [ONLINE] Available at: https://www.seroundtable.com/google-first-page-doing-things-right-29431.html. [Accessed 25 October 2020].
Tie-Yan Liu et al. Learning to rank for information retrieval. Foundations and TrendsR in Information Retrieval, 3(3):225–331, 2009.
Wang, S., Zhou, L., Gan, Z., Chen, Y.C., Fang, Y., Sun, S., Cheng, Y. and Liu, J., 2020. Cluster-Former: Clustering-based Sparse Transformer for Long-Range Dependency Encoding. arXiv preprint arXiv:2009.06097.
Wang, X., Li, C., Golbandi, N., Bendersky, M. and Najork, M., 2018, October. The lambdaloss framework for ranking metric optimization. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (pp. 1313-1322).
Zaheer, M., Guruganesh, G., Dubey, A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L. and Ahmed, A., 2020. Big bird: Transformers for longer sequences. arXiv preprint arXiv:2007.14062.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author