The final recrawl analysis: A powerful and important last step after implementing large-scale SEO changes
You've crawled your client's site, identified the SEO issues and fixed those issues in staging. Great job! But columnist Glenn Gabe shares why recrawling the site is critical once your SEO changes have been pushed live.

When helping companies deal with performance drops from major algorithm updates, website redesigns, CMS migrations and other disturbances in the SEO force, I find myself crawling a lot of URLs. And that typically includes a number of crawls during a client engagement. For larger-scale sites, it’s not uncommon for me to surface many problems when analyzing crawl data, from technical SEO issues to content quality problems to user engagement barriers.
After surfacing those problems, it’s extremely important to form a remediation plan that tackles those issues, rectifies the problems and improves the quality of the website overall. If not, a site might not recover from an algorithm update hit, it could sit in the gray area of quality, technical problems could sit festering, and more.
As Google’s John Mueller has explained a number of times about recovering from quality updates, Google wants to see significant improvement in quality, and over the long term. So basically, fix all of your problems — and then you might see positive movement down the line.
Crawling: Enterprise versus surgical
When digging into a site, you typically want to get a feel for the site overall first, which would include an enterprise crawl (a larger crawl that covers enough of a site for you to gain a good amount of SEO intelligence). That does not mean crawling an entire site. For example, if a site has 1 million pages indexed, you might start with a crawl of 200-300K pages.
Here are several initial enterprise crawls I have performed, ranging from 250K to 440K URLs.

Based on the initial crawl, you might then launch several surgical crawls focused on specific areas of the site. For example, notice a lot of thin content in X section of a site? Then focus the next crawl just on that section. You might crawl 25-50K URLs or more in that area alone to get a better feel for what’s going on there.
When it’s all said and done, you might launch a number of surgical crawls during an engagement to focus your attention on problems in those specific areas. For example, here’s a smaller, surgical crawl of just 10K URLs (focused on a specific area of a website).
All of the crawls help you identify as many problems on the site as possible. Then it’s up to you and your client’s team (a combination of marketers, project managers, designers, and developers) to implement the changes that need to be completed.
Next up: Auditing staging — awesome, but not the last mile
When helping clients, I typically receive access to a staging environment so I can check changes before they hit the production site. That’s a great approach in order to nip problems in the bud. Unfortunately, there are times that changes which are incorrectly implemented could lead to more problems. For example, if a developer misunderstood a topic and implemented the wrong change, you could end up with more problems than when you started.
You absolutely want to make sure all changes being implemented are correct, or you could end up in worse shape than before the audit. One way to crawl staging when it’s not publicly available is to have VPN access. I covered that in a previous post about how to crawl a staging server before changes get pushed to production.
But here’s the rub. We’re now talking about the staging environment and not production. There are times changes get pushed to production from staging and something goes wrong. Maybe directives get botched, a code glitch breaks meta data, site design gets impacted which also impacts usability, mobile URLs are negatively impacted, and so on and so forth.
Therefore, you definitely want to check changes in staging, but you absolutely want to double check those changes once they go live in production. I can’t tell you how many times I’ve checked the production site after changes get pushed live and found problems. Sometimes they are small, but sometimes they aren’t so small. But if you catch them when they first roll out, you can nuke those problems before they can cause long-term damage.
The reason I bring all of this up is because it’s critically important to check changes all along the path to production, and then obviously once changes hit production. And that includes recrawling the site (or sections) where the changes have gone live. Let’s talk more about the recrawl.
The recrawl analysis and comparing changes
Now, you might be saying that Glenn is talking about a lot of work here… well, yes and no. Luckily, some of the top crawling tools enable you to compare crawls. And that can help you save a lot of time with the recrawl analysis.
I’ve mentioned two of my favorite crawling tools many times before, which are DeepCrawl and Screaming Frog. (Disclaimer: I’m on the customer advisory board for DeepCrawl and have been for a number of years.) Both are excellent crawling tools that provide a boatload of functionality and reporting. I often say that when using both DeepCrawl and Screaming Frog for auditing sites, 1+1=3. DeepCrawl is powerful for enterprise crawls, while Screaming Frog is outstanding for surgical crawls.

Credit: GIPHY
DeepCrawl and Screaming Frog are awesome, but there’s a new kid on the block, and his name is Sitebulb. I’ve just started using Sitebulb, and I’m digging it. I would definitely take a look at Sitebulb and give it a try. It’s just another tool that can complement DeepCrawl and Screaming Frog.
Comparing changes in each tool
When you recrawl a site via DeepCrawl, it automatically tracks changes between the last crawl and the current crawl (while providing trending across all crawls). That’s a big help for comparing problems that were surfaced in previous crawls. You’ll also see trending of each problem over time (if you perform more than just two crawls).
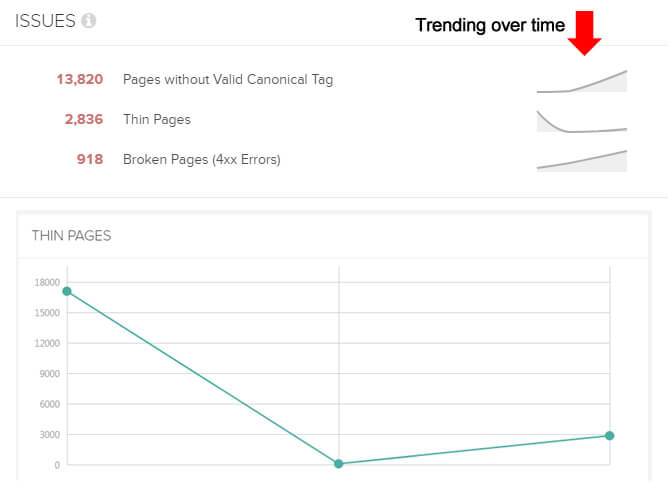
Screaming Frog doesn’t provide compare functionality natively, but you can export problems from the tool to Excel. Then you can compare reporting to check the changes. For example, did 404s drop from 15K to 3K? Did excessively long titles drop from 45K to 10K? Did pages noindexed accurately increase to 125K from 0? (And so on and so forth.) You can create your own charts in Excel pretty easily.
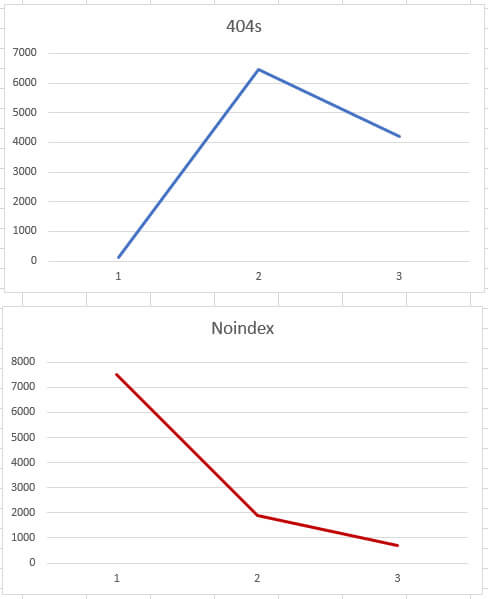
And now comes the young punk named Sitebulb. You’ll be happy to know that Sitebulb provides the ability to compare crawls natively. You can click any of the reports and check changes over time. Sitebulb keeps track of all crawls for your project and reports changes over time per category. Awesome.
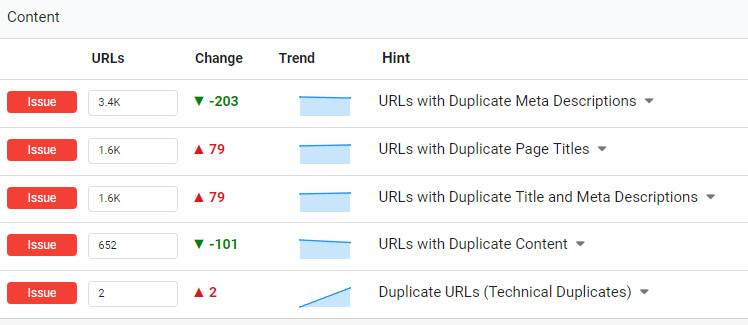
As you can see, the right tools can increase your efficiency while crawling and recrawling sites. After problems have been surfaced, a remediation plan created, changes implemented, changes checked in staging, and then the updates pushed to production, a final recrawl is critically important.
Having the ability to compare changes between crawls can help you identify any changes that aren’t completed correctly or that need more refinement. And for Screaming Frog, you can export to Excel and compare manually.
Now let’s talk about what you can find during a recrawl analysis.
Pulled from production: Real examples of what you can find during a recrawl analysis
After changes get pushed to production, you’re fully exposed SEO-wise. Googlebot will undoubtedly start crawling those changes soon (for better or for worse).
To quote Forrest Gump, “Life is like a box of chocolates, you never know what you’re gonna get.” Well, thorough crawls are the same way. There are many potential problems that can be injected into a site when changes go live (especially on complex, large-scale sites). You might be surprised what you find.

Below, I’ve listed real problems I’ve surfaced during various recrawls of production while helping clients over the years. These bullets are not fictional. They actually happened and were pushed to production by accident (the CMS caused problems, the dev team pushed something by accident, there was a code glitch and so on).
Murphy’s Law — the idea that anything that can go wrong will go wrong — is real in SEO, which is why it’s critically important to check all changes after they go live.
Remember, the goal was to fix problems, not add new ones. Luckily, I picked up the problems quickly, sent them to each dev team, and removed them from the equation.
- Canonicals were completely stripped from the site when the changes were pushed live (the site had 1.5M pages indexed).
- The meta robots tag using noindex was incorrectly published in multiple sections of the site by the CMS. And those additional sections drove a significant amount of organic search traffic.
- On the flip side, in an effort to improve the mobile URLs on the site, thousands of blank or nearly blank pages were published to the site (but only accessible by mobile devices). So, there was an injection of thin content, which was invisible to naked eye.
- The wrong robots.txt file was published and thousands of URLs that shouldn’t be crawled, were being crawled.
- Sitemaps were botched and were not updating correctly. And that included the Google News sitemap. And Google News drove a lot of traffic for the site.
- Hreflang tags were stripped out by accident. And there were 65K URLs containing hreflang tags targeting multiple countries per cluster.
- A code glitch pushed double the amount of ads above the fold. So where you had one annoying ad taking up a huge amount of space, the site now had two. Users had to scroll heavily to get to the main content (not good from an algorithmic standpoint, a usability standpoint, or from a Chrome actions standpoint).
- Links that have been nofollowed for years were suddenly followed again.
- Navigation changes were actually freezing menus on the site. Users couldn’t access any drop-down menu on the site until the problem was fixed.
- The code handling pagination broke and rel next/prev and rel canonical weren’t set up correctly anymore. And the site contains thousands of pages of pagination across many categories and subcategories.
- The AMP setup was broken, and each page with an AMP alternative didn’t contain the proper amphtml code. And rel canonical was removed from the AMP pages as part of the same bug.
- Title tags were improved in key areas, but html code was added by accident to a chunk of those titles. The html code began breaking the title tags, resulting in titles that were 800+ characters long.
- A code glitch added additional subdirectories to each link on a page, which all led to empty pages. And on those pages, more directories were added to each link in the navigation. This created the perfect storm of unlimited URLs being crawled with thin content (infinite spaces).
I think you get the picture. This is why checking staging alone is not good enough. You need to recrawl the production site as changes go live to ensure those changes are implemented correctly. Again, the problems listed above were surfaced and corrected quickly. But if the site wasn’t crawled again after the changes went live, then they could have caused big problems.
Overcoming Murphy’s Law for SEO
We don’t live in a perfect world. Nobody is trying sabotage the site when pushing changes live. It’s simply that working on large and complex sites leaves the door open to small bugs that can cause big problems. A recrawl of the changes you guided can nip those problems in the bud. And that can save the day SEO-wise.
For those of you already running a final recrawl analysis, that’s awesome. For those of you trusting that your recommended changes get pushed to production correctly, read the list of real problems I uncovered during a recrawl analysis again. Then make sure to include a recrawl analysis into your next project. That’s the “last mile.”
I’ve written about Murphy’s Law before. It’s real, and it’s scary as heck for SEOs. A recrawl can help keep Murphy at bay — and that’s always a good thing when Googlebot comes knocking.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author