Under The Hood: Google News & Ranking Stories
Forget PageRank, at least if you’re a news publisher looking to do well in Google News. Google’s news service doesn’t rely on the same algorithm used by “regular” Google, of which PageRank is a part of. Instead, Google News taps into its own unique ranking signals, which include user clicks, the estimated authority of a […]
Forget PageRank, at least if you’re a news publisher looking to do well in Google News. Google’s news service doesn’t rely on the same algorithm used by “regular” Google, of which PageRank is a part of. Instead, Google News taps into its own unique ranking signals, which include user clicks, the estimated authority of a publication in a particular topic, freshness, geography and more.
In this, the third part of a wide-ranging interview I held with Josh Cohen, business product manager of Google News, a look into how Google News ranks content. Also be sure to read the first two installments:
- Josh Cohen Of Google News On Paywalls, Partnerships & Working With Publishers
- Google’s News Experiments & The Quest To Solve The “Read State” Issue
You may also find this related overview article I’ve written of interest: How Search Engines, Aggregators & Blogs Use News Content.
How’s Google News Work?
One complaint put out by some news publishers, probably most dramatically by Italian papers that requested a government investigation in August, is that Google doesn’t provide enough transparency about how Google News works. Cohen disagrees, saying there’s plenty out there:
“We launched [Google News] blog and put a lot of information on it. It serves multiple audiences, but a lot if it is specifically geared toward publishers. One post was on the myths of Google News exposed.
Cohen adding that the “myths” post itself developed from common questions that Google answers through its Google News forum for publishers. Google also maintains a help area for publishers, too.
Still, compared to Google web search, ranking in Google News can seem a mystery. As I said to Cohen, if someone asks me why they don’t rank for a term in Google web search, I (or any knowledgeable SEO) can determine if there are some obvious content or link deficiencies, blocking problems or potentially a domain that hasn’t earned much authority yet within Google’s web search ranking system.
But why a story does or does not rank well in Google News, either in response to a keyword search or in browsable headlines? There seems little to diagnose or explain. Google News can feel like a black box.
Cohen responded with more specifics:
In a lot of discussions with publishers, we do talk about the ranking side, the clustering process and what we’re trying to do. There’s the story ranking, where we show the top stores of the day in a given category. What’s the aggregate editorial interest is in a given story? What does everyone have on their front page? That’s going to drive the results. What do editors collectively feel is the top story of the day?
Of Stories & Story Clusters
By “story” ranking, Cohen’s not talking about individual stories from publications and how they rank against each other for a particular search. Instead, what he means are “story clusters,” a group of individual articles that are all on a given angle to a particular news event.
For example, consider the story clusters I found yesterday evening, when I clicked into the Entertainment area of Google News:
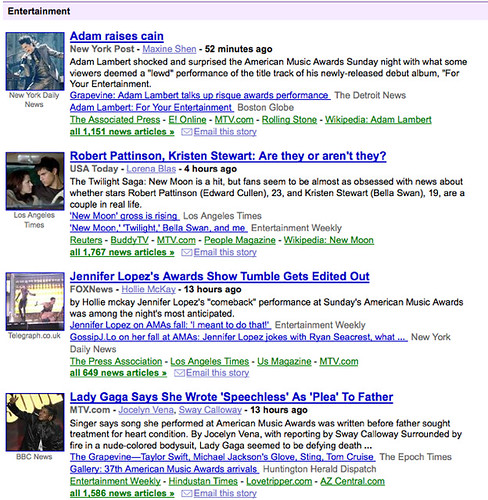
At the top, there’s a cluster of stories all about Adam Lambert and his performance at the recent American Music Awards. Skip down to the third cluster, and it’s related to the awards as well — but this time focusing on Jennifer Lopez and her footing malfunction. Just below that is the fourth cluster, about some of the actual awards that were given out.
The Google News algorithm decides how to form these types of clusters and which ones to list first. Beyond that, within each cluster are actual individual stories. For example, let’s zoom in on the Jennifer Lopez cluster:
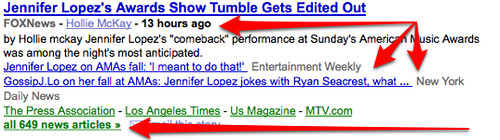
The first arrow highlights how the main story in this cluster comes from Fox News, followed by an Entertainment Weekly story, then one from the New York Daily news. Beyond that, there are 649 articles in total all deemed related to this story cluster — and clicking on the link the last arrow points at would list them for you.
The algorithm decides what appears where when you browse through Google News, and it also kicks in when you enter search terms. For example:
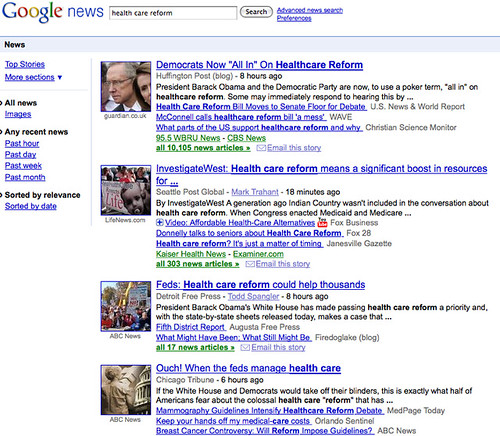
Those were results I got back in a search for “health care reform” on Google News. You can see various story clusters including current coverage on how it might help or hurt people.
In summary, Google News tries to determine important story clusters by looking at what individual stories are being featured across the board at various publications. When those publications begin to feature new stories, that in turn influences the creation of new story clusters that get prominent placement at Google News.
Ranking Factors: Freshness, Local Relevancy & Other Signals
So what causes an individual article to be the lead item in a particular story cluster? Various factors are involved, Cohen said:
The source ranking involves many things. Is there original content? The timeliness. Coverage of recent developments? The relevancy to the cluster at hand. In some cases, is there local relevancy? Is there content from a local source with local content?
For example, Cohen explained further, in the case of wildfires in Southern California, sources like the Los Angeles Times might be favored, as they’re local to that news. For stories happening elsewhere, other publications local to those stories might get a boost.
Cohen also explained more about the balance between ranking the latest content versus the originating content:
Say you publish something and then someone else sources you but adds no real new information. If they come after you, you don’t want to penalize the original source for being first.
Publication Reputation: Think NewsRank, Not PageRank
Cohen also said that how an individual article ranks within a story cluster is further influenced by the reputation that its publishing source carries within Google News:
There are source specific rankings, the equivalent of PageRank for a particular site. We look at different third party metrics. What’s the volume of publication of original content in a given category? If you look at Bloomberg and Reuters, they may have hundreds of original articles in business. That’s a pretty good indication of the quality of that source for that category. Compared to sports, there’s not that much original content [and so they might not have as much authority for when ranking sports stories].
Is there a name for this source value? Is there a NewsRank? No, Cohen said, but he stressed the value is completely different than PageRank (which itself is only one of many signals used by Google for ranking web search results):
We don’t have a name for this. But it’s not the same as PageRank. That isn’t a term that we use. Sources have their own rankings distinct from web search, especially because of the fleeting nature of a news article. There are a number of different signals we use to calculate source authority by edition and section.
To clarify that last sentence further, Google News has various “editions” for different countries, such as Google News UK versus Google News US. Each edition has its own particular blend of signals it uses to rank news content. That’s why the UK version of Google News will be different from the US version. Furthermore, each section within a Google News edition (such as Entertainment versus Sports) also uses its own unique blend of ranking signals.
Measuring Clicks
Yet another signal in the Google News ranking mix is what users are clicking on from the results they see. Said Cohen:
You understand who are trusted sources for users. If you go to a given cluster for Google News, you’d expect the first story to get more clicks than the second and so on. If you look at a user’s behavior that doesn’t do what you expect, that gives you a lot of information.
For example, Cohen explained, say both the Wall Street Journal and Search Engine Land have a story about Google’s earnings in the business section of Google News. The WSJ might draw more clicks as the more trusted or appealing source to business readers. But a story about some new Google product that both publications report on that shows in the Sci/Tech section? “I’m going to go to Search Engine Land,” Cohen said.
Isn’t monitoring clicks awfully prone to spam, where publications might just click themselves into top rankings?
“It’s not just click behavior,” Cohen stressed, about how stories are ranked. Clicks are just one of many signals. Still, he admits spam does happen, but not as much as you’d see with commercial web results:
You see more spam on the commercial side of things. Not that all news publishers that are above that. Spam is something we’re aware of, with the odd publication.
Subscription Content & Clicks
Clicks also have an impact on subscription-only content. People are less likely to select that material, when it’s flagged in Google News, which results in less visibility. As Cohen explained in an earlier part of my interview with him:
If you have subscription content, the user response to it will in effect tell the algorithm this isn’t not a relevant result, I’m not clicking on this. By making it free or by in essence saying it’s paid but Google treats it as free [because of First Click Free], there’s a significant advantage to them, because all their content is indexed, and I think at the end of the day probably helps the results. People are more likely to link to it and all the different ways it can be beneficial.
In other words, since Google News readers they largely bypass subscription-based content, less of this ultimate is shown in Google News, as the algorithm is trying to mirror what the users want.
Textual Content Counts, Tool
How about the actual stories, the written words within them. With all the talk of source authority and measuring clicks, does what’s on the page itself carry weight? Yes, Cohen said:
Your URL, title and body are three components you can look at. If you’re weak any one of those, it puts additional weight on other categories. But the more components you remove from the process, the more it makes any single one that much more important.
FYI, my Quick Tips For Newspapers & SEO post has some advice relating to this topic.
Algorithms Decide, Not Editors
Cohen also stressed that the system has no human editors ranking publications or stories. Instead, that’s left to the ranking algorithm, a system of automatically making story selections and ranking in response to keyword searches:
It’s not an editorial process. We don’t have anyone sitting down saying this is a good source and this is a bad source. There’s a number of different signals.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author