How we hijacked Google’s SEO guide search rankings
Contributor Dan Sharp shares an experiment in which his company was able to hijack rankings -- from Google itself. See what they learned in the process.
I wanted to share some notes on an experiment my agency performed recently, which resulted in Google believing our website was the canonical version of their own search engine optimization starter guide PDF — and ranking us in place of their own content for “search engine optimization” and thousands of other phrases.
We perform many tests internally, both for our SEO Spider software and as an agency for clients. This particular experiment was purely for fun to highlight the issue we discovered, without the intention of hurting anyone, or indeed for any profit. We have now ended the experiment and removed the content.
Background
We had previously been in touch with Google after noticing some strange behavior in the search engine results. While their SEO starter guide PDF was ranking for relevant terms like “SEO” and “google SEO guide,” something wasn’t quite right….
@JohnMu Hey John, the G SEO starter guide not ranking or indexed. Replaced by another site. This highlight issue with 302s? :-) pic.twitter.com/I5M4VLFe9D
— Dan Sharp (@screamingfrog) November 7, 2016
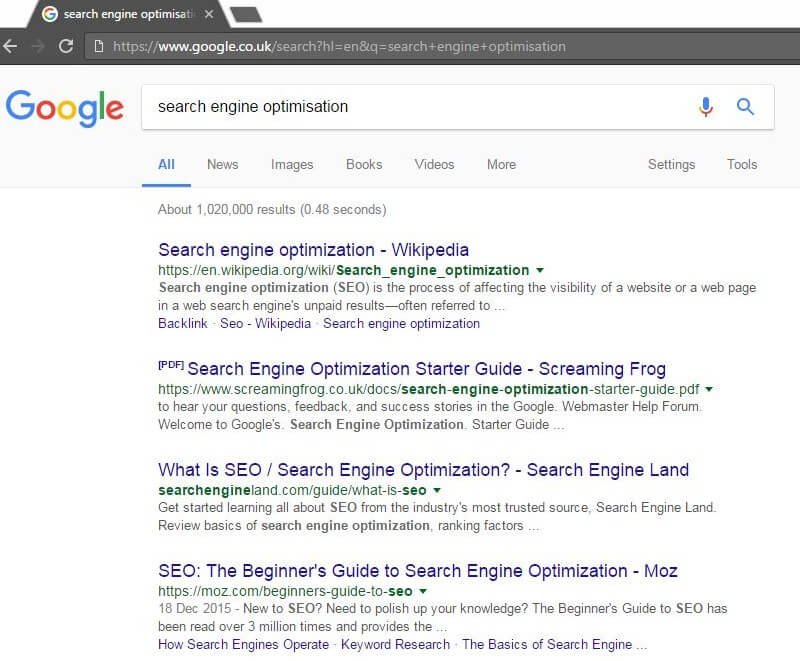
For the searches we performed, the listing for the starter guide PDF would appear, but it would link to various other websites that had uploaded it rather than to Google’s own website. So Google wasn’t ranking its own page for some reason; other websites appeared instead, using Google’s content.
Here’s a view of some of the sites ranking for it in the UK. Each site appeared to knock the other out of the search results as Google changed which one it believed was the canonical version.
We decided to look into why Google’s page wasn’t being indexed and other pages were seemingly showing in its place. We noticed Google appeared to be using a 302 temporary redirect on their search engine optimization starter guide, which is hosted on a separate domain.
The 302 redirect should mean the original URL on google.com was indexed, rather than the target URL hosted on static.googleusercontent.com.
However, neither URL was indexed, and they appeared to be struggling to understand the canonical and index their original content and URL. Google was not using “noindex,” nothing was blocked via robots.txt, other content was indexed on the subdomain, and they didn’t appear to have any conflicting directives with canonicals or anything else on the page, or within the HTTP header.
Google has said that PageRank flows the same regardless of whether it’s a 302 temporary redirect or 301 permanent redirect — it’s really a matter of which URL they index and show in the search results. So in theory, the original URL should have been indexed and ranking, but this wasn’t the case.
While each type of redirect should pass PageRank in a similar way, Gary Illyes has said that 301s help with canonicalization.
@AndyNRodgers redirects pass same, but 301 helps with canonicalization @JohnMu
— Gary Illyes ᕕ( ᐛ )ᕗ (@methode) August 5, 2016
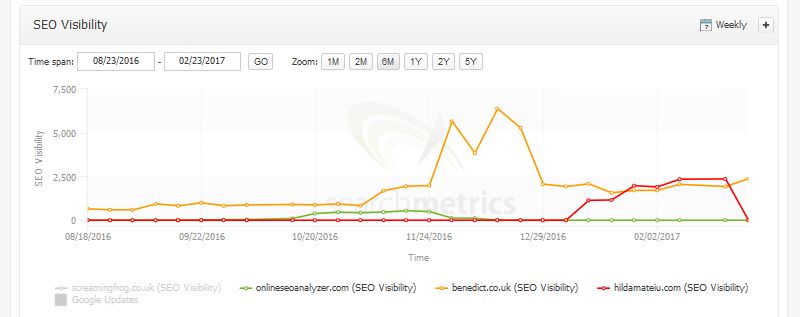
We knew from previous experiments that identical content can be hijacked, but generally by more authoritative websites. Google’s SEO starter guide has about 2,100 linking root domains to the original URL and another 485 to the redirect target (HTTP/HTTPS protocols combined), so it’s a very powerful page with lots of visibility.
The starter guide is also on Google.com, which has a huge amount of reputation. The final target was on a separate domain, though.
Obviously, the Screaming Frog website is not as authoritative as Google, but far less authoritative websites had already replaced them previously, due to the issues described above.
The experiment
We decided to run a short-term experiment and simply upload Google’s SEO starter guide to our domain. We then got it indexed via Google Search Console and forgot about it.
A week later, we noticed we had hijacked Google’s own rankings (and any previous hijackers, due to our higher “authority”), as their algorithm seemingly believed we were now the canonical source of their own content. Our URL would return under a info: and cache: query for either of Google’s URLs.
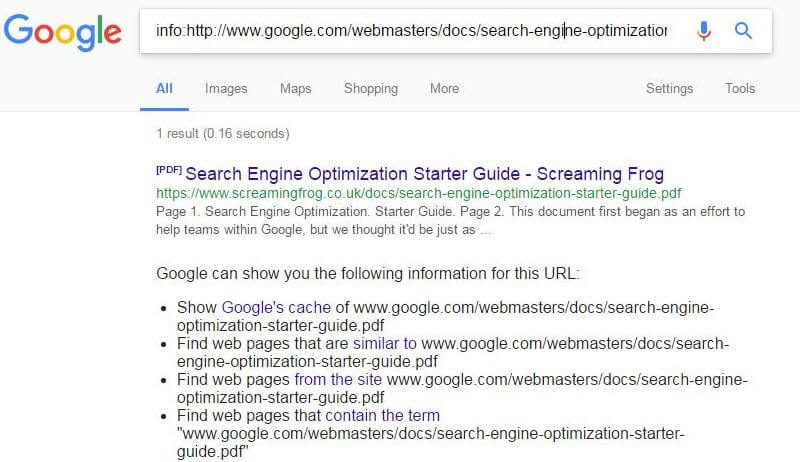
We had hijacked the hijackers — and Google.
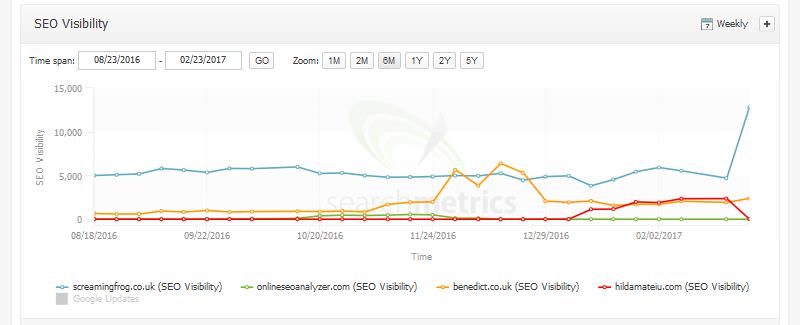
Even though we are a UK site, we jumped into 4th position for “search engine optimization” and the top 10 for “SEO” in the USA — from outside the top 50.
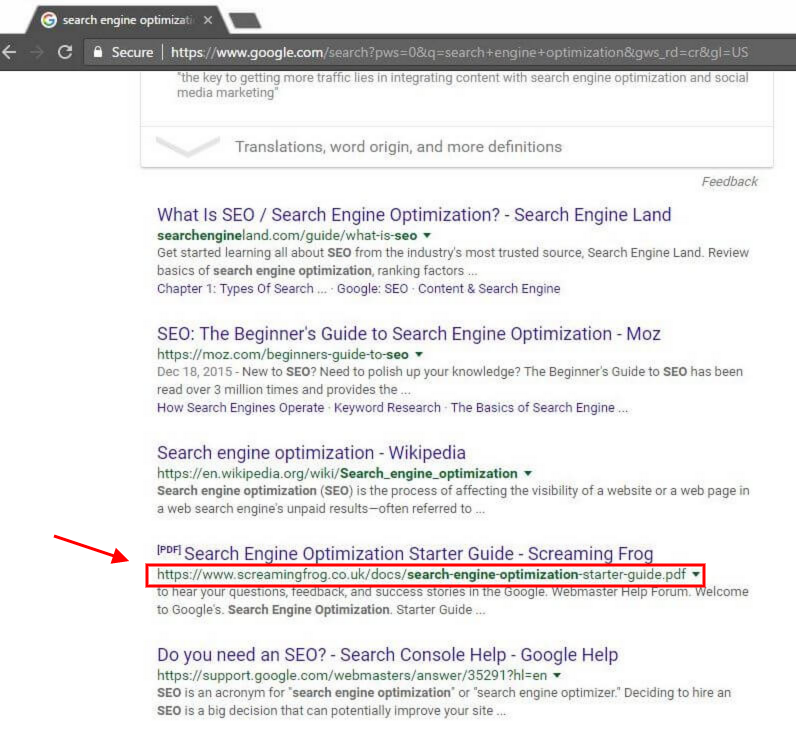
The PDF ranked for “Google SEO,” “Google SEO guide,” “www google com” and every other phrase that Google’s content should be visible for.
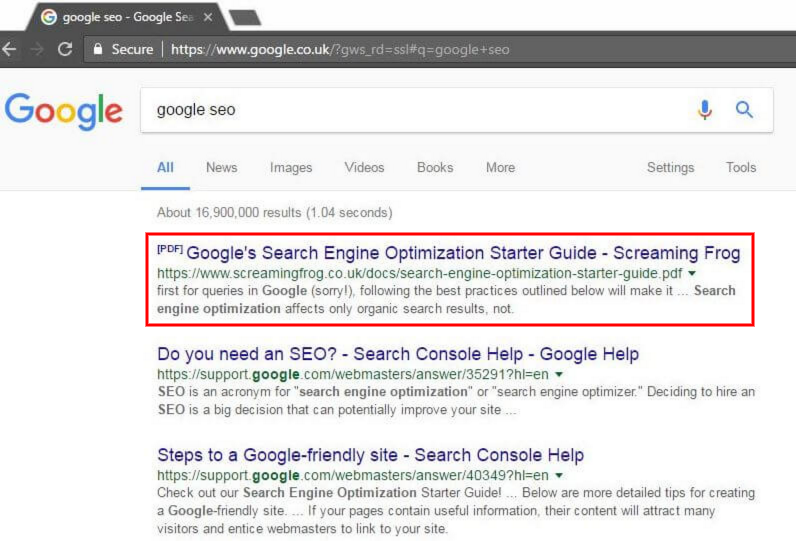
The PDF ranked for loads of other brand type queries in the UK and the US, which we can see courtesy of SEMrush (US specifically in the screen shot).
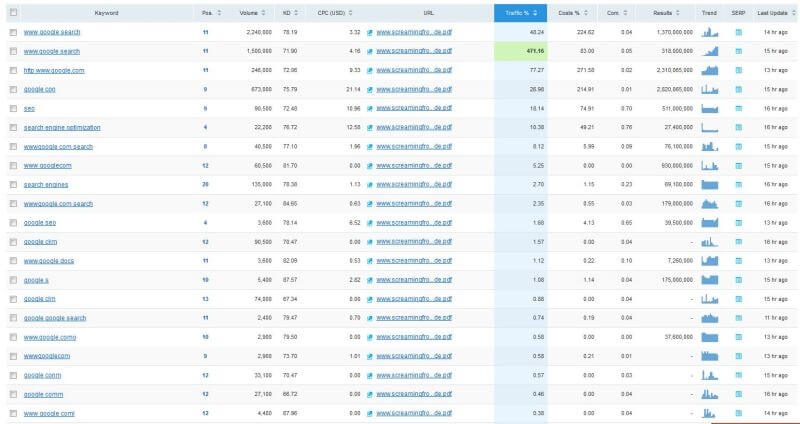
And Sistrix highlighted the sudden “new” keywords we were now appearing for organically:

Google Search Console recorded nearly 800K impressions for the PDF specifically for a period of four days.
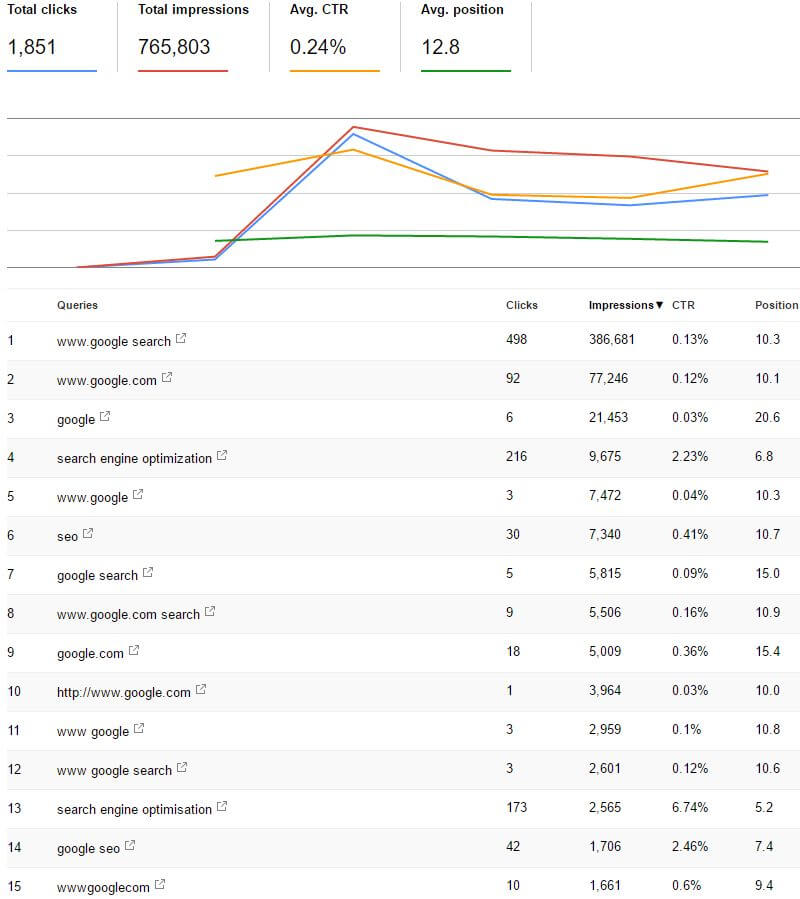
This experiment received a lot of attention when we tweeted it.
So, we kept an eye on it over the following days to see if Google made any changes to correct indexing, canonicalization and ranking. Around 48 hours later, we noticed that Google’s guide started ranking and was clearly now indexed (and would appear under a site: query), when previously it wouldn’t have returned a result.
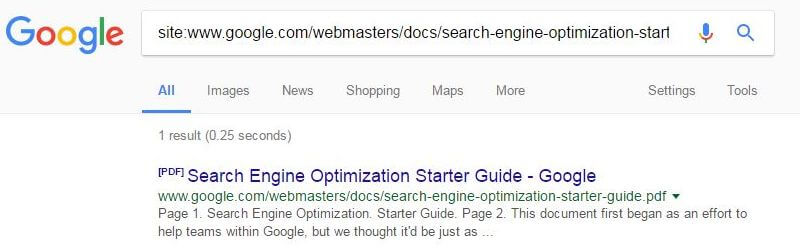
We then noticed Google had added an HTTP canonical to their PDF to the original URL, which helped get it indexed.

However, we were still appearing as the canonical under an info: query and ranking for their queries. This meant both guides were now ranking in the search results, often with our site above Google’s own.

We were expecting this to change — for Google to become the canonical again and our page to drop out of the rankings. Up to five days later, we were still there, alongside Google in the search results for thousands of search queries. Then, our PDF disappeared from the search results, and we ended the experiment fairly swiftly.
Closing thoughts
First of all, we don’t recommend messing with other people’s content. This is not a viable strategy or tactic for gaining higher rankings, merely an unusual and interesting case study. It can be very difficult to draw conclusions, as we can’t always be sure what other factors or unknowns might be in play.
While we have plenty of theories and thoughts internally, we’ll end on three closing points.
1. 302 redirect not (fully) to blame
While we initially believed the 302 redirect might be the root cause, I know Google is adamant that there are no issues using 302 redirects. We believe there are some contributory reasons around how the files are hosted.
We found a few other quirks around URLs changing over time (based upon values supplied in the Accept-Language header) and canonicalization on HTTPS incorrectly just for good measure.
2. Use canonicals
It’s very wise to use canonicals to help with indexation. As soon as Google updated the PDF’s HTTP canonicals to a single URL, it was immediately indexed.
Using a crawler, you can scan your site for missing canonical link elements or canonical links in your HTTP header.
For PDFs and docs, you can easily set an HTTP canonical using .htaccess, for example.
3. Although rare, hijacking can occur
A page’s rankings can be hijacked by another domain that uses identical content under specific circumstances, such as problems with indexation or being a more authoritative source. This is generally unlikely, but perhaps there are some things that Google can still improve in ranking the original source.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author