Identifying In-Site Duplicate Content Using Chained Search Operators
Whether you are taking over a new multinational account as an agency, or maintaining your company’s global Web presence as an in-house SEO, being able to quickly identify internal duplicate content is a vital skill. Duplicate content is a big problem for SEO for a number of reasons. If you’ve been following this multinational series, […]
Whether you are taking over a new multinational account as an agency, or maintaining your company’s global Web presence as an in-house SEO, being able to quickly identify internal duplicate content is a vital skill.
Duplicate content is a big problem for SEO for a number of reasons. If you’ve been following this multinational series, you’ll know that some of the biggest gains to be had in SEO today come from fine tuning your SERP sales message to make the landing page you target to a search term convert at a much higher rate than average.
If you are unable to ensure that your landing page is the only page optimised for that term, then you lose that strategic ability.
In short: regardless of the SEO benefit to be had by eliminating duplicate content, the impact of losing the ability to control which page turns up for which search term is a greater concern.
Automated Translation & Duplication
This is a common outcome, especially when looking at multinational websites where the translation in some countries is direct from another language, often as the result of an automated translation.
Matt Cutts has gone on record to state that such translation would be considered duplicate, and so many webmasters are getting into difficulties despite trying to do the whitehat thing and generate relevant content for the country.
Auditing For Duplicate Content With Google
Of course, Google gives you some idea of what other content it considers duplicate via its Webmaster Tools, with The HTML suggestion report highlighting areas of duplication in title tags and meta descriptions.
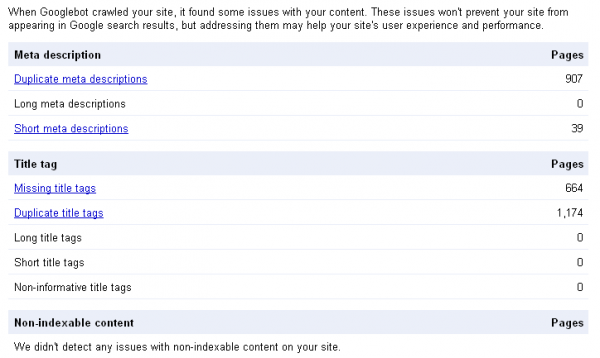
But this is really only useful as a refining tool and won’t indicate when, for example, your e-commerce system generates new pages for every available colour for every item of clothing you sell; if the colour is included in the title and meta description (generating 10 pages for domain authority to be spread across – therefore struggling – to compete for a competitive product when one single page would perform significantly better).
Similarly, it won’t tell you if your site used frames to host the bulk of page content, excluded from spider access via the robots.txt while the frameset pages are correctly tagged for SEO.
And so on. But most importantly, it won’t help you dig into a site to identify ‘crawler traps’ created by inadvertently creating navigation loops the generate near infinite permutations of URLs to be indexed, causing search engines to simply abandon crawling at a certain point – as defined by its perceived authority of your domain.
That means that if your site is considered low authority, or if you are hosting a large number of pages on a medium authority site, then page parsimony is critical to get the best possible performance out of your landing pages.
So what’s the best way to quickly narrow down duplicate content issues you may have?
Simple: unleash the power of chained Google site:, inurl: and intitle: operators.
If you haven’t read about search operators, this is a good place to start, but there are a few that aren’t listed in there which we can look at in more depth in a future article. For now, lets see how we hunt down duplication.
Finding Site Architecture Duplication
Lets take a look at Hilton Hotels’ global site architecture as an example audit.
First up, run a quick site: command, setting results to 100 so you can easily browse through the results: https://www.google.com/search?num=100&q=site%3Ahilton.com.
Running that search today, I get 388,000 results. 
If I click through to the last paginated page Google offers me, we can also see that after 848 results, Google has truncated the results suggesting that the rest are ‘very similar’ to the listings it has already displayed; i.e. the site contains massive amounts of duplicate content.

If I were to click on the link above, then Google would append &filter=0 to my search URL.
Those reading who’ve been around search for a long time will recognise that as the old ‘Supplemental listing’ parameter discussed by Matt Cutts and largely ignored for the last few years since the tag highlighting supplemental results was dropped.
We won’t go into supplementals further in this article, but it’s important to note the supplemental index was created to handle the mass duplication frequently encountered by Google in attempting to index the whole Internet.
The important attribute of supplemental listings to be aware of is that it can’t outrank any other page in the main index returning for a competitive search query.
So, hilton.com seems to have a pretty severe problem. Can we work out what’s happening, just by querying Google?
Well, to a large extent, yes. We can.
Just quickly browsing down the first page of results, I can see frequent repetition of Hilton Doubletree Results as non-www hilton.com results. So, for example, the following are both identical:
- https://hilton.com/en/dt/promotions/dt_greenhotels/index.jhtml
- https://doubletree.hilton.com/en/dt/promotions/dt_greenhotels/index.jhtml
Also, there’s a heck of a lot of jsessionid parameters, and sure enough we can chain our search operators to get an idea of the full extent of that issue:

Ouch! By chaining the operators, we in fact get a larger number of indexed pages that Google would originally admit: 587,000.
For hilton.com, we can start to identify other duplication issues by making excluding the jsessionid issue from our site operator search simply by appending a minus sign ‘-‘ to our search chain.
Using this filtering technique, we can carry on using search operators to find that:
- There’s massive duplication from the secure site (https) being indexed while selecting hotel availability dates:
- Their special offers are indexed and are poorly differentiated:
And so on… leaving us with a search chain filtering out those issue so we can keep combing the results for more problems.
There’s no silver bullet solution, although canonical tags would go a long way to solving some of the more severe issues. But a concerted effort to solve these duplicate content issues with a well documented business case for the various change requests required would return huge improvements in Hilton Group’s Web presence and deliver immediate, significant bottom line impact.
Using Google’s view of your domain to identify issues with your domains and take back control of your landing pages to better convert your search engine traffic to sale is a solid approach, in any language.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
About the author