Robots.txt Study Shows Webmasters Favor Google; BotSeer Robots.txt Search Engine Released
The Pennsylvania State University conducted a study that showed webmasters favored Google over other search engines in terms of allowing access to their web sites. An associated BotSeer search engine that allows searching across a collection of robots.txt files was also released. The study looked at which robots or crawlers were listed in a web […]
The Pennsylvania State University conducted a study that showed webmasters favored Google over other search engines in terms of allowing access to their web sites. An associated BotSeer search engine that allows searching across a collection of robots.txt files was also released.
The study looked at which robots or crawlers were listed in a web site’s robots.txt file, and Google was listed more often than any other search engine. The paper is named Determining Bias to Search Engines from Robots.txt (PDF) (it may be slow, so here is a local copy) and showed some interesting details.
The most commonly used user agent is the “universal robot,” where 93.8 percent of sites with robots.txt files have a rule allowing any crawler to access the site. 72.4 percent of the robots.txt files mentioned specific robots by name.
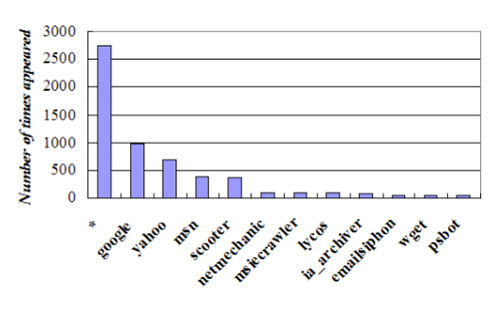
The chart below shows that Google’s robot, GoogleBot, is named more often than any other search engine:
The chart below compares search engine market share to robot bias:
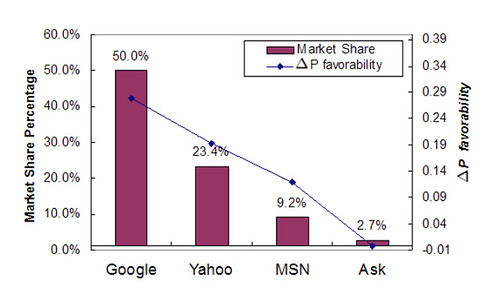
The study also collects historical data on the increased usage of the robots.txt file by webmasters. It is definitely worth downloading and reading.
One more note: I mentioned this morning a quote from Eytan of Live Search:
One thing that we noticed for example while mining our logs is that there are still a fair number of sites that specifically only allow Googlebot and do not allow MSNBot.
This study confirms Eytan’s statement.
Postscript From Danny: I skimmed the report and hope to look more later. However, saying Google is most favored by seeing if Googlebot is named with allow statements isn’t conclusive. For example, Googlebot might include things like the Google AdSense crawler — and allowing that while banning other spiders still might be banning Google itself. That said, I have no doubt site owners think more about Google than other search engines when crafting their files.
Related stories
About the author