Making Sense Of Google’s New Dynamic URL Recommendations
Google’s recent blog post recommending that webmasters avoid rewriting dynamic URLs caused a minor furor in the search marketing industry. Reactions ranged from nervous fears that sites with rewritten URLs should suddenly reverse out their extensive work, all the way to amazement and even anger that Google should recommend a halt to something that many […]
Google’s recent blog post recommending that webmasters avoid rewriting dynamic URLs caused a minor furor in the search marketing industry. Reactions ranged from nervous fears that sites with rewritten URLs should suddenly reverse out their extensive work, all the way to amazement and even anger that Google should recommend a halt to something that many consider a best practice.
As the president of a company which provides URL rewriting as one of a suite of natural search optimizations we do for many dynamic sites (via our GravityStream solution), I believe I have a unique perspective on the issue and can both clarify what I think the Googlers may have been intending to convey and also provide some alternative suggestions around the matter.
In retrospect, Google’s blog post on dynamic versus static URLs really isn’t all that revolutionary, and wasn’t intended to be all that controversial.
There’s been some degree of fear, uncertainty, doubt, and misinformation about URL rewriting. Many have learned search optimization tactics in relatively recent timeframe, primarily through reading a hodgepodge of webpages written at various times in the past by various people with varying degrees of expertise. When search engines were in their early days, they were almost uniformly unable/unwilling to spider dynamic URLs, so the presence of query strings and stop characters used to be a very big deal. Tactics such as employing “Mod Rewrite” scripting to automatically transform dynamic URLs to appear as static were developed to address these issues.
But during the battles over “who’s indexed the most pages”, the search engines reduced the rules on what types of URLs they would index, widening out to index many querystringed/dynamic URLs, and introducing new problems in terms of managing duplicates (duplication is caused when a site delivers up essentially the same content via a number of URLs which may differ only on relatively minor parameters). Individuals who don’t understand the evolution of search engine capabilities may not have the context necessary to really understand what aspects of URL formation are important.
In this blog post, Google apparently sought to reduce the misinformation around what’s needed in URLs, and also they wished to just make things easier for webmasters by letting people know that they can handle dynamic URLs a whole lot better than was done in the past. Google’s Head of their Webspam team, Matt Cutts, interpreted it this way in the post in Sphinn comments:
“…in my opinion what this post says is ‘We do a solid job on sites with dynamic parameters, and lots of people make mistakes when they try to rewrite their urls to look static, so you might want to try the dynamic parameter route because that can work quite well.’ In essence, it’s Google saying ‘We’ll come to webmasters and the natural way to write dynamic parameters rather than asking you to rewrite everything as static if you don’t want to.’ So we’re trying to come closer to webmasters, not wanting webmasters to necessarily move toward us. If you already have a site and it’s doing well the way that it currently is–great. In that case, you probably don’t need to change anything. But if you’re starting a new site, it’s worth considering staying with dynamic parameters instead of doing large amounts of rewrites (which some webmasters do in unusual ways that don’t always work well in search engines). That’s my take, at least. It’s not like either choice would get you penalized in Google; all of this is just advice to give more information to webmasters when they’re making their choice of site architecture.”
Our company agrees that it’s easy to do URL management wrong — it’s very easy to deploy it with little handling of factors which exacerbate duplication, making it harder for Google and the search engines to automatically decipher unnecessary parameters — and people doing it may overstuff the URLs with keywords or employ irrelevant keywords. URL rewriting done in an amateurish, unsophisticated manner can introduce a lot more problems than it solves.
Quite simply, URL rewriting shouldn’t be undertaken unless one has the necessary expertise and professional grade rewrite technology.
However, I don’t agree that all webmasters should necessarily leave URLs up to Google’s algorithms to manage. Google has recently asked for webmasters to help with the issues caused by infinite links and the “guided navigation” or search filtering links which create numerous URL pathways to the same content, and Googlebot isn’t very good at detecting this and compensating for the duplication and PageRank dilution effects. What it all boils down to is this: what’s confusing for Googlebot ultimately becomes confusing for searchers, thus leading to a lose-lose-lose — for Google, for its users, and for site owners.
Let’s have a look at a concrete example to prove my point. Not all that long ago, Googlebot got caught up in an unintentional spider trap in their own Google Store site, indexing many duplicate URLs caused by session IDs and alternate URLs caused by site architecture:

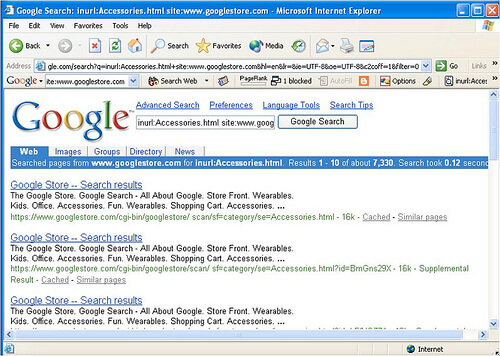
The fact is, URLs with session IDs or user IDs don’t always get properly identified by Google, resulting in duplicate content and PageRank dilution. When this happens, the potential PageRank of a site can get spread very thinly across a great many pages, reducing their ability to rank in the search results.
Also, URLs with keywords in them perform better in the SERPs (both ranking-wise and clickthrough-wise) than those with product IDs. So a rewritten URL like www.domain.com/blue-widgets will outperform www.domain.com/product.asp?productID=123 for a search on “blue widgets” — all else being equal. This is true not just in Google, but in other engines as well.
We’ve conducted numerous experiments for clients to prove the rankings benefit to ourselves, but we can’t publish these tests unfortunately (we are restricted due to client confidentiality). I encourage you to conduct your own tests. Recently, at Web 2.0 Expo in NY, Nathan Buggia of Microsoft Live Search described how descriptive URLs can provide better results in both search traffic and organic traffic. (When contacted later for this story, Buggia clarified that “you’re not trying to stuff as many keywords in there as possible; you’re trying to make the URL more descriptive and relevant to the page content so both users and search engines can better understand what they can expect from clicking a link to the page.”
Shorter URLs also have a better clickthrough rate in Google SERPs than long URLs. This effect was found through user testing that was commissioned by MarketingSherpa. MarketingSherpa found that short URLs get clicked on twice as often as long URLs (given that the position rank is equal).
The value proposition is clear: if you effectively transform your URLs to be shorter, to have good/relevant keywords, and to reduce possible duplication — you may have better clickthrough rates and better rankings in search engines.
What were Googlers’ Juliane Stiller and Kaspar Szymanski trying to accomplish with the aforementioned blog post? My hunch is that Google is finding an alarmingly large number of improperly implemented URL rewrites that are confusing Googlebot even more and exacerbating the duplicate content situation.
If superfluous parameters — e.g. session IDs, user IDs, flags that don’t substantially affect the content displayed, tracking parameters — get mistakenly embedded into the filename/filepath, then Googlebot will have an even harder time identifying those superfluous parameters and aggregating the duplicates. And what if parameters are embedded in the filepath in inconsistent order (e.g. www. example.com/c-clothing/shirts-mens/ and www.example.com/shirts-mens/c-clothing/). Plus, when Googlebot still finds links to the old (non-rewritten) URLs, your well-intentioned URL rewriting actually presents Google with yet another duplicate to deal with. It can be a real mess.
Google may now handle dynamic URLs better than in times previous, but if you know what you’re doing you’ll gain advantage by transforming your URLs effectively.
The lesson here is to hire a professional when embarking on a URL rewriting project, NOT to leave your URLs dynamic and your website in the hands of fate.
Stephan Spencer is founder and president of Netconcepts, a 12-year-old web agency specializing in search engine optimized ecommerce. He writes for several publications and blogs at the Natural Search Blog. The 100% Organic column appears Thursdays at Search Engine Land.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Related stories
New on Search Engine Land
About the author