Hold Your Horses: The Knowledge Vault Is Just A Research Project For Now
You may have heard buzz about Google's "Knowledge Vault." Contributor Eric Enge explains what it is and the real-world implications you should be considering.

You may have heard a lot about Google’s Knowledge Vault lately. It has been promoted by the trade press as the next generation of the Knowledge Graph, but hold your horses!
At this time, the Knowledge Vault is just a research project at the company. In this post, I will relay what we know so far, what the implications are for you, and why you should still care.
Recounting The History
We were first introduced to the idea of the Knowledge Vault during a presentation by Google’s Kevin Murphy at the CIKM conference on October 31, 2013. This talk was called From Big Data to Big Knowledge.
In this presentation, Murphy spoke about the limitations of the Knowledge Graph, and also about algorithms that could help get around some of those limitations (more on this below).
This talk did not get much attention from the digital marketing industry trade press, but that changed in August of this year. Since then, there has been a lot more buzz about it, including these three articles:
- Google’s fact-checking bots build vast knowledge bank – New Scientist, August 20, 2014
- Google “Knowledge Vault” To Power Future Of Search – Search Engine Land, August 25, 2014
- Good Bye Knowledge Graph, Hello Google Knowledge Vault? – Go Fish Digital, August 25, 2014
Greg Sterling added a postscript to the Search Engine Land article after being contacted by Google, as follows:
Postscript: Google yesterday indicated that the “Knowledge Vault” was misrepresented or misinterpreted in the New Scientist article above. Apparently this was a research paper (May 2014) and is not an active Google product in development. Google also indicated that there are numerous models at the company and elsewhere about building a knowledge base with machines or extracting meaning from text.
The New Scientist article had evidently picked up that a new presentation was planned by Kevin Murphy at the conference on Knowledge Discovery and Data Mining in New York on August 25, 2014 in New York. However, this was a presentation of a research paper.
Why The Concepts Are Still Of Critical Interest
There are two major takeaways from this:
1. The Scope Of The Knowledge Graph Is Quite Limited: According to the Kevin Murphy presentation, the Knowledge Graph provides Google with access to information on 500 million entities (people, places, etc.) and a total of 3.5 billion facts. While those seem like large numbers, their total scope is tiny when compared to “all knowledge.”

2. Take Note Of This Part Of What Google Told Greg Sterling: “There are numerous models at the company and elsewhere about building a knowledge base with machines or extracting meaning from text.”
Basically, the Knowledge Vault project is one initiative that Google is pursuing to expand upon the Knowledge Graph, but there are others in play, as well.
In summary, there is a lot of work going on to improve what knowledge Google can capture. This work will likely go in many different directions, including efforts to build a quantum computer.
Many have positioned the Knowledge Graph as being solely based on manually curated databases of information, and even the Kevin Murphy presentation at CIKM last year only mentions Freebase as a source (though he did not suggest this was the only source).
However, this is what Google’s Amit Singhal said about this back in May of 2012 in his post, Introducing the Knowledge Graph: things, not strings:
[blockquote cite=”Amit Singhal”]Google’s Knowledge Graph isn’t just rooted in public sources such as Freebase, Wikipedia and the CIA World Factbook. It’s also augmented at a much larger scale because we’re focused on comprehensive breadth and depth. It currently contains more than 500 million objects, as well as more than 3.5 billion facts about and relationships between these different objects. And it’s tuned based on what people search for, and what we find out on the web.[/blockquote]
In addition, Google already has launched features that do more than pull data from these types of sources. These include Step by Step Instructions and some structured snippets, as well.
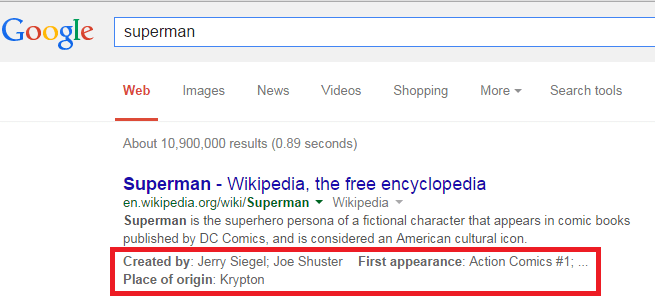
These initiatives show that Google is already trying some ways to extract knowledge from the web.
Impact On Your Digital Strategy
Regardless of timing, and regardless of whether or not Knowledge Vault concepts are a driver of where this all goes, increased machine intelligence is going to transform the way search works and what it displays.
You will see lots of debate on the morality, or legality, of Google presenting more direct answers in the search results, particularly when it is extracted from the websites of others.
My advice: Tune that whole discussion out, and set up your business to prosper from Google’s direction. Here are some key tips to consider:
- Don’t Rely On Public Domain Facts As A Traffic Driver. If this is a key part of your business, start changing that as quickly as possible.
- Start Thinking Of Ways That Extraction Of Key Facts From Your Website Can Enhance Your Brand. That’s right, embrace it — and put it to work for you. If Google starts taking information on your site and showing it in the search engine results pages, it makes you look like an authority for the topic. Find ways to take advantage of that.
- Start Viewing Your Website In Terms Of User Experiences. Part of your job with your website is to make Google’s product better. Think about it like any other editorially given link on the web. If Google sends a user to a page on your site, will it reflect well on Google? Will that user be satisfied with the search result? If you can make that answer “yes” more often than other competing pages, you will win in search in the long term.
- Don’t Be Overly Dependent On Google As A Source Of Search Traffic. You may have seen tons of press lately telling you that your visibility on social media platforms is on rented real estate. So is your visibility in Google. Time to treat it as such.
I know, some of you are going to want to fight this. However, my bet is that Google has already gotten far more legal advice on this matter than any of us. When I build my sandcastle in the wet sand at the beach, I can be very confident that it will get washed away. We’ve been playing in the wet sand for a long time now.
I believe that the main pressure on Google is a competitive one. If it veers too far into becoming highly commercial, and not being a source of traffic for other websites, another product that is much more open can gain real traction. In addition, the technology involved in the entire “Knowledge” discussion is massive, and will come slowly — probably over a decade or more.
So, we have more time to play just yet, but the more (and sooner) you start preparing for the future, the better.
Postscript: More Papers by Kevin Murphy
For those of you who want the master’s course on where the concept of the Knowledge Vault is going, here is some more reading material for you!
Canonicalizing Open Knowledge Bases
Luis Galarraga, Geremy Heitz, Kevin Murphy, Fabian Suchanek
CIKM 2014
Large-Scale Object Classification Using Label Relation Graphs
Jia Deng, Nan Ding, Yangqing Jia, Andrea Frome, Kevin Murphy, Samy Bengio, Yuan Li, Hartmut Neven, Hartwig Adam
ECCV 2014 (Best Paper Award)
Cooking with Semantics
Jon Malmaud, Earl Wagner, Nancy Chang, Kevin Murphy
ACL’14 Semantic Parsing Workshop
Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion
Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, Wei Zhang
KDD ’14
From Data Fusion to Knowledge Fusion
Xin Luna Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Kevin Murphy, Shaohua Sun, Wei Zhang
VLDB ’14
Knowledge Base Completion via Search-Based Question Answering
Robert West, Evgeniy Gabrilovich, Kevin Murphy, Shaohua Sun, Rahul Gupta, Dekang Lin
WWW ’14
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author