Some Of The Weird Issues When Google’s Quick Answers Come From Random Sources
As Google’s Hummingbird algorithm continues to shape the answers within Google’s search results, webmasters, SEOs and searchers ask themselves, why is Google showing this knowledge graph or that quick answer. Often webmasters find themselves at a loss because Google takes their content and puts it at the top of the search results. While searchers ask, […]

As Google’s Hummingbird algorithm continues to shape the answers within Google’s search results, webmasters, SEOs and searchers ask themselves, why is Google showing this knowledge graph or that quick answer. Often webmasters find themselves at a loss because Google takes their content and puts it at the top of the search results. While searchers ask, why is this the proper source for the answer – why not license content versus scrape content from webmasters?
I participated in a Google+ Hangout with Google’s John Mueller, who was presented some interesting cases of “branded” quick answers in the Google search results. John said that Google should avoid showing any branded details in the quick answers, Google says quick answers are technically not part of the knowledge graph. John said:
But I think, branded answers like that, probably not what we are trying to do here. I can definitely talk with the team here that works on that and see if we can improve that a little bit.
The two specific examples presented to John were these:
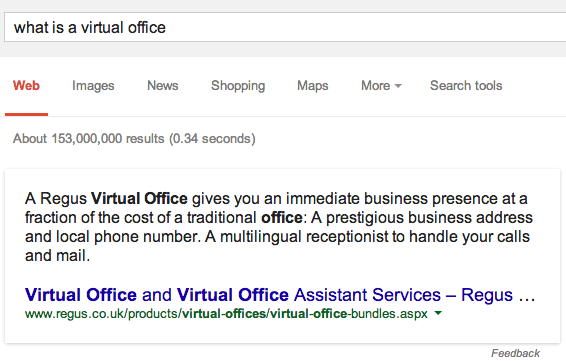
You can see here that Regus, a company that sells virtual office spaces, is being pulled for the quick answer in Google UK. But if you try the US search results, you get a definition:

The definition is being pulled from Oxford Dictionary but not citing it. Besides for the question on why Google isn’t citing the source of the answer here, why is Google showing the definition from Oxford in the US and a branded result from Regus in the UK?
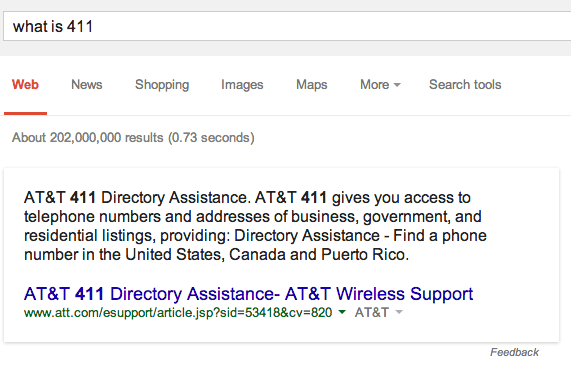
Also, how about a search for [what is 411], we get AT&T, which is a huge brand for telecommunication. Why are we showing results from AT&T? Why not pull from Wikipedia or Oxford here, and why not Verizon or another telecom? You can see why this gets scary:
The last example, which I did not share previously, touches on a spammy area, the Payday Loan area:
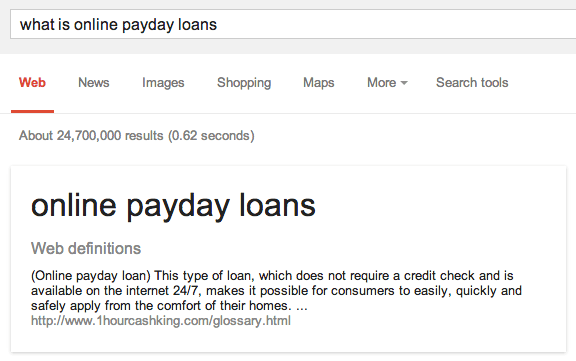
Google is displaying a site that is a parked domain that is looking to sell. A year ago, they had content with a glossary page, see the wayback machine. Today, it is just a parked domain.
Maybe the solution for Google is simply to license content from non-branded third-parties and stop scraping answers from sources that may make searchers scratch their heads with confusion?
Related stories
About the author
In 2019, Barry was awarded the Outstanding Community Services Award from Search Engine Land, in 2018 he was awarded the US Search Awards the "US Search Personality Of The Year," you can learn more over here and in 2023 he was listed as a top 50 most influential PPCer by Marketing O'Clock.
Barry can be followed on X here and you can learn more about Barry Schwartz over here or on his personal site.