Snowden Petition Blocked From Google? Like All Petitions, It Won’t Be When It Gets Enough Signatures
Search for “edward snowden petition” on Google to find the petition filed through the White House petitions site, and you’ll see something odd. The petition has no description, because the White House won’t let Google crawl the page. But it’s not a move against Snowden, as some might think. It’s part of how the petitions site has worked […]
![]() Search for “edward snowden petition” on Google to find the petition filed through the White House petitions site, and you’ll see something odd. The petition has no description, because the White House won’t let Google crawl the page. But it’s not a move against Snowden, as some might think. It’s part of how the petitions site has worked with search engines for some time.
Search for “edward snowden petition” on Google to find the petition filed through the White House petitions site, and you’ll see something odd. The petition has no description, because the White House won’t let Google crawl the page. But it’s not a move against Snowden, as some might think. It’s part of how the petitions site has worked with search engines for some time.
Here’s how the listing looks:
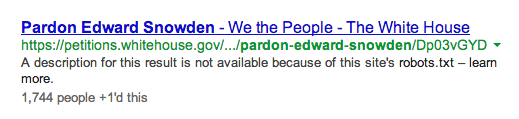
Notice the description: “A description for this result is not available because of the site’s robot.txt — learn more.”
iAcquire noted the oddity this week, that the page is listed, but with this odd description. The description is explaining that the page has been blocked from Google and other search engines such as Bing from indexing it.
How can a page that’s blocked still be listed? This is what’s known as a “link only” listing, where Google can guess at what the page is about from other pages linking to it to form a title. But, it can’t generate a description nor gather any information from the page itself, because it’s blocked, and Google cannot access the content on the page to show a description of the page.
In fact, all new petitions on the White House site are blocked like this, and have been since 2011, as shown by this copy of the robots.txt file via the Way Back Machine.
Why would this happen? The White House is blocking petitions that are below a certain threshold. Page that gain enough signatures get an official response, and that also means they get a new page in an area of the site (the responses area) that isn’t blocked.
The White House has a page explaining the threshold needed, though it doesn’t explain the search engine blocking. However, our understanding is that this is how things work — pages below a threshold of signatures don’t get indexed, mainly to help prevent people who might try to use the White House site to generate spam.
Get enough signatures, and you’re guaranteed a response — and also deemed Google-worthy. Snowden’s petition actually has over the required amount, so it should get an official response in the near future, and one that will be fully indexed by Google.
Related stories
New on Search Engine Land
About the author
In 2019, Barry was awarded the Outstanding Community Services Award from Search Engine Land, in 2018 he was awarded the US Search Awards the "US Search Personality Of The Year," you can learn more over here and in 2023 he was listed as a top 50 most influential PPCer by Marketing O'Clock.
Barry can be followed on X here and you can learn more about Barry Schwartz over here or on his personal site.