The dangers of misplaced third-party scripts
Most SEO tags like the title, canonical, etc. belong in the HTML HEAD but if placed in the BODY, Google and other search engines will ignore them. Here's how you fix it.
I was recently helping one of my team members diagnose a new prospective customer site to find some low hanging fruit to share with them.

When I checked their home page with our Chrome extension, I found a misplaced canonical tag. We added this type of detection a long time ago when I first encountered the issue.
What is a misplaced SEO tag, you might ask?
Most SEO tags like the title, meta description, canonical, etc. belong in the HTML HEAD. If they get placed in the HTML BODY, Google and other search engines will ignore them.
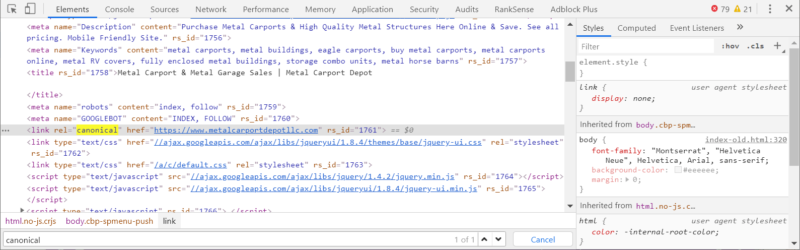
If you go to the Elements tab, you will find the SEO tags inside the <BODY> tag. But, these tags are supposed to be in the <HEAD>!
Why does something like this happen?
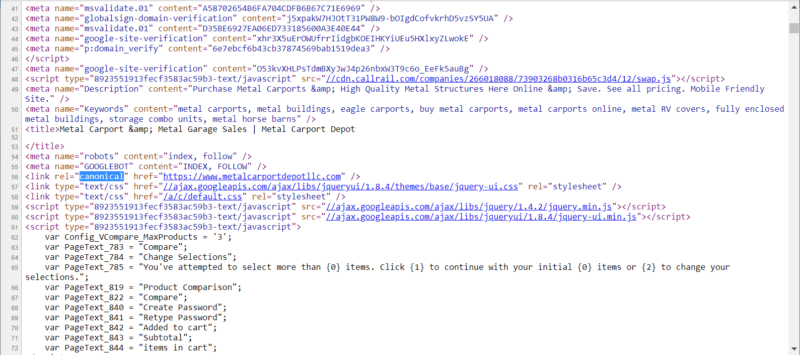

If we check the page using VIEW SOURCE, the canonical tag is placed correctly inside the HTML HEAD (line 56, while the <BODY> is in line 139.).
What is happening here?!
Is this an issue with Google Chrome?
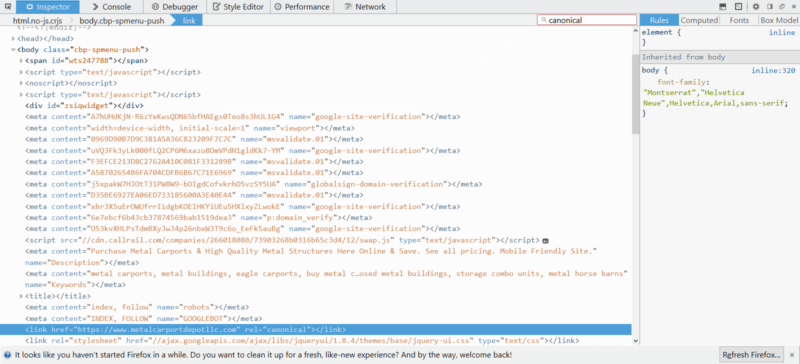
The canonical is also placed in the BODY in Firefox.

We have the same issue with Internet Explorer.

Edge is no exception.
We have the same problem with other browsers.
HTML parsing vs. syntax highlighting
Why is the canonical placed correctly when we check VIEW SOURCE, but not when we check it in the Elements tab?
In order to understand this, I need to introduce a couple of developer concepts: lexical analysis and syntax analysis.
When we load a source page using VIEW SOURCE, the browser automatically color codes programming tokens (HTML tags, HTML comments, etc).
In order to do this, the browser performs basic lexical analysis to break the source page into HTML tokens.
This task is typically performed by a lexer. It is a simple, and low-level task.
All programming language compilers and interpreters use a lexer that can break source text into language tokens.
When we load the source page with the Elements tab, the browser not only does syntax highlighting, but it also builds a DOM tree.
In order to build a DOM tree, it is not enough to know HTML tags and comments from regular text, you also need to know when a tag opens and closes, and their place in the tree hierarchy.
This syntactic analysis requires a parser.
An English spellchecker needs to perform a similar, two-phased analysis of the written text. First, it needs to translate text into nouns, pronouns, adverbs, etc. Then, it needs to apply grammar rules to make sure the part of speech tags are in the right order.
But why are the SEO tags placed in the HTML body?
Parsing HTML from Python
I wrote a Python script to fetch and parse some example pages with errors, find the canonical anywhere in the HTML, and print the DOM path where it was found.
After parsing the same page that shows misplaced SEO tags in the HTML Body, I find them correctly placed in the HTML head.
What are we missing?
Invalid tags in the HTML head
Some HTML tags are only valid in the HTML BODY. For example, <DIV> and <SPAN> tags are invalid in the HTML head.
When I looked closely at the HTML HEAD in our example, I found a script with a hardcoded <SPAN>. This means, the script was meant to be placed in the <BODY>, but the user incorrectly placed it in the head.
Maybe the instructions were not clear, the vendor omitted this information or the user didn’t know how to do this in WordPress.
I tested by moving the script to the BODY but still faced the misplaced canonical issue.
After a bit of trial and error, I found another script that when I moved it to the BODY, the issue disappeared.
While the second script didn’t have any hardcoded invalid tags, it was likely writing one or more to the DOM.
In other words, it was doing it dynamically.
But, why would inserting invalid tags, cause the browser to push the rest of the HTML in the head to the body?
Web browser error tolerance
I created a few example HTML files with the problems I discussed and loaded them in Chrome to show you what happens.
In the first example, I commented out the opening BODY tag. This removes it.
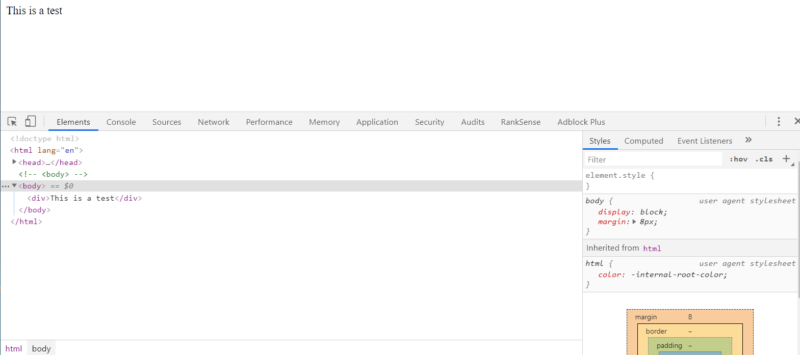
You can see that Chrome added one automatically.
Now, let’s see what happens if I add a <DIV> inside the HTML HEAD, which is invalid.

This is where it gets interesting. Chrome closed the HTML HEAD early and pushed the rest of the HEAD elements to the body, including our canonical tag and <DIV>.
In other words, Chrome assumed we forgot an opening <BODY> tag!
This should make it clear why misplaced tags in the HEAD can cause our SEO tags to end up in the BODY.
Now, let’s look at our second case where we don’t have a hardcoded invalid tag, but a script might write one dynamically.
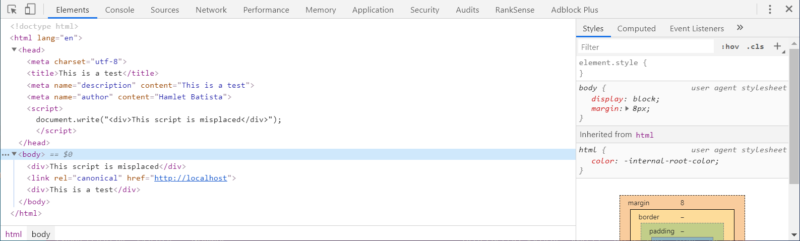
Here you see that if a script writes an invalid tag in the HTML head, it will cause the browser to close it early as before. We have exactly the same problem!
We didn’t see the problem with our Python parser because lxml (the Python parsing library) doesn’t try to fix HTML errors.
Why do browsers do this?
Browsers need to render pages that our Python script doesn’t need to do. If they try to render before correcting mistakes, the pages would look completely broken.
The web is full of pages that would completely break if web browsers didn’t accommodate for errors.
This article from HTML5Rocks provides a fascinating look inside web browsers and helps explain the behavior we see in our examples.
“The HTML5 specification does define some of these requirements. (WebKit summarizes this nicely in the comment at the beginning of the HTML parser class.)
Unfortunately, we have to handle many HTML documents that are not well-formed, so the parser has to be tolerant about errors.
We have to take care of at least the following error conditions:
The element being added is explicitly forbidden inside some outer tag. In this case, we should close all tags up to the one which forbids the element, and add it afterward.
Please read the full article or at least make sure to read at least the section on “Browser’s Error Tolerance” to get a better context.
How to fix this
Fortunately, fixing this problem is actually very simple. We have two alternatives. A lazy one and a proper one.
The proper fix is to track down scripts that insert invalid HTML tags in the head and move them to the HTML body.
The lazy and quickest fix is to move all SEO tags (and other important tags) before any third party scripts. Preferably, right after the opening <HEAD> tag.
You can see how I do it here.
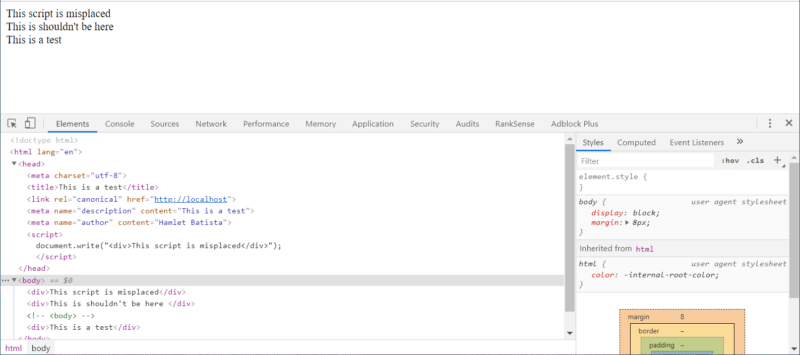
We still have the same invalid tag and script in the HTML head and the SEO tags are also in the head.
Is this a common problem?
I’ve been seeing this issue happening for many years now, and Patrick Stox has also reported seeing the same problem happening often to enterprise sites.
One of the biggest misconceptions about technical SEO is that you do it once and you are done. That would be the case if the sites didn’t change, users/developers didn’t make mistakes and/or Googlebot behavior didn’t change either.
At the moment that is hardly the case.
I’ve been advocating technical SEOs learn developer skills and I hope this case study illustrates the growing importance of this.
If you enjoyed this tip, make sure to attend my SMX West session on Solving Complex JavaScript Issues And Leveraging Semantic HTML5 next month. Among other things, I will share advanced research on how Googlebot and Bingbot handle script and HTML issues like the ones I mentioned here.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author