Automatic Algorithms Are Fundamentally Changing The Shape of SEO
If search engines -- such as Yandex in Russia -- are generating their search query algorithms automatically using "machine learning," does that mean we need a re-think of SEO practices? What is "machine learning" in this context and how does it work? Yandex may be a "regional" search engine, but they're putting forward some challenging views of how search engines are developing and will develop in future!
Many SEOs and SEO agencies aspire to run SEO automatically, using technology. Not surprisingly, it turns out that search engines are thinking along similar lines. Ilya Segalovich, the CTO of Yandex, mentioned during my visit to Yandex in Moscow, that he expects it to become easier to build search engines and that Google and Yandex’s competition is most likely to come from technologies based largely around “open source” style software readily available to developers.
The specific technologies which are likely to become “commoditized” in this way include crawlers, indexing and even machine learning algorithms. Says Ilya, “You won’t need 2,000 engineers to build a decent search engine. At some point, this will make search more competitive because more search engine components will be readily available and you’ll have the ability to achieve reach quickly.”
Don’t Ask A Search Engine Engineer How To Rank Your Site!
Yandex has adopted machine learning in a big way and I had a conversation with two of the brains behind the approach, Andrey Gulin and Andrey Plakhov.
Yes, you have to be named “Andrey” to get a senior post at Yandex! Andrey and Andrey did their best to explain to an “SEO” how their system works with Andrey Gulin amusingly saying along the way, “We’re surprised when SEOs ask how to rank my site, because I don’t know.” If you want to know why he says that – read on!

Andrey Gulin. Source:Yandex Moscow

Andrey Plakhov. Source: Yandex Moscow
Two Types Of Algorithms
Consider that there are two basic ways to create an algorithm; manually or by letting a computer develop one based on targets you set it. Simple, right? Perhaps we need to dig a little deeper.
Firstly, what’s an algorithm? Wikipedia tells us, “An algorithm is an effective method expressed as a finite list of well-defined instructions for calculating a function”. You see it’s simple – just a list!
So let’s imagine we’re a search engine and figure the process out for responding to a query for a keyword such as “search marketing company”.
The first thing we do is to compile all the different forms of data which we already have – or we can can collect in future – to decide between these different sites.
Building Our Own Simple Algorithm
So we might look at keyword inclusion in the page title, meta description, body content or in the links we point into the site. We might have a list like this:
- Find all pages which contain “search marketing company”.
- Find all pages which have links pointing to them associated with “search marketing company” via the anchor text or some associated text saying that on the same page.
- Build “search marketing company” corpus – in other words the full set of sites our search engine associates with the term.
Then we would score all pages in our corpus as follows:
- “search marketing company” in the page title – 10 points.
- “search marketing company” in inbound link anchor text – .02 points for each valid link.
- “search marketing company” in an H1 tag on the page – 3 points.
- For inclusion of “search marketing company” exact match in the body text – 3 points.
- List all pages in our corpus from highest points to lowest points.
- Sit back and wait for the user to be impressed with the relevance of our results!
Users Are Peculiar Beasts
You see, it’s really dead easy to run a search engine! All you need to do is to sit back and fiddle with the dials until the smile on the face of your users reaches from ear to ear! Except that users are peculiar beasts. They make life difficult for you by searching for all sorts of different things – and they don’t like to give you clues as to what they really intend.
So, the difficulty in adjusting the algorithm to achieve maximum relevance, is that you when you move things around for “search marketing company”, you will also change the results for navigational queries, where the user really wanted to find an organization called “Search Marketing Company”.
Fellow SearchEngineLand.com writer, Shari Thurow, regularly explains that there are several key categories of query such as “navigational”, “informational” or “commercial”. So one of the things you can do is to classify different types of queries using, ahem, “classifiers”. The trouble is, there aren’t just three categories so you’ll find you need to use many thousands of classifiers!
You don’t just need algorithms, you need lots of them. Source: Andy Atkins-Krüger
So now you’re faced with a dilemma – particularly since as the search engine engineers point out, they see a very high percentage of queries each days which they’ve never seen before. Looks like you need at least two levels of algorithms: one to classify queries and direct them to the correct algorithm – and then, the query-response algorithms themselves.
You could employ an army of search engineers to sit there and twiddle the knobs for each type of algorithm or to classify queries – or you could invent software to do it for you. Presto! That’s exactly what Yandex has launched in the last 18 months.
Yandex & “Machine Learning” Algorithms
Firstly, Yandex began by launching “Matrixnet” which was its “machine learning algorithm” then more recently came “Spectrum” which is focused on trying to better understand the user’s intent. You could say that “Spectrum” operates at the query classification level in my model and MatrixNet at the query ranking level shown in blue.
Back to the two Andreys, who explain how this “machine learning” works. Says Andrey Gulin, ” We have search quality juries, we call them assessors. These assessors judge a sample of results which we then look at to assess the signals with different queries giving different ranking factors.” And yes, if you’re asking if the assessors are human beings, they are indeed!
The assessors effectively determine the characteristics of great sites which become the targets for the algorithm to achieve. It then goes off with its known set of available signals and evolves a way of judging the ranking formula for the queries it receives, endeavouring to meet the quality targets it has been set by the assessors.
The Formula Can Change Very Rapidly
How is this different from ranking sites manually? Well, for one thing, the formulas can change on the fly.
Let’s assume that lots of SEOs discover that many links helps sites to rank for a particular term – if the new sites which end up ranking don’t fit the quality assessors original specifications, then MatrixNet is going to make an adjustment to get back to delivering the type of sites the assessors said they wanted.
Equally, if there’s a number of new site launches which offer still better quality content, but which don’t match exactly the live formula, MatrixNet is going to adjust its calculations to bring them into the picture.
One side effect is that ranking formulas have been growing in complexity. The graphic below shows that growth over a period of time – indeed, Yandex has found it necessary to develop technologies to handle the complexity of the formula. The machine learning algorithm itself also has to be “retrained” every couple of months with new information from the assessors and new potential signals to include.
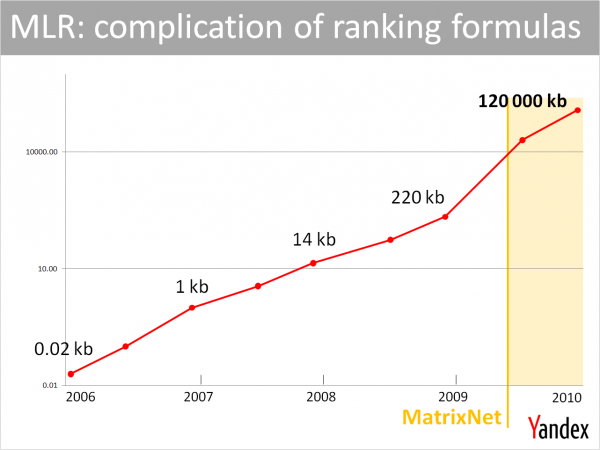
The increasing complexity of ranking formulas at Yandex. Source: Ilya Segalovich, Yandex
Meanwhile, my debate with Andrey and Andrey turns to obvious questions such as paid links and using click-throughs to rank sites. They confirmed that Yandex has several methods of identifying paid links – which it is important to do because of the potential distortions they can cause to results – apparently there are a number automatic link trading systems in Russia which they have to deal with. They have also accepted that sometimes paid links will feature in their algorithm and will even influence results (something I don’t remember Google admitting so far) – but these links would only be those on exceptionally high quality sites.
Furthermore, they make no secret about the fact that they do use clickstream data – in other words clickthroughs from the results pages to sites – as part of the ranking “formula”.
So I asked the inevitable question, namely would that mean that a good clickthrough rate would be a good factor to look for on a site? It turns out that sometimes that can produce a negative effect. Says Andrey Plakhov, “Clicks are not only used to show that sites are good, sometimes high clicks can be a bad feature – porn sites, for instance, would show this characteristic.”
Does Google Use Clickstream Data Too?
I did enquire if they thought that Google also uses clickthroughs (as some SEOs have postulated for some time but which I’ve never seen confirmed). Andrey Gulin explained, “In our experience, at the moment you can’t create a competitive search engine without using information about user behavior. Since it’s our experience that you can’t provide really good ranking without user behavior data and as Google’s ranking is great — so we suppose that they use clicks.”
So what does this all mean for the future of SEO? If search assessors have a major impact on deciding which sites should rank and which shouldn’t – maybe our systems should mimic assessors, since it turns out our ranking aspirations sit in the minds of the assessors which the machine learning algorithms constantly aim to adjust to. It’s also the reason why the two Andrey’s can’t tell SEOs how to rank their sites.
I note that many of the online information about how to rank in Yandex appears to be based in the time before they had machine learning. Now perhaps we need to start organising focus groups to assess what good sites are to get the best rankings instead? For sure, SEO thinking definitely needs some renewal!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author