Search 4.0: Social Search Engines & Putting Humans Back In Search
Previously I’ve covered what I dubbed Search 3.0, how search engines have evolved toward blending vertical or specialized results into “regular” web listings. Today, the step beyond that: Search 4.0, how personal, social and human-edited data can be used to refine search results. The Search Evolution So Far Before going ahead, let me summarize what […]
Previously I’ve covered what I dubbed Search 3.0, how search engines have evolved toward blending vertical or specialized results into “regular” web listings. Today, the step beyond that: Search 4.0, how personal, social and human-edited data can be used to refine search results.
The Search Evolution So Far
Before going ahead, let me summarize what I covered in my past article, in terms of how search engines have changed over time to create and rank the results you get when doing a search:
- Search 1.0 (1996): Pages ranked using “on-the-page” criteria
- Search 2.0 (1998): Pages ranked using “off-the-page” criteria
- Search 3.0 (2007): Vertical search results blended into regular search results
The evolution above is not perfect. For one thing, some “Search 3.0” blending started to happen years before 2007. It’s just that in 2007, I felt all the major search engines made the leap into Search 3.0 in a significant way.
As for Search 2.0, looking at off-the-page criteria such as links, Google kickstarted that heavily in 1998. However, some link analysis happened before then, and all the major search engines probably didn’t get on board to using it more fully until 1999-2001. But the launch of Google in 1998 remains the benchmark year in my mind, for that particular change.
The evolution is also only applicable to crawler-based search engines, those that use automation to gather web pages, store copies of them and search through the compiled index to create listings for searches. Yahoo was a major player using human power before 1996 and continued this way for years. Indeed in 1999, a majority of major search engines were presenting human-powered results. This quickly changed as Google grew. Yahoo made its human results “secondary” to crawler-based ones (then provided by Google) in October 2002. Today, all the major US-based search engines depend on crawler-based results.
To cap off the caveats, the evolution above is not the only way search engines can evolve. That’s just how things have largely gone with US-based search engines, which in turn tend to also be the major search engines for most countries around the world. There are exceptions. For example, Naver is the dominant search engine in Korea — and there, listings are largely human generated.
Search 4.0: The Human Factor
Onward to Search 4.0! As I said in my opening, to me this is the move for search engines to make use of human data as part of their ranking systems. In particular, it means human data generated by you, by those you know or by human editors.
Search engines already make use of some human data. All the major search engines, for example, monitor what we click on within the search results. This helps them determine if a particular listing is drawing more or less clicks than would be expected for the position it holds. For example, if the number two listing for a particular query is getting less clicks than “normal” for a listing in that spot, perhaps it’s a bad quality listing that should be replaced with another.
Another example: all the major search engines make heavy use of link data — and that link data is largely human data, humans both “voting” with their links and “tagging” pages by the words they use in the links. Google Now Reporting Anchor Text Phrases and Google Kills Bush’s Miserable Failure Search & Other Google Bombs provide more about how links are used in this fashion.
When I talk about putting human data into search results as part of Search 4.0, I mean things that are more aggressive or active than what I’ve covered above. I’ll start off with the most refined Search 4.0 implementation out there, Google’s personalized results.
Google: Search 4.0 Gets Personal
With Google Personalized Search, the web pages you visit, bookmark and things you click on within search results at Google are used to custom-tailor search results for you. The personalization is not as dramatic as with a place like Amazon, where if you purchase a book once, Amazon seems to continually push similar books like that at you forever. Shifts are far more subtle, mainly to help elevate results from sites you frequently visit.
To understand more, these articles go into depth about the process:
I’m fairly bullish on personalized search as an important addition to other factors (Search 1.0-3.0) in improving results. For one thing — better or worse — people often judge the relevancy of search results based on ego searches. Does a search engine find your home page, blog and related material when you search for yourself? Does it find your company? Personalized search is an ego search reinforcer. Because you go to your own places on the web often, Google senses that you want them to show up higher in search results, and they do. It’s a genius way to ensure anyone reviewing the service comes away pleased!
Of course, fulfilling ego searches can also be an relevancy advancement, not just a marketing ploy. There’s an excellent chance you’d have better searches if sites you visit more often get a bump in the search results. Personalized search can do this. In addition, over time, personalized search can potentially figure out other sites that are similar to those you visit and give them a relevancy boost.
Since Google expanded personalized search last year, there’s been one further major development. Personalized search uses searches over time to refine results. However, Google also has a system it is testing to refine results based on the last query you did, even if you aren’t taking part in the personalized search program.
“Previous Query” Refinement Coming To Hit Google Results explains more about how this works. It’s been used to improve the ads shown on Google for almost a year now, and it’s currently being tested to refine regular results. Google said that previous query refinement has been one of the strongest signals on how to personalized results so far.
Social Search: Promise Or Hype?
Last year, blogger Robert Scoble kicked off a round of “Facebook’s gonna kill Google” with a series of videos suggesting that because Facebook knows who your friends are, they’ll be able to apply that “social graph” data to improving search results.
The Promise & Reality Of Mixing The Social Graph With Search Engines was my response, a bucket of cold water explaining that using social data wasn’t some new idea that had never been tried before. The article went into depth explaining how Eurekster and Yahoo both assumed search could be “socialized” similar to photo sharing or bookmarking, only to find that wasn’t the case.
Yahoo had little take-up of its social search product. I’ve never seen the company explain why. My own suspicion is that take-up was low because search is NOT a social activity. I believe people tend to search when they have an immediate desire that needs fulfilling, and taking time away from the search activity to “share” with others is a distraction. Consider the person who has a broken water pipe. They might search quickly to find a plumber. They aren’t likely thinking at that moment that they want to tag and classify the search they conducted, much less the plumber they called. They just want the pipe fixed!
Eurekster has said that it found social activity worked better when people organized to build what it calls “Swickis,” search engines that hit only a custom collection of web sites related to a particular topic. Earlier this year, Eurekster formally came out of beta. However, the service has been entirely off-line for almost a week now. Practically no one has noticed, which speaks volumes to its usage and that aspect of the social search potential. Twitter, which some still view as a niche service, can hiccup for an hour and produce reams of blog attention. Eurekster goes silent, and the web stays silent about it.
I’m A Facebookholic & I Have 5,000 Friends
Still, couldn’t Facebook have more luck? For the record, when I spoke with Facebook director of engineering Aditya Agarwal about social search ideas last December, he was far more realistic than outsiders who hype what Facebook could do. In particular, he wasn’t certain how useful the social data actually would be for refining web search.
I plan to do a future article with Agarwal to explore this more. As a reminder, Facebook right now has no web search feature at all. And while it does have an ad deal with Microsoft, our previous Microsoft’s Facebook Ad Deal Doesn’t Include Search article covers how a search partner hasn’t been selected.
Let’s assume that Facebook does select a search partner, which it will need, since trying to index billions of pages and serve millions of queries each day is not an easy task (just ask Microsoft what it’s like to build that from scratch). What could it do with social data?
For one thing, it could monitor what people are clicking on in a potentially more “trusted” environment. Anyone can use web search anonymously, even sending in clickbots to make it seem like some particular listing is super hot. Having to register to be in Facebook and search from within there might make the clickstream data less noisy. But then again, it’s still a fairly open door that someone can walk through, if they want.
Facebook could tailor results based on what friends are searching on. If it knows what you and your 25 friends all seem to select from results, it could ensure those sites get ranking boosts for future searches. That’s very similar to personalized search, except it sounds full of extra friend-goodness, right?
The flaw here is plenty of people have friends on Facebook they don’t know. Some people collect friends for fun (and profit). Some people get friended by others just looking to build up their profiles. Some people you might friend not because you like them but because it’s easier to friend them than say no. Any of these instances can cause “pollution” of the social data that supposedly was going to improve your search results.
Consider also the case of someone who might work at some very conservative company but outside of work is a freeliving, devil-take-all person. Do they want coworkers who are friends to flavor their search results or those friends they hang out with when work is over?
Finally, privacy is an overlooked issue when it comes to social search. People often search for intensely private, personal things using search engines. Search engines are almost like confessionals, where people seek solutions to problems they might not tell real people that are close to them. With social search, do they have to remember to turn off a sharing feature that might be activated by default? And if it’s not on by default, will it get any take-up at all?
In the end, I think there is some potential to tapping into a social network and applying it to search. However, I still remains uncertain how that will unfold. It especially remains uncertain that this is somehow the secret sauce for anyone to jump past the current state of search.
Return To Humans: Hello Mahalo!
Earlier, I’d mentioned how Yahoo started off using human beings to create its search listings in the days before Google existed. Over time, the human soul in search was lost to reliance on the supposed scalability of machines. Anyone who wants to see how much we’ve handed over to machines need only search for buy cialis online on Google. At the moment, the results are littered with online discussion forums that have been “borrowed” by affiliates and others hawking deals.
Those pages will sit there for a day or two or three or potentially weeks, as Google usually tries to find an algorithmic solution to getting rid of them. The idea is you might have to suffer a bit in the short term until a long-term cure is found. But then like a virus that mutates, something else gets through, requiring a new long-term cure.
Enter humans. A human editor, reviewing results like that, can immediately spot junk that should get yanked. Even better, a human editor could act as a curator. How hard can it be to find 10 quality sites that should come up for that or other terms?
That exact human solution, of course, is what Mahalo has been banking on. Mahalo, launched last year, uses human editors to hand-pick top results. For background on the service, check out these past articles:
- Mahalo Launches With Human-Crafted Search Results
- Mahalo Greenhouse: Get Paid For Writing Search Results
- Mahalo Follow: Toolbar Gives You Human-Powered Alternatives To Searching, Surfing
- Mahalo Adds The Social Graph To Search
- Mahalo Adds More Social Features
As part of a talk I do on Search 3.0 and Search 4.0, I have some screenshots from last year that illustrate well how a human can indeed do better than the machines, for some queries. Remember the fires in Southern California at the end of last year. After a series of wide ranging ones, Malibu was hit with a second one a month later. Here’s what those searching on Google got in response:
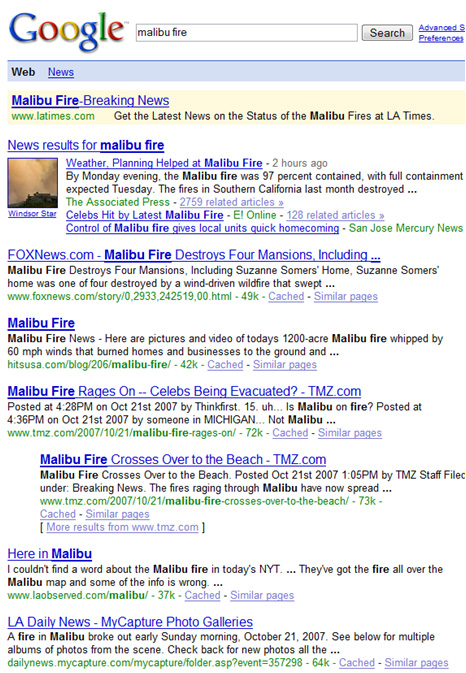
The news box at the top is great, but sometimes searchers skip past things like this and go to the first “real” result. That’s a story about the Malibu fire early in 2007, not at the end of the year. Other results were largely about the fire of October 2007, rather than November 2007 (which is what many searchers at the time I snapped this would have been interested in).
Here’s Yahoo:

Again, news results at the top, then unlike Google, places you’d expect to find news about the fire — the local paper; ironically a map of the fires on Google Maps that Google itself didn’t return; the Malibu city web site, as well as the fire department.
Here’s Microsoft Live Search:
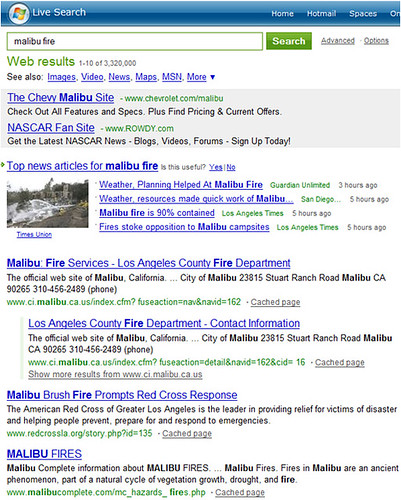
Very similar to Yahoo — a news box, the fire department, the Red Cross. What’s not to like? Well, let’s look at Mahalo:
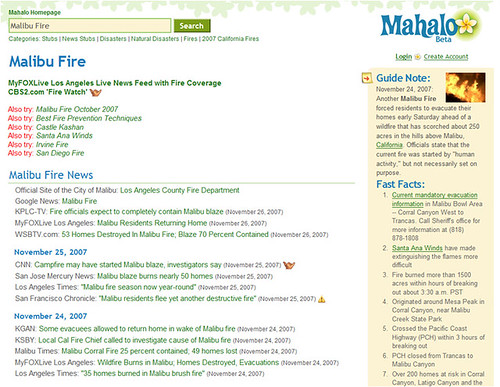
Note at the top that Mahalo’s human editors understand there’s a different fire that happened in the past, in October 2007, and offer a link to a page about that. Then there’s a nice list of news sources, followed by coverage by date. Over to the side, a synopsis of the current situation. If you could see more of the page, there was lots of other categorized information.
It’s nicely done. It’s very helpful. And it was created with a human thinking about what other humans might want to see, rather than machines guessing.
Scaling Humans
So is Mahalo founder Jason Calacanis onto the Google-killer, human crafted results? No. I think human review can be part of the solution, part of the Search 4.0 addition to what we have out there already — but humans can’t craft pages for every possible search. In addition, it’s hard to keep those pages maintained once they’ve been made. It’s also easy to cross over from being a search resource that points to other resources to becoming instead a destination site. I think a good search engine avoids that (and Who’s Ranking For Knol? Hello, Wikipedia! has more on this topic).
Mahalo can also be overwhelming. Try a search for hillary clinton and there’s category after category. Background links. News links. Photos. Videos. Bio links. Blogs and message boards. Plus, there’s even more. I think at some point, you want your search engine to make some key choices for you, not flood you with so many that you don’t know where to begin.
Another issue is that what Mahalo’s human editors do, machines can get close to. Hakia especially stands out here. Search for hillary clinton there, and you’ll see how listings are grouped into categories like Awards and Biography without humans being involved (and see Social Networking Through Search: Hakia Helps You Meet Others for background on how Hakia works).
More Humans
There is another major search project involving humans: Search Wikia. Backed by Wikipedia cofounder Jimmy Wales, the service aims to involve humans in rating pages, annotating them and helping determine the ranking algorithm for choices the machine side of the project makes.
The articles below have more background on the service:
Right now, the quality of the service is poor, as Search Wikia itself readily admits. There’s still lots of work to be done — and even with it, it might never succeed. But allowing humans into the process is, in my view, a good thing.
Indeed, even Google understands this. Last year, Google started doing some education about how human “signals” are already incorporated into its algorithm (see Google’s Human Touch and Google & Human Quality Reviews: Old News Returns). Aside from this, last year it also started testing a way for people to annotate search results — add those they like, remove some, suggest other ones.
Watch Personalized Search
Overall, there’s a role for humans, a way for them to be in the search process to enhance results. Actually, there will be several ways for them to be involved. Exactly how remains to be seen, of course.
Of the things I’ve outlined — personalized search, social search, human editors — I think personalized search is the one that will emerge as the major part of Search 4.0. That’s not to discount other things being tried, and they’ll contribute in some ways. But to me, personalized search has the most potential for another big relevancy leap. We’ll see!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author