Future SEO: Understanding Entity Search
Last month, I asked you to imagine the future of SEO with a focus on Entity Optimization as I interviewed veteran semantic strategist Barbara Starr. We discussed an “answer engine” that uses relevant, machine-recognizable “entities” on Web pages to answer specific, well-refined queries. The Hummingbird Update On September 26, Google took another step toward becoming […]
Last month, I asked you to imagine the future of SEO with a focus on Entity Optimization as I interviewed veteran semantic strategist Barbara Starr. We discussed an “answer engine” that uses relevant, machine-recognizable “entities” on Web pages to answer specific, well-refined queries.
The Hummingbird Update
On September 26, Google took another step toward becoming that answer engine with its Hummingbird update. In Danny Sullivan‘s live blog about the Hummingbird algorithm, he explains how Google is rapidly adopting semantic Web technology while still retaining parts of its old algorithm. This is Google’s solution for evolving from text links to answers. Such a system will display more precise results faster, as it’s based on semantic technology focused on user intent rather than on search terms.
To review Google’s progress in this direction: first came the Knowledge Graph, then Voice Search and Google Now — all providing answers, and sometimes even anticipating the questions. To serve these answers, Google relies on entities rather than keywords.
What Is An “Entity”?
For the purpose of this article, entities are people, places or things. One way of introducing entities is to recognize that Google’s Knowledge Graph is an entity graph and represents Google’s first step toward utilizing semantic search (or entity search).
What is “entity search”? Let’s keep it simple — it’s basically a more accurate method for bots to understand user intent while mapping additional verified sources to answer a search query.

Unstructured Vs. Structured Data
Over the past two decades, the Internet, search engines, and Web users have had to deal with unstructured data, which is essentially any data that has not been organized or classified according to any sort of pre-defined data model. Thus, search engines were able to identify patterns within webpages (keywords) but were not really able to attach meaning to those pages.
Semantic Search provides a method for classifying the data by labeling each piece of information as an entity — this is referred to as structured data. Consider retail product data, which contains enormous amounts of unstructured information. Structured data enables retailers and manufacturers to provide extremely granular and accurate product data for search engines (machines/bots) to consume, understand, classify and link together as a string of verified information.
Semantic or entity search will optimize much more than just retail product data. Take a look at Schema.org’s schema types — these schemas represent the technical language required to create a structured Web of data (entities with unique identifiers) — and this becomes machine-readable. Machine-readable structured data is disambiguated and more reliable; it can be cross-verified when compared with other sources of linked entity data (unique identifiers) on the Web.
Structured Data, Triples & Triplestores
Semantic search uses a vocabulary like Facebook’s Open Graph protocol or a syntax like RDFa or microdata to create structured data. Structured data can be imported and exported from triplestores. Hang in there and bear with me for a minute…
A triplestore is a database for the storage and retrieval of triples. Triplestores are optimized for the storage and retrieval of triples; they can store billions of triples.
What’s a triple? To simplify, let’s break down a sentence: the combination of three parts of speech which form any sentence include a Subject, Predicate and Object — also referred to by semantic strategists as a Triple. Triples are essentially linked entities composed of subject-predicate-object. The subject is the person/thing that carries out the action of the verb. The predicate is the action the subject takes. The object is the person/thing upon which the action is carried out.
Simple example of a triple: Mrs. Keller is teaching Algebra.
Mrs. Keller → subject → an entity
Algebra → object → an entity
is teaching → predicate or relationship → links the entities
Triples are expressed as Uniform Resource Identifiers (URIs). Answer engines will retrieve very specific data from large databases of triplestores storing billions of triples, and linking billions of subjects, objects, and predicates to form relationships. The result is more accurate answers to our queries by internally verifying validated data and relationships that link to trusted documents (structured data).
From Links To Answers
When we expand this logic and technology into a structured Web of data using schema Types that machines like Google, Bing and Yahoo! can understand, we have a machine like IBM’s Watson computer — an answer engine that answers our questions without using keywords or anchor text links.
Structured data creates the ability to provide detailed information about the meaning of your page content to search engines in a way that is easily processed and presented to users.
Understanding Vs. Indexing Data
Let’s circle back quickly to the question: what is an entity? Entities in Google’s Knowledge Graph are semantic data objects (schema types), each with a unique identifier. They are a collection of properties based on the attributes of the real world topics they represent, and they are also links representing the topic and its relationship to other entities.
When Google purchased Metaweb in July 2010, the Freebase database had 12 million entities. As of June 2012, Google’s Knowledge Graph was tracking 500 million entities and over 3.5 billion relationships between those entities. I imagine this has grown significantly over the last 16 months.
Adding machine-readable structured data to the Web will significantly improve a search engine’s capability to “understand” vs. “index” data, and it will provide two big breakthroughs for getting accurate answers to our questions when using an answer engine (or search engine):
- Machines will have a much better method for understanding user intent
- Machines will be able to draw from very large databases of structured data to match up the most reliable and accurate answer for the user i.e., verified structured data
Indexing Keywords Vs. Natural Language Understanding
SEO professionals, semantic strategists, and search engines are all in a transitional phase — from “assisting websites to get their unstructured data indexed” to “assisting websites by providing machine-readable structured data on the Web.”
Entity Extraction
To provide an example and dig a little deeper, the image below gives you a limited view of the Schema Type hierarchy for a “Place” and all its variations, e.g., Courthouse vs. Embassy vs. Apartment Complex or Canal. You will quickly discover that entity extraction essentially powers semantic search. Therefore, an entity represents the future of search visibility! And that includes authority, trust, findability, ranking and so forth.
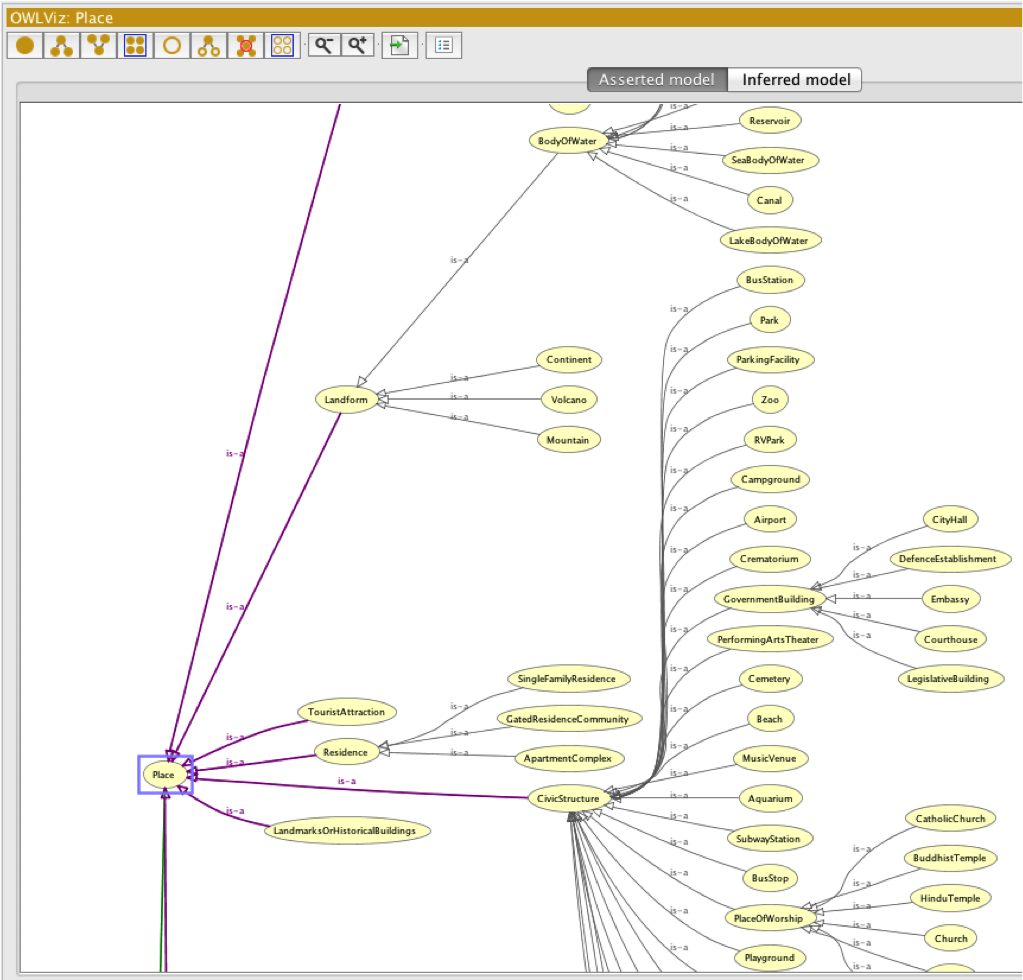
Schema.org “Place” hierarchy from Protégé
The semantic community, academic community, W3C, information scientists, Google, Bing, Yahoo!, astute enterprise websites, SEO professionals, Web developers, Web designers, Interactive agencies and many others have already begun to improve semantic search by building tools using semantic technology and implementing semantic markup on the Web.
- Introduction to Linked Data with Sandro Hawke (video: 38 minutes): Concepts and techniques of publishing Linked Data
- GoodRelations: Ontology for annotating e-commerce on the Web
- Google introduces Schema.org: Google, Bing, Yahoo! support structured data on Web pages
- Schema.org: A collection of schemas, i.e., html tags
- Tim Berners-Lee: The next web (video: 16 minutes): The power of data
- LinkedData.org: Publishing and connecting structured data
- Europeana Linked Open Data: Linked Open Data
- W3C Linked Data: What Is It?
- Protégé: Free, open source ontology editor
Making Your Business Data & Content Visible With Semantic Markup
I’ve said this dozens of times over the last 3 years: by using semantic markup, ALL your business data and digital content become easily accessible to search engines.
Business data consists of rich media video content, product reviews and ratings, location and contact information, business specialty details, special offers, product information and the list goes on…. Again, I recommend taking a look at Schema.org’s schema types.
Implementing semantic markup on your site will make your business data machine-readable to search engines, Web applications, in-car navigation systems, tablets, mobile devices, Apple maps, SIRI, Yelp maps, Linked Open Data , etc.
Semantic markup presents your business data as chocolate to the search engines — they love it and eat it up! Search engines understand it thoroughly and know how to aggregate the data for a better user experience in their SERPs. While search engines use structured data to display more relevant search results, you benefit because it’s known to boost CTR.
Final Thoughts
As semantic search becomes more widely adopted, the use of semantic markup allows you to give Google the data entity information it needs for its Knowledge Graph, which in turn provides better answers to user queries on various devices. In the meantime, you can continue the focus on keywords as semantic markup adoption increases. However, prepare for future SERP visibility by understanding and embracing semantic search as you become proficient at using correct structured markup.
The handwriting is on the wall: search engines want machine-readable content to provide more precise answers to user queries. Users want personalized answers at their fingertips as they favor smartphones/tablets over desktops/laptops (Monetate Q1 2013 Ecommerce Quarterly).
This makes it imperative for SEOs to understand semantic technology and entity search concepts. To get started, see Barbara Starr’s “10 Reasons Why Search Is In Vogue” for a list of 10 things you can do now.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author