How To Use Entity Markup To Appear In The Knowledge Graph
Search engines have increasingly been incorporating elements of semantic search to improve some aspect of the search experience — for example, using schema.org markup to create enhanced displays in SERPs (as in Google’s rich snippets). Elements of semantic search are now present at almost all stages of the search process, and the Semantic Web has […]
Search engines have increasingly been incorporating elements of semantic search to improve some aspect of the search experience — for example, using schema.org markup to create enhanced displays in SERPs (as in Google’s rich snippets).
Elements of semantic search are now present at almost all stages of the search process, and the Semantic Web has played a key role. Read on for more detail and to learn how to take advantage of this opportunity to make your web pages more visible in this evolution of search.

Under the Hood of Semantic Search
Although there has been some argument within the academic community that the Semantic Web “never happened,” it is blatantly clear that Google has adopted its own version of it. Other search and social engines have as well — I wrote an article back in September 2012 discussing how search and social engines are adopting the Semantic Web and semantic search, and gave a timeline of the adoption of semantic search by both the search and social engines.
It was very apparent, even then, that the search engines were moving in the direction of becoming answer engines, and that they were increasingly leveraging the Semantic Web and semantic search technology.
Schema.org Can Be Used To Extend The Knowledge Graph And In Knowledge Graph Panels
It was also clear at the time that Google was using schema.org to extend the knowledge graph. This was clearly illustrated at Google I/O in May 2013, when the Knowledge Graph was only in its infancy.
There, Google execs discussed their focus on answering and anticipating questions, as well as conversational search. The Hummingbird announcement several months later reinforced this new direction and showed that the Knowledge Graph project has been a roaring success thus far.

Knowledge Graph Extended With Schema.org markup, from Google I/O 2013 (Click to enlarge.)
Google I/O 2013
Prior to the advent of Hummingbird, we already saw semantic search techniques being used increasingly at every stage of the search process. At a higher level, you can define them approximately as:
- Constructing The Query: Google has shifted toward a better understanding of natural language, form-based or template-based queries, which makes search less reliant on users inputting precise keywords in order to return the results they’re looking for. They are improving on their ability to refine, understand and disambiguate user intent.
- Retrieving Relevant Information Resulting From The Query: Google is increasingly producing answers in addition to results. They’ve also become adept at understanding and suggesting relevant entities to a given query..
- Presenting The Results To The User: Google has tested various ways of presenting the data, documents and appropriate information summaries to the user in an engaging manner. Blended search results, Knowledge Graph entries, and rich snippets are all examples of this.
To Harness The Knowledge Graph, Teach It What “Things” Are On Your Site
The phase of the search process that occurs prior to the actual query is, of course, the indexing and analysis of content (web documents or datasets such as Freebase).
The goal of indexing is really to speed up answer presentation, and it now goes as far as pre-extracting and disambiguating entities (or identifying entities); thus, adding semantic markup to your web pages, where relevant is a must for on-page optimization.
Knowledge Graph: Understand/Uniquely Identify Every “Thing” In The World
The key to understanding semantic search is identity. Google’s knowledge graph initiative was intended to give an identity to every “thing” — or entity — in the world. This identity includes facts about the entity, as well as its relationships to other entities.
The purpose of creating these identities is so that search engines can better understand user intent for ambiguous search queries. (For example, should a search for the phrase [black eyed peas] return results for a food or a musical group?)
Understanding user intent is key to going from a search engine to an answer engine — rather than matching your query to keywords on a page, search engines want to understand what you are looking for based on context and provide you with the most relevant answer.
Microsoft has given a fairly concise definition of the entity recognition and disambiguation process:
The objective of an Entity Recognition and Disambiguation system is to recognize mentions of entities in a given text, disambiguate them, and map them to the entities in a given entity collection or knowledge base.
In Google’s case, that means recognizing entities on web pages or web documents and mapping them back to specific entities in their Knowledge Graph.
At this point, everyone is familiar with schema.org. Putting schema.org markup on your pages is a huge help in making them machine readable and assisting search engines; however, it is possible to take this even one step further.
In July of 2013, Freebase made an interesting and important announcement via Google+:

This means websites should now be marked up to indicate what “entities” they’re talking about in their content — telling search engines that these entities are the “sameAs” those on other sites or entity databases like Freebase.
Let us take a closer look at this. In the Google I/O 2013 talk given by Dan Brickley and Shawn Simister, they illustrated 2 examples of using this “SameAs” property.
The first way is by declaring your schema.org entity (whatever it is) to be the same as some other web page, like Wikipedia for example. Here is an example:
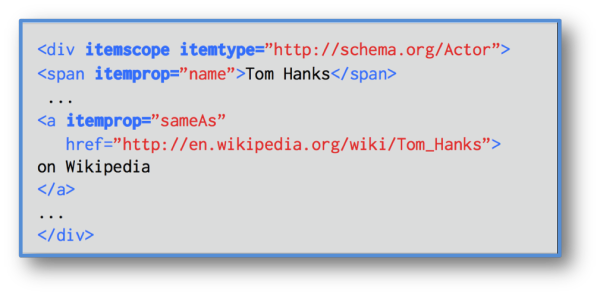
Schema.org “SameAs” mapping back to a URL
The second way is by associating your entity with an ID within a knowledge database, such as Freebase:
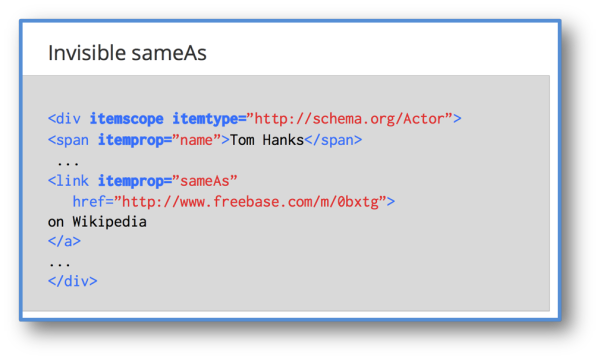
Schema.org disambiguated (using “SameAs”) to a Freebase MID for the item
What Is A Freebase MID & How Do I Find One?
For those of you not familiar, Freebase is “a community-curated database of well-known people, places and things” — in other words, a very large database of entities. Every entity in Freebase is identified by a machine ID (MID), which is basically an assigned ID number. MIDs take the form of [/m/xxxxx], where [xxxxx] represents a string of numbers and lower-case letters of variable length.
Let’s assume you want to look up a MID to help the search engines disambiguate an entity on your page. I will use the example of Danny Sullivan. If I go to Freebase and look him up using the search box at the top of the page, I get the result below:
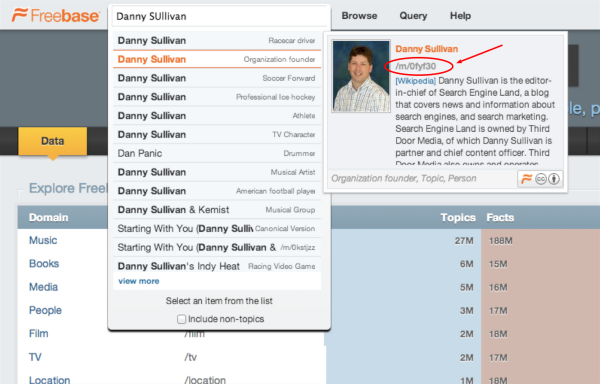
(Click to enlarge.)
As you can see, there are several Danny Sullivans to choose from. I selected the “organization founder,” as that is the Danny Sullivan intended here. You can see that his unique ID in Freebase (or MID) is [/m/0fyf30].
We could thus use his Freebase MID to label him as a specific entity (and disambiguate him from other Danny Sullivans) as follows:

Markup with “Danny Sullivan” disambiguated and mapped to his freebase MID.
For a great use case on entity mapping, check out “I Am an Entity: Hacking the Knowledge Graph” on the Moz blog.
Enrich Your Entities For Maximum Visibility
Remember to fully specify every property of your entity for maximum visibility in the search engines, and also to qualify for complete rich snippet displays.
This was further illustrated in Google’s announcement last week regarding event data. You can see here that complete information is imperative, and you can use options ranging from microdata to JSON-LD as specified in this Search Engine Land article.

Complete Information is Imperative.
Duplicate Markup Is Perhaps Analogous To Duplicate Content
Another item worthy of note: structured data is becoming so prolific that there is now a need to identify official listings for that data, especially in certain more popular categories of markup.
Google referenced this in its announcements about adding events to the Knowledge Graph. The danger of replicating events that are not associated with the official listing is now becoming an issue for a company that wants to display only the most official listing in its “knowledge panel” or “answer box.”
Summary/Takeaways
- A key concept in the Knowledge Graph is that of identity. Part of the Knowledge Graph initiative is to teach the Knowledge Graph about every entity in the world, giving it a unique “identity” which describes all associated properties and relationships to other entities.
- You can facilitate disambiguation of your entity in schema.org by using the “sameAs” property. This property can tell the Knowledge Graph that a particular instance of a “thing” in a web page is the same as that of a Wikipedia URL or Freebase MID.
- We are heading toward a significant proliferation of markup on the web. For example, on the web, the same event may be listed on multiple websites. In these cases, the markup from the most official website would be used in the knowledge panel.
- Information describing an entity in schema.org must be complete and rich. The same can apply to rich snippets when showing up in the organic section of search results on the page. It is best to populate as many fields as possible with accurate information for any field/property when using schema.org on a web page.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author