Google Blog Search: Now With Full-Text Post Indexing
It’s been about two months since Google Blog Search was relaunched with a new front page that summarizes stories. I talked with Google more about some of the inner workings at the end of October and finally am getting around to posting this, spurred by one of the planned changes becoming official. Google Blog Search […]

It’s been about two months since Google Blog Search was relaunched with a new front page that summarizes stories. I talked with Google more about some of the inner workings at the end of October and finally am getting around to posting this, spurred by one of the planned changes becoming official. Google Blog Search now uses the full-text of posts (in most cases), rather than using whatever was in a blog’s feed (which could often be only part of a post).
It was always annoying that Google Blog Search only depended on what was put out in a feed, rather than actually indexing the full-text of a blog post. Some publishers don’t put out full-text feeds (like here on Search Engine Land) for a variety of reasons, including the fact that putting out a full-text feed often is misinterpreted by others as a right to reprint a post in its entirety without getting formal permission.
Problem solved! Vanessa Fox’s recent Google Blog Search Changes How It Indexes Posts article covers how Google’s now officially confirmed for the first time that blog posts are being spidered. From what Google posted to its support groups on the subject:
We have changed the way we index blog posts to include the full content of the page. We’ve had occasional complaints about the use of the feed content, particularly the problem with partial feeds that you mentioned. The indexing change has improved the results for a lot of queries, both because we have the full content of the page and because we extract links that are missing from the feeds.
It’s a welcome change. When I talked to Google about it in October, they said it was in the process of being rolled out slowly. Now it is fully live for all new posts that get into Google Blog Search. However, some older posts may not be fully indexed. Google expects that by early 2009, all pages indexed by Google Blog Search since June 2005 — which it said are in the billions — will be fully indexed.
And how do you get in Google Blog Search again? If you’re not already there, the easiest way is to “ping” the service with your blog’s home page or your blog’s feed. You can use this submission form. Better, your blog should automatically ping Google each time a post goes up. Most blogging software is either already enabled to do this or it’s simple to add it. But Google provides further instructions here.
In the past, pinging made Google simply grab the latest post as shown in your feed, which is why those putting out only partial feeds did not have their posts fully indexed. Now, a ping is supposed to cause Google to immediately grab the full text of your post (I haven’t tested this yet, however). If it works as advertised, that means within seconds, your full post should be indexed and searchable within Google Blog Search.
A downside to full-text indexing is something that Barry Schwartz noted earlier, as full-text indexing got rolled out unannounced over the past few weeks. Blogs often have blogrolls, links to other blogs. Now that full-text indexing is being done, links from these blogrolls caused some people to think there were new blog posts being done about them. From what Google also posted in its groups about the issue:
The downside of this change is that we see more results that match only the blogroll and other parts of the page that are common to all of a blog’s posts.
We expected some problems from blogroll matches, but may have underestimated the impact on searches using the link: operator or where the query matches a blog or blogger’s name. We do expect to fix the problem you’re seeing. We’ll use the full page content, but exclude the content that isn’t really part of the post. I’m not sure if we’ll be able to make the change before the end of the year, but we are working on it and are pretty confident that it can be solved. We’ll post an update here when we’ve got a solution.
Google also just sent me this update:
Yes, we’ve got a change that should help with the blogroll issue. Although, it’s not 100% perfect, it performs quite well in our tests. We deployed it for link: queries yesterday and hope to have it deployed for all queries in the next few weeks.
Meanwhile, what about how things are going with the new front page to Google Blog Search? One issue that was plaguing Google Blog Search soon after launch was that spam blogs seemed to be getting featured and sometimes embarrassing play within the service.
Jeremy Hylton, a software engineer who works on the Google Blog Search project, said that Google was aiming to get more reputable blogs featured, that Google Blog Search has an internal ranking of blogs by quality and authority that it could use. Looking today, things seem pretty clean — so I assume they’ve notched up the standards.
A confusing thing to me after Google Blog Search launched was the order story “clusters” or “groups” are listed on the home page as well as the subject-specific pages, such as Technology. Each group has a box that shows you the number of blogs estimated to be discussing a topic and the time period where the discussion is stretching over:
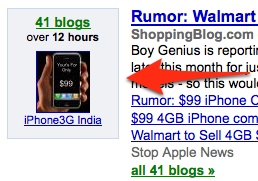
The screenshot above shows how a story about Walmart rumored to be selling iPhones has been mentioned on 41 blogs over 12 hours. Now consider what comes below it:
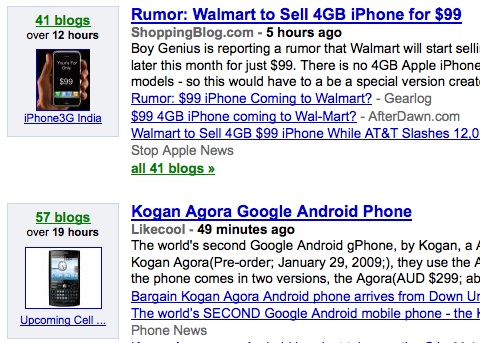
See how under the iPhone story there’s a another story group about a Google Android phone being released in Korea. How come the iPhone story mentioned on 41 blogs over 12 hours trumps the Android story with 57 blogs mentioning it over 18 hours?
Hylton said that part of the ranking process is to look at the “burst of activity” around a story. For example, a story with a sharp spike in mentions that’s recent compared to other stories might come higher on the list, being deemed newer news.
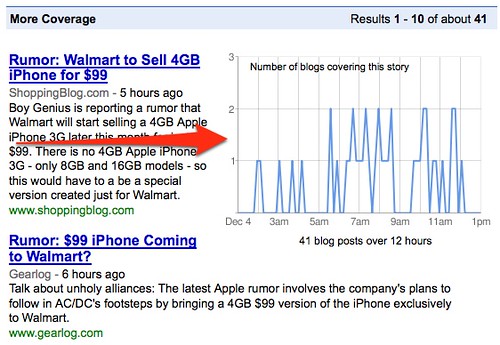
To see some of the spikes, check out any story’s “cluster” or “group” page. I keep using quotes because Google itself doesn’t have a name for these. But you get to them by clicking on the green link showing the number of blogs talking about a particular story. Here’s one for the Walmart iPhone story that I mentioned. On it, you can see a chart on the left showing the number of blogs covering the story and when those stories were spotted:
As a side note, while each story cluster/group has its own summary page, those URLs sadly don’t seem to remain over time. I had examples from things we discussed back in October like this cluster which now simply resolves to the Google Blog Search home page. I wish the URLs would continue working permanently.
Also related, watch for those story cluster pages to be enhanced over time. Hylton said that Google’s looking at ways they can build out more context about a particular story.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.