A guide to machine learning in search: Key terms, concepts and algorithms
Want to understand how machine learning impacts search? Learn how Google uses machine learning models and algorithms in search.
When it comes to machine learning, there are some broad concepts and terms that everyone in search should know. We should all know where machine learning is used, and the different types of machine learning that exist.
Read on to gain a better grasp of how machine learning impacts search, what the search engines are doing and how to recognize machine learning at work. Let’s start with a few definitions. Then we’ll get into machine learning algorithms and models.
Machine learning terms
What follows are definitions of some important machine learning terms, most of which will be discussed at some point in the article. This is not intended to be a comprehensive glossary of every machine learning term. If you want that, Google provides a good one here.
- Algorithm: A mathematical process run on data to produce an output. There are different types of algorithms for different machine learning problems.
- Artificial Intelligence (AI): A field of computer science focused on equipping computers with skills or abilities that replicate or are inspired by human intelligence.
- Corpus: A collection of written text. Usually organized in some way.
- Entity: A thing or concept that is unique, singular, well-defined and distinguishable. You can loosely think of it as a noun, though it’s a bit broader than that. A specific hue of red would be an entity. Is it unique and singular in that nothing else is exactly like it, it is well defined (think hex code) and it is distinguishable in that you can tell it apart from any other color.
- Machine Learning: A field of artificial intelligence, focused on the creation of algorithms, models and systems to perform tasks and generally to improve upon themselves in performing that task without being explicitly programmed.
- Model: A model is often confused with an algorithm. The distinction can get blurry (unless you’re a machine learning engineer). Essentially, the difference is that where an algorithm is simply a formula that produces an output value, a model is the representation of what that algorithm has produced after being trained for a specific task. So, when we say “BERT model” we are referring to the BERT that has been trained for a specific NLP task (which task and model size will dictate which specific BERT model).
- Natural Language Processing (NLP): A general term to describe the field of work in processing language-based information to complete a task.
- Neural Network: A model architecture that, taking inspiration from the brain, include an input layer (where the signals enter – in a human you might think of it as the signal sent to the brain when an object is touched)), a number of hidden layers (providing a number of different paths the input can be adjusted to produce an output), and the output layer. The signals enter, test multiple different “paths” to produce the output layer, and are programmed to gravitate towards ever-better output conditions. Visually it can be represented by:
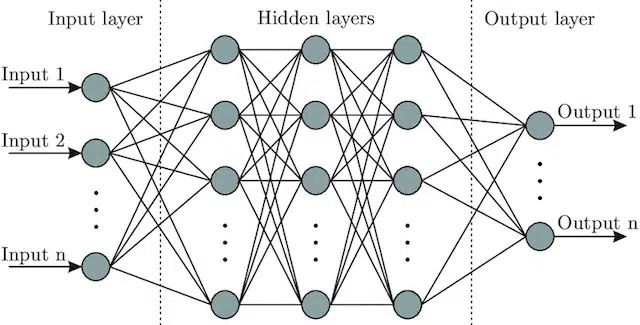
Artificial intelligence vs. machine learning: What’s the difference?
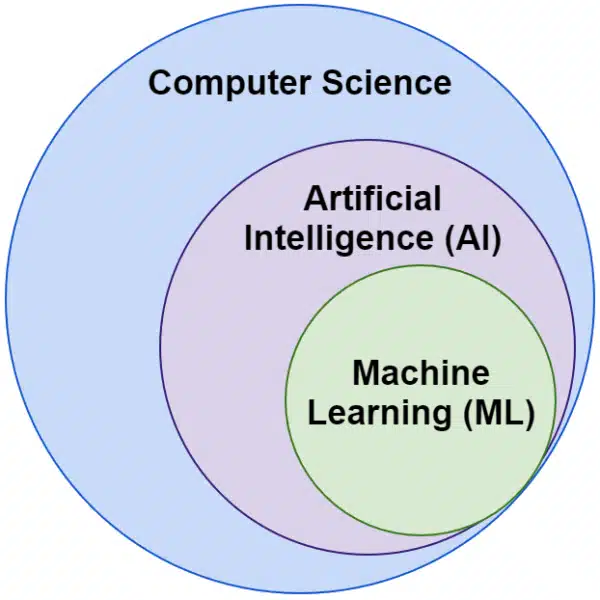
Often we hear the words artificial intelligence and machine learning used interchangeably. They are not exactly the same.
Artificial intelligence is the field of making machines mimic intelligence, whereas machine learning is the pursuit of systems that can learn without being explicitly programmed for a task.
Visually, you can think of it like this:
Google’s machine learning-related algorithms
All the major search engines use machine learning in one or many ways. In fact, Microsoft is producing some significant breakthroughs. So are social networks like Facebook through Meta AI with models such as WebFormer.
But our focus here is SEO. And while Bing is a search engine, with a 6.61% U.S. market share, we won’t focus on it in this article as we explore popular and important search-related technologies.
Google uses a plethora of machine learning algorithms. There is literally no way you, me, or likely any Google engineer could know them all. On top of that, many are simply unsung heroes of search, and we don’t need to explore them fully as they simply make other systems work better.
For context, these would include algorithms and models like:
- Google FLAN – which simply speeds up, and makes less computationally costly the transfer of learning from one domain to another. Worth noting: In machine learning, a domain does not refer to a website but rather to the task or clusters of tasks it accomplishes, like sentiment analysis in Natural language Processing (NLP) or object detection in Computer Vision (CV).
- V-MoE – the only job of this model is to allow for the training of large vision models with fewer resources. It’s developments like this that allow for progress by expanding what can be done technically.
- Sub-Pseudo Labels – this system improves action recognition in video, assisting in a variety of video-related understandings and tasks.
None of these directly impact ranking or layouts. But they impact how successful Google is.
So now let’s look at the core algorithms and models involved with Google rankings.
RankBrain
This is where it all started, the introduction of machine learning into Google’s algorithms.
Introduced in 2015, the RankBrain algorithm was applied to queries that Google had not seen before (accounting for 15% of them). By June 2016 it was expanded to include all queries.
Following huge advances like Hummingbird and the Knowledge Graph, RankBrain helped Google expand from viewing the world as strings (keywords and sets of words and characters) to things (entities). For example, prior to this Google would essentially see the city I live in (Victoria, BC) as two words that regularly co-occur, but also regularly occur separately and can but don’t always mean something different when they do.
After RankBrain they saw Victoria, BC as an entity – perhaps the machine ID (/m/07ypt) – and so even if they hit just the word “Victoria,” if they could establish the context they would treat it as the same entity as Victoria, BC.
With this they “see” beyond mere keywords and to meaning, just our brains do. After all, when you read “pizza near me” do you understand that in terms of three individual words or do you have a visual in your head of pizza, and an understanding of you in the location you’re in?
In short, RankBrain helps the algorithms apply their signals to things instead of keywords.
BERT
BERT (Bidirectional Encoder Representations from Transformers).
With the introduction of a BERT model into Google’s algorithms in 2019, Google shifted from unidirectional understanding of concepts, to bidirectional.
This was not a mundane change.
The visual Google included in their announcement of their open-sourcing of the BERT model in 2018 helps paint the picture:
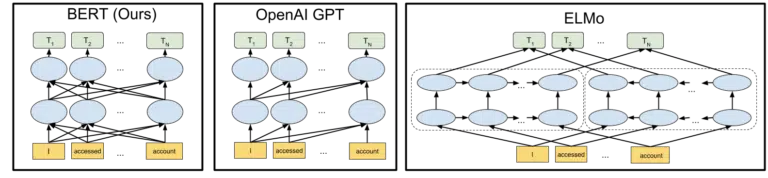
Without getting into detail on how tokens and transformers work in machine learning, it’s sufficient for our needs here to simply look at the three images and the arrows and think about how in the BERT version, each of the words gains information from the ones on either side, including those multiple words away.
Where previously a model could only apply insight from the words in one direction, now they gain a contextual understanding based on words in both directions.
A simple example might be “the car is red”.
Only after BERT was red understood properly to be the color of the car, because until then the word red came after the word car, and that information wasn’t sent back.
As an aside, if you’d like to play with BERT, various models are available on GitHub.
LaMDA
LaMDA has not yet been deployed in the wild, and was first announced at Google I/O in May of 2021.
To clarify, when I write “has not yet been deployed” I mean “to the best of my knowledge.” After all, we found out about RankBrain months after it was deployed into the algorithms. That said, when it is it will be revolutionary.
LaMDA is a conversational language model, that seemingly crushes current state-of-the-art.
The focus with LaMDA is basically two-fold:
- Improve reasonableness and specificity in conversation. Essentially, to ensure that a response in a chat is reasonable AND specific. For example, to most questions the reply “I don’t know” is reasonable but it is not specific. On the other hand, a response to a question like, “How are you?” that is, “I like duck soup on a rainy day. It’s a lot like kite flying.” is very specific but hardly reasonable.
LaMDA helps address both problems. - When we communicate, it is rarely a linear conversation. When we think of where a discussion might start and where it ends, even if it was about a single topic (for example, “Why is our traffic down this week?”), we generally will have covered different topics that we would not have predicted going in.
Anyone who has used a chatbot knows they are abysmal in these scenarios. They do not adapt well, and they do not carry past information into the future well (and vice-versa).
LaMDA further addresses this problem.
A sample conversation from Google is:

We can see it adapting far better than one would expect from a chatbot.
I see LaMDA being implemented in the Google Assistant. But if we think about it, enhanced capabilities in understanding how a flow of queries works on an individual level would certainly help in both the tailoring of search result layouts, and the presentation of additional topics and queries to the user.
Basically, I’m pretty sure we’ll see technologies inspired by LaMDA permeate non-chat areas of search.
KELM
Above, when we were discussing RankBrain, we touched on machine IDs and entities. Well, KELM, which was announced in May 2021, takes it to a whole new level.
KELM was born from the effort to reduce bias and toxic information in search. Because it is based on trusted information (Wikidata), it can be used well for this purpose.
Rather than being a model, KELM is more like a dataset. Basically, it is training data for machine learning models. More interesting for our purposes here, is that it tells us about an approach Google takes to data.
In a nutshell, Google took the English Wikidata Knowledge Graph, which is a collection of triples (subject entity, relationship, object entity (car, color, red) and turned it into various entity subgraphs and verbalized it. This is most easily explained in an image:
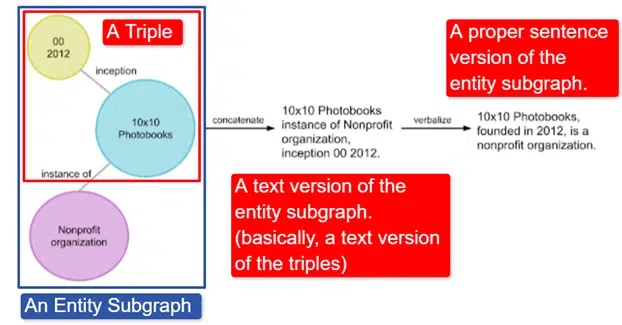
In this image we see:
- The triple describes an individual relationship.
- The entity subgraph mapping a plurality of triples related to a central entity.
- The text version of the entity subgraph.
- The proper sentence.
This is then usable by other models to help train them to recognize facts and filter toxic information.
Google has open-sourced the corpus, and it is available on GitHub. Looking at their description will help you understand how it works and its structure, if you’d like more information.
MUM
MUM was also announced at Google I/O in May 2021.
While is it revolutionary, it’s deceptively simple to describe.
MUM stands for Multitask Unified Model and it is multimodal. This means it “understands” different content formats like test, images, video, etc. This gives it the power to gain information from multiple modalities, as well as respond.
Aside: This is not the first use of the MultiModel architecture. It was first presented by Google in 2017.
Additionally, because MUM functions in things and not strings, it can collect information across languages and then provide an answer in the user’s own. This opens the door to vast improvements in information access, especially for those who speak languages that are not catered to on the Internet, but even English speakers will benefit directly.
The example Google uses is a hiker wanting to climb Mt Fuji. Some of the best tips and information may be written in Japanese and completely unavailable to the user as they won’t know how to surface it even if they could translate it.
An important note on MUM is that the model not only understands content, but can produce it. So rather than passively sending a user to a result, it can facilitate the collection of data from multiple sources and provide the feedback (page, voice, etc.) itself.
This may also be a concerning aspect of this technology for many, myself included.
Where else machine learning is used
We’ve only touched on some of the key algorithms you’ll have heard of and that I believe are having a significant impact on organic search. But this is far from the totality of where machine learning is used.
For instance, we can also ask:
- In Ads, what drives the systems behind automated bidding strategies and ad automation?
- In News, how does the system know how to group stories?
- In Images, how does the system identify specific objects and types of objects?
- In Email, how does the system filter spam?
- In Translation, how does the system deal learn new words and phrases?
- In Video, how those the system learn which videos to recommend next?
All of these questions and hundreds if not many thousands more all have the same answer:
Machine learning.
Types of machine learning algorithms and models
Now let’s walk through two supervision levels of machine learning algorithms and models – supervised and unsupervised learning. Understanding the type of algorithm we’re looking at, and where to look for them, is important.
Supervised learning
Simply put, with supervised learning the algorithm is handed fully labeled training and test data.
This is to say, someone has gone through the effort of labeling thousands (or millions) of examples to train a model on reliable data. For example, labeling red shirts in x number of photos of people wearing red shirts.
Supervised learning is useful in classification and regression problems. Classification problems are fairly straightforward. Determining if something is or is not a part of a group.
An easy example is Google Photos.
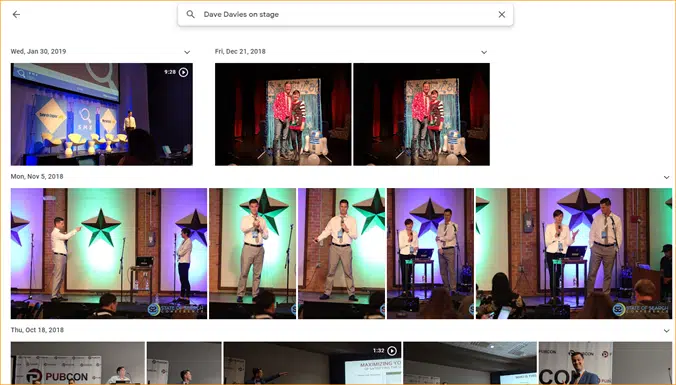
Google has classified me, as well as stages. They have not manually labeled each of these pictures. But the model will have been trained on manually labeled data for stages. And anyone who has used Google Photos knows that they ask you to confirm photos and the people in them periodically. We are the manual labelers.
Ever used ReCAPTCHA? Guess what you’re doing? That’s right. You regularly help train machine learning models.
Regression problems, on the other hand, deal with problems where there is a set of inputs that need to be mapped to an output value.
A simple example is to think of a system for estimating the sale price of a house with the input of square feet, number of bedrooms, number of bathrooms, distance from the ocean, etc.
Can you think of any other systems that might carry in a wide array of features/signals and then need to assign a value to the entity (/site) in question?
While certainly more complex and taking in an enormous array of individual algorithms serving various functions, regression is likely one of the algorithm types that drives the core functions of search.
I suspect we’re moving into semi-supervised models here – with manual labeling (think quality raters) being done at some stages and system-collected signals determining the satisfaction of users with the result sets being used to adjust and craft the models at play.
Unsupervised learning
In unsupervised learning, a system is given a set of unlabeled data and left to determine for itself what to do with it.
No end goal is specified. The system may cluster similar items together, look for outliers, find co-relation, etc.
Unsupervised learning is used when you have a lot of data, and you can’t or don’t know in advance how it should be used.
A good example might be Google News.
Google clusters similar news stories and also surfaces news stories that didn’t previously exist (thus, they are news).
These tasks would best be performed by mainly (though not exclusively) unsupervised models. Models that have “seen” how successful or unsuccessful previous clustering or surfacing has gone but not be able to fully apply that to the current data, which is unlabeled (as was the previous news) and make decisions.
It’s an incredibly important area of machine learning as it relates to search, especially as things expand.
Google Translate is another good example. Not the one-to-one translation that used to exist, where the system was trained to understand that word x in English is equal to word y in Spanish, but rather newer techniques that seek out patterns in usage of both, improving translation through semi-supervised learning (some labeled data and much not) and unsupervised learning, translating from one language into a completely unknown (to the system) language.
We saw this with MUM above, but it exists in other papers and models are well.
Just the beginning
Hopefully, this has provided a baseline for machine learning and how it’s used in search.
My future articles won’t just be about how and where machine learning can be found (though some will). We’ll also dive into practical applications of machine learning that you can use to be a better SEO. Don’t worry, in those cases I’ll have done the coding for you and generally provide an easy-to-use Google Colab to follow along with, helping you answer some important SEO and business questions.
For instance, you can use direct machine learning models to evolve your understanding of your sites, content, traffic and more. My next article will show you how. Teaser: time series forecasting.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author