Biased language models can result from internet training data
The controversy around AI researcher Timnit Gebru’s exit from Google, and what biased language models may mean for the search industry.
Last year, Google announced BERT, calling it the largest change to its search system in nearly five years, and now, it powers almost every English-based query. However, language models like BERT are trained on large datasets, and there are potential risks associated with developing language models this way.
AI researcher Timnit Gebru’s departure from Google is tied to these issues, as well as concerns over how biased language models may affect search for both marketers and users.
A respected AI researcher and her exit from Google
Who she is. Prior to her departure from Google, Gebru was best known for publishing a groundbreaking study in 2018 that found that facial analysis software was showing an error rate of nearly 35% for dark-skinned women, compared to less than 1% for light-skinned men. She is also a Stanford Artificial Intelligence Laboratory alum, advocate for diversity and critic of the lack thereof among employees at tech companies, and a co-founder of Black in AI, a nonprofit dedicated to increasing the presence of Black people in the AI field. She was recruited by Google in 2018, with the promise of total academic freedom, becoming the company’s first Black female researcher, the Washington Post reported.
Why she no longer works at Google. Following a dispute with Google over a paper she coauthored (“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”) discussing the possible risks associated with training language models on large datasets, Gebru was informed that her “resignation” had been expedited — she was on vacation at the time and had been promoted to co-lead of the company’s Ethical Artificial Intelligence team less than two months prior.
In a public response, senior vice president of Google AI, Jeff Dean, stated that the paper “ignored too much relevant research,” “didn’t take into account recent research,” and that the paper was submitted for review only a day prior to its deadline. He also said that Gebru listed a number of conditions to be met in order to continue her work at Google, including revealing every person Dean consulted with as part of the paper’s review process. “Timnit wrote that if we didn’t meet these demands, she would leave Google and work on an end date. We accept and respect her decision to resign from Google,” he said.
In a series of tweets, she stated “I hadn’t resigned—I had asked for simple conditions first,” elaborating that “I said here are the conditions. If you can meet them great I’ll take my name off this paper, if not then I can work on a last date. Then she [Gebru’s skip-level manager] sent an email to my direct reports saying she has accepted my resignation.”
When approached for further comment, Google had nothing more to add, instead pointing to Dean’s public response and a memo from CEO Sundar Pichai.
Although the nature of her separation from Google is disputed, Gebru is now among a growing number of former Google employees who have dared to dissent and faced the consequences. Her advocacy for marginalized groups and status as both a leader in AI ethics and one of the few Black women in the field has also drawn attention to Google’s diversity, equality and inclusion practices.
Gebru’s paper may have painted an unflattering image of Google technology
The research paper, which is not yet publicly available, presents an overview of risks associated with training language models using large data sets.
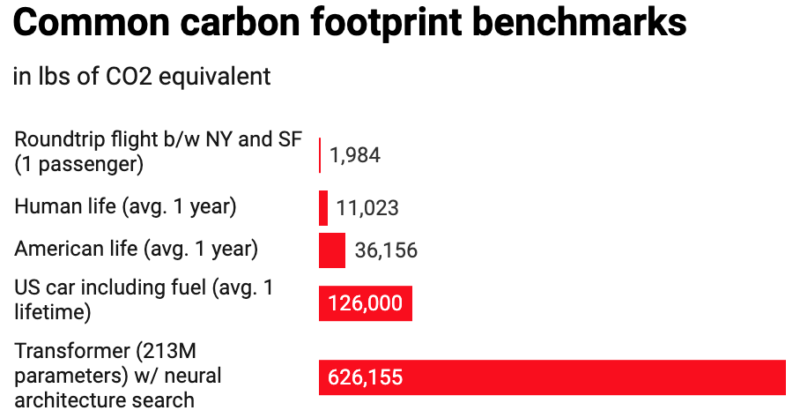
The environmental toll. One of the concerns Gebru and her coauthors researched was the potential environmental costs, according to the MIT Technology Review. Gebru’s paper references a 2019 paper from Emma Strubell et al., which found that training a particular type of neural architecture search method would have produced 626,155 pounds of CO2 equivalent — about the same as 315 roundtrip flights between San Francisco and New York.
Biased inputs may produce biased models. Language models that use training data from the internet may contain racist, sexist, and bigoted language, which could manifest itself in whatever the language model is used for, including search engine algorithms. This aspect of the issue is what we’ll focus on, as it carries potentially serious implications for marketers.
Biased training data can produce biased language models
“Language models trained from existing internet text absolutely produce biased models,” Rangan Majumder, vice president of search and AI at Microsoft, told Search Engine Land, adding “The way many of these pre-trained models are trained is through ‘masking’ which means they’re learning the language nuances needed to fill in the blanks of text; bias can come from many things but the data they’re training over is definitely one of those.”

“You can see the biased data for yourself,” said Britney Muller, former senior SEO scientist at Moz. In the screenshot above, a T-SNE visualization on Google’s Word2Vec corpus isolated to relevant entities most closely related to the term “engineer,” first names typically associated with males, such as Keith, George, Herbert, and Michael appear.
Of course, bias on the internet is not limited to gender: “Bias of economics, popularity bias, language bias (the vast majority of the web is in English, for example, and ‘programmers English’ is called ‘programmers English’ for a reason) . . . to name but a few,” said Dawn Anderson, managing director at Bertey. If these biases are present within training data, and the models that are trained on them are employed in search engine algorithms, those predispositions may show up in search autosuggestions or even in the ranking and retrieval process.
A “smaller piece of the search engine pie” for marketers. “If these large scale models are rolled out everywhere, then it is perceivable they are simply going to reinforce these biases in search, simply by the very logic of the training materials upon which the model has learned,” Anderson said, “So begins a perpetual cycle of reinforcement of bias, potentially.”
This may also play out in the tailored content that search engines like Google provide through features such as the Discover feed. “This will naturally lead to more myopic results/perspectives,” said Muller, “It might be okay for, say, Minnesota Vikings fans who only want to see Minnesota Vikings news, but can get very divisive when it comes to politics, conspiracies, etc. and lead to a deeper social divide.” “For marketers, this potential road leads to an even smaller piece of the search engine pie as content gets served in more striated ways,” she added.
If biased models make it into search algorithms (if they haven’t already), that could taint the objective for many SEOs. “The entire [SEO] industry is built around getting websites to rank in Google for keywords which may deliver revenue to businesses,” said Pete Watson-Wailes, founder of digital consultancy Tough & Competent, “I’d suggest that means we’re optimizing sites for models which actively disenfranchise people, and which directs human behavior.”
However, this is a relatively well-known concern, and companies are making some attempt to reduce the impact of such bias.
Finding the solution won’t be simple
Finding ways to overcome bias in language models is a challenging task that may even impact the efficacy of these models. “Companies developing these technologies are trying to use data visualization technology and other forms of ‘interpretability’ to better understand these large language models and clean out as much bias as they can,” said Muller, “Not only is this incredibly difficult, time consuming, and expensive to mitigate (not to mention, relatively impossible), but you also lose some of the current cutting-edge technology that has been serving these companies so well (GPT-3 at OpenAI and large language models at Google).”
Putting restrictions on language models, like the removal of gender pronouns in Gmail’s Smart Compose feature to avoid misgendering, is one potential remedy; “However, these band-aid solutions don’t work forever and the bias will continue to creep out in new and interesting ways we can’t currently foresee,” she added.
Finding solutions to bias-related problems has been an ongoing issue for internet platforms. Reddit and Facebook both use humans to moderate, and are in a seemingly never-ending fight to protect their users from illicit or biased content. While Google does use human raters to provide feedback on the quality of its search results, algorithms are its primary line of defense to shield its users.
Whether Google has been more successful than Facebook or Reddit in that regard is up for debate, but Google’s dominance over other search engines suggests it is providing better quality search results than its competitors (although other factors, such as network effects, also play a role). It will have to develop scalable ways to ensure the technology that it profits from is equitable if it is to maintain its position as the market leader.
Publicly acknowledging the risks associated with training language models on large data sets, be they environmental, social or something else altogether, helps keep companies accountable for neutralizing them. If Gebru’s departure from Google was about the content of her paper conveying a potentially unflattering image of the company, instead of being about Google’s publishing standards and the ultimatum Gebru gave (as Google SVP of AI Jeff Dean suggested), the incident paints a bleak picture of the company’s commitment to ethical AI when faced with the prospect of potentially unflattering findings from one of their own reaching the public.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.

