Newly-granted Google patent sheds light on how the search engine sees entities
Columnist Dave Davies explains a recent Google patent which hints at how the search engine processes entity information to answer questions. This can provide hints into how SEOs can structure their content to be deemed relevant.

Anyone who knows me knows that I’m a big fan of reading Google patents — or, when I’m feeling lazy, reading Bill Slawski’s analysis of them over on his blog, SEO By The Sea.
I also have a particular interest in those involving entities, as they are (to me at least) the ones that are defining the problems Google is trying to solve. As machine learning evolves, entities represent how search engines increasingly are viewing the world.
Before we dig into this latest Google patent, which was granted on December 22, 2016, let’s first define an entity to make sure we’re all on the same page. According to the patent, the definition is as follows:
[A]n entity is a thing or concept that is singular, unique, well-defined and distinguishable. For example, an entity may be a person, place, item, idea, abstract concept, concrete element, other suitable thing, or any combination thereof.
To keep things simple, you can casually think of an entity as a noun.
Another definition that will be important to understand is unstructured data, which is pretty accurately defined in Wikipedia as such:
Unstructured data … refers to information that either does not have a pre-defined data model or is not organized in a pre-defined manner.
With that under our belt, we’re going to dive right into the patent. The way this article will be structured, I will be including the exact verbiage of important sections of the patent in italics, followed by an explanation of what each section means.
Abstract
Methods, systems, and computer-readable media are provided for collective reconciliation. In some implementations, a query is received, wherein the query is associated at least in part with a type of entity. One or more search results are generated based at least in part on the query. Previously generated data is retrieved associated with at least one search result of the one or more of search results, the data comprising one or more entity references in the at least one search result corresponding to the type of entity. The one or more entity references are ranked, and an entity result is selected from the one or more entity references based at least in part on the ranking. An answer to the query is provided based at least in part on the entity result.
This is one of the abstracts that does little to describe the full scope of what’s contained in the patent. As far as the abstract is concerned, all we’re about to read is that entities get ranked, and that ranking determines the answer to a query.
This was enough to draw me into the patent, and it is indeed accurate — but as you’ll soon see, there’s a lot more described within than a simple “we rank nouns.”
Summary
The following excerpts are contained within the summary section of the patent.
Section 2
[A] system provides answers to natural language search queries by relying on entity references identified based in the unstructured data associated with search results. … [T]he system retrieves additional, preprocessed information associated each respective webpage of at least some of the search results … the additional information includes, for example, names of people that appear in the webpages. In an example, in order to answer a “who” question, the system compiles names appearing in the first ten search results, as identified in the additional information. The system identifies the most commonly appearing name as the answer …
In the excerpt above, we start to see the method behind the system. What Google is discussing here is the idea that to determine the answer to a “who” question, they would use the most common name appearing across the top 10 search results.
Section 4
[T]he query is a natural language query … ranking the one or more entity references comprises ranking based on at least one ranking signal. In some implementations, the one or more ranking signals comprise a frequency of occurrence of each respective entity reference. In some implementations, the one or more ranking signals comprise a topicality score of each respective entity reference. In some implementations, the previously generated data corresponds to unstructured data.
To further the information on how the approach is outlined in the patent, we see the frequency of use of the term within a document, and presumably across multiple documents. In addition, we see that topicality is a relevancy factor and that this is a method applied to unstructured data.
Section 5
[Q]uestions may be provided for queries in an automated and continuously updated fashion. In some implementations, question answering may take advantage of search result ranking techniques. In some implementations, question answers may be identified automatically based on unstructured content of a network such as the Internet.
In this section, we see it reinforced that the answers to questions may be determined based on search results or ranking techniques, but it appears we’re also seeing the patent expand to include the automated determination of question answers based on other techniques and their ability to determine that answer in unstructured data.
The real meat of Patent US 2016/0371385 A1
Sections 14 through 96 give detailed descriptions of the images, flowcharts and the real meat included with this patent. Some of the images will be included below and some will simply be noted, depending on which will get across the information better.
Section 19
[T]he system may retrieve entity references associated with the top ten search results. … the ranking and/or selecting is based on a quality score, a freshness score, a relevance score, on any other suitable information, or any combination thereof.
Here, we see Google clarifying that different types of entities and answers may be based on different sets of information. For example, freshness may be selected as a stronger signal if you were looking up the weather, whereas quality may be stronger if you were looking up a definition, health information and so on.
Section 20
I’ll admit it, I had to read this section a couple of times to fully grasp what they were talking about. This section relates to patent Figure 1, which is as follows:
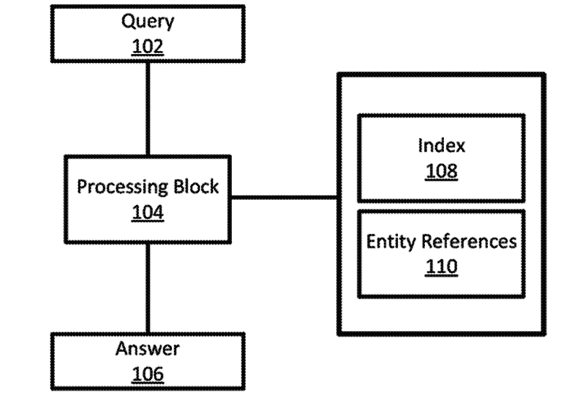
Figure 1: A high-level block diagram of a system for question answering, in accordance with some implementations of the present disclosure.
They write:
[T]he information retrieved from entity references 110 associated with a particular webpage is a list of persons appearing in that webpage. For example, a particular webpage may include a number of names of persons, and entity references 110 may include a list of the names included within the webpage. Entity references 110 may also include other information. In some implementations, entity references 110 includes entity references of different types, for example, people, places, and dates. In some implementations, entity references for multiple entity types are maintained as a single annotated list of entity references, as separated lists, in any other suitable format of information, or any combination thereof. It will be understood that in some implementations, entity references 110 and index 108 may be stored in a single index, in multiple indices, in any other suitable structure, or any combination thereof.
The idea behind what they’re referring to here is repeated elsewhere in the patent. One of the big issues that occurred to me while reading this patent is the enormous processing power it would take. If for any entity search the engine needed to run a query on its own index, process top 10 results, and then determine which terms are used most often in order to establish the most likely answer to a question, the processing of a search result like this would take many times more resources.
In section 20, they discuss the method around this, which is to pre-populate reference lists (110 in the diagram) separate from the index itself.
So, when a query like “who is dave davies” is entered, the data is drawn from the index (to determine the possible pages that have the answers), but a second reference point (110) also exists that would contain the entity data (such as how many times “dave davies” is mentioned in each document), thus saving Google from needing to figure it out on the fly.
Section 21
[O]ne or more ranking metrics are used to rank the entity references, including frequency of occurrence and a topicality score. Frequency of occurrence relates to the number of times an entity reference occurs within a particular document, collection of documents, or other content. Topicality scores include a relationship between the entity reference and the content in which it appears.
Setting aside the repetition of the use of the number of times a term is used as a metric, we also see in this section a reinforcement of topicality. While this could relate to the relevance of a site to a subject and the weighting a reference should be given, I tend to believe it has more to do with aiding in understanding which entity is being referenced.
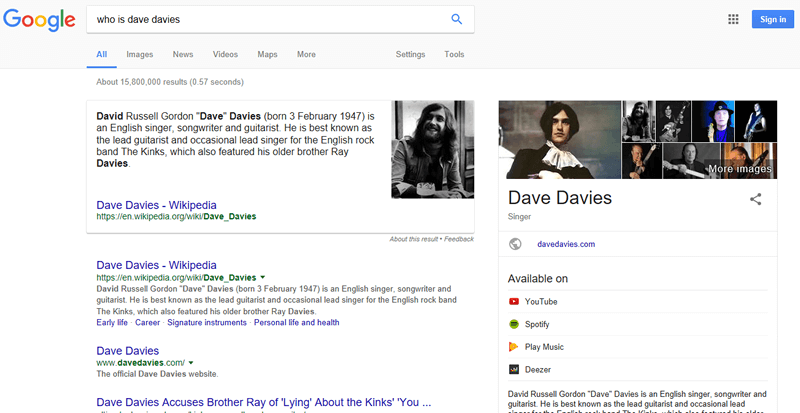
For example, if the entity “dave davies” is seen on a page related to SEO, then it is likely me. On the other hand, if “dave davies” appears on a page related to music, it’s likely “that Kinks guy” (as I like to refer to him).
Seeing more “dave davies” on pages topically related to music would help them in choosing to display:
Section 25
[T]he system orders the search results based on one or more quality scores. In some implementations, quality scores include a relevance to search query, a quality score associated with the search result, a freshness score associated with the time when the data the content was last generated or updated, scores associated with previous selection of a particular search result from a collection of search results, any other suitable quality score, or any combination thereof. In an example, a quality score associated with a search result may include the number of links to and from a corresponding webpage.
In section 25, we’re seeing more of a clarification of quality score as a metric. This section, of course, had to be included not just for its reference to incoming links as a quality indicator, but also the inclusion of outbound links as a possible signal.
Section 28
[T]he system generates a collection of entity references appearing in a webpage by comparing the structured or unstructured text to a list of known entity references, for example a list of names. In some implementations, entity references not previously known are identified based on a frequency of occurrence or other clustering techniques. In some implementations, entity references are person entity references, for example, names of people appearing in the text of a webpage. In an example, the system maintains a list of all of the names of people that appear in a particular webpage, and that list is retrieved when the webpage appears in the top results of search results box 206.
In section 28, we see the understanding come out that not all entities are known, and methods need to be developed to understand new ones. This would happen if a person were first mentioned on the internet, a new building were developed and so on. Google would then use their understanding of how other entities are referenced (e.g., location on page) and begin adding the new entity to the entity reference list (see “110” in Figure 1 above).
Section 36
In some implementations, the system processes webpages and other content to identify entity references. In some implementations, the system performs this processing offline, such that it is retrieved at the time of search. In some implementations, the system processes the information in real-time at the time of search.
In section 36, we see systems being discussed that accommodate for faster results via offline processing, as we saw earlier in section 20. We also see reference to systems that operate in real time. Obviously, there are query types that would require this (like weather), and one can assume that Google would have lists of trusted sources for this type of information, enabling them to still process the information quickly and with minimal resources.
Section 37
[L]ist entries include an entity reference, a unique identifier associated with the entity reference, a frequency of occurrence of the entity reference, the location on the page where the entity reference occurs, metadata associated with the content such as freshness and ordering, any other suitable data, or any combination thereof. In some implementations, previously generated data may include the type of entity reference, for example, a person, a location, a date, any other suitable type, or any combination thereof. In some implementations, previously generated data includes information identifying entities as a particular type, such as a person entity reference, a place entity reference, or a time entity reference. In some implementations, multiple sets of data may be generated for a website or other content, where each set is associated with one or more types. In an example, a website may be associated with a list of the person entity references occurring therein and a list of the location entity references occurring therein.
For those curious about how different entities would be isolated, we get our answer here, where they discuss “a unique identifier” for an entity. That is, rather than thinking of Dave Davies of The Kinks and Dave Davies, the author this this article, as two versions of “Dave Davies,” Google would instead think of us as identifiers with an identical attribute.
Where you or I would think of a person by their name, Google would not; they would think of them by a unique, likely alpha-numeric, sequence. I’ll be illustrating this further below, but in its simplest form, it could look something like:
Unique ID (00000001A) – > Has Name (Dave Davies) -> Has Job (Musician)
and
Unique ID (00000001B) – > Has Name (Dave Davies) -> Has Job (SEO)
Past that, this section mainly reinforces known SEO and relevancy reinforcement factors such as frequency of entity usage, the location on the page of content, links, etc.
Section 38
[O]ther names or entity references occurring in the content may be used to disambiguate a reference. In an example, the name [George Washington] occurring in the same text as [Martha Washington] may be identified as relating to a unique entity reference in a list of the U.S. President, whereas [George Washington] occurring in the same content as [University] and [Washington D.C.] is identified as relating to [George Washington University].
In this section, we see further how entities are understood via context. When there are two or more entities with a similar name attribute, the patent outlines the use of additional data from the page to aid in determining which specific entity is being referenced.
To use my example, a reference to “Dave Davies” occurring on a page with “The Kinks” would associate that Dave Davies with Unique ID 00000001A from above and not 00000001B.
Section 41
In another example, the system determines a frequency by normalizing a number of appearances by the length of the document or any other suitable metric.
To be honest, the only reason I’m including a part of Section 41 in this write-up is that it is likely the last time I will ever be able to reference keyword density as a metric without the context “in the early 2000s.”
Interestingly, that’s exactly what they’re referring to here, and in this context it does make sense. If one is using the frequency of an entity reference in the top 10 results as an indicator of an answer to a question, one should take into account that a 10,000-word page should be expected to have a different impact on that number than a page with 700 words.
Nonetheless, you will likely never read or hear a reference to keyword density from Unique ID 00000001B again.
Section 42
[T]he system uses a topicality score as a ranking signal. In some implementations, topicality scores include freshness, the age of the document, the number of links to and/or from the document, the number of selections of that document in previous search results, a strength of the relationship between the document and the query, any other suitable score, or any combination thereof. In some implementations, a topicality score depends on a relationship between the entity reference and the content within which the entity reference appears. For example, the entity reference [George Washington] may have a higher topicality score on a history webpage than on a current news webpage. In another example, the entity reference [Barack Obama] may have a higher topicality score on a politics website than on a law school website.
In this section, we see Google clarifying what topicality means and what its impact will be on the results. This would have less to do with the selection of a specific entity as an answer (for example, the selection of which Dave Davies is being referenced) and more to do with what data is used to craft the answer.
For example, that he was born the last of eight children is not topically relevant enough to be included in the answer to “who is dave davies” as illustrated above, and instead information such as his birth date and band are. All this information is accurate, but due to topicality signals such as frequency across documents, the more “important” information is selected.
Section 47
Section 47 relies on arguably the most important figure if we want to really understand the logic in how Google answers questions and organizes data. So before we get into what is written, let’s look at the illustration. It’s important to note that the red text is not part of the initial patent and has been added by me to provide a context.
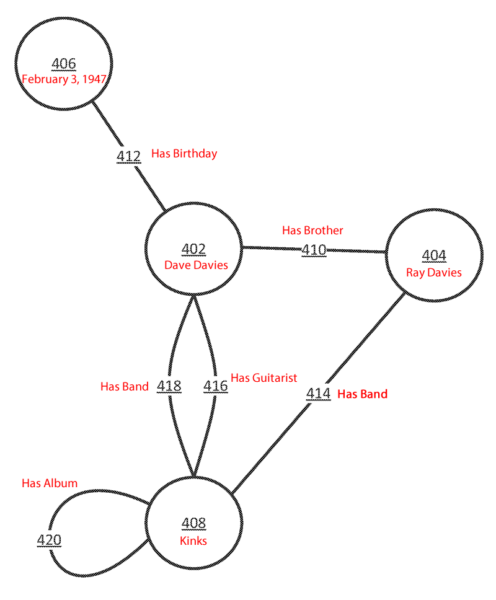
The nodes each contain a piece or pieces of data and the edges represent relationships between the data contained in the nodes that the edges connect. In some implementations, the graph includes one or more pairs of nodes connected by an edge. The edge, and thus the graph, may be directed, i.e. unidirectional, undirected, i.e. bidirectional, or both, i.e. one or more edges may be undirected and one or more edges may be directional in the same graph.
The nodes referenced are the round elements and contain data; lines are edges and contain the relationship. For example, Dave Davies (402) has the brother Ray Davies (404) and both have the band The Kinks (408).
This graph is very simplified for easier understanding. In reality, each of these nodes would represent Unique IDs, and those IDs would have elements “Has Name” — but for our purposes here, the above illustration works well.
Section 52
A domain refers to a collection of related entity types. For example, the domain [Film] may include, for example, the entity types [Actor], [Director], [Filming Location], [Movie], any other suitable entity type, or any combination thereof. In some implementations, entities are associated with types in more than one domain. For example, the entity node [Benjamin Franklin] may be connected with the entity type node [Politician] in the domain [Government] as well as the entity type node [Inventor] in the domain [Business].
In this section, we see further groupings of information into domains. Reasonably, we can assume that most or all domains would also be nodes in other application. “Keanu Reeves,” for example, would be a node linked to another node “film” by the edge “acts in.” Both of these nodes would be contained in the domain “film.”
Section 56
[T]he knowledge graph may include information for differentiation and disambiguation of terms and/or entities. As used herein, differentiation refers to the many-to-one situation where multiple names are associated with a single entity. As used herein, disambiguation refers to the one-to-many situation where the same name is associated with multiple entities. In some implementations, nodes may be assigned a unique identification reference. In some implementations, the unique identification reference may be an alphanumeric string, a name, a number, a binary code, any other suitable identifier, or any combination thereof. The unique identification reference may allow the system to assign unique references to nodes with the same or similar textual identifiers. In some implementations, the unique identifiers and other techniques are used in differentiation, disambiguation, or both.
In section 56, we get clarification on differentiation (solving the scenario where there are many names for one entity — for example: movie, film, flick) and disambiguation (solving the scenario where there is one name shared by multiple entities – for example: Dave Davies).
We speak again in the section of the unique identifier and its use. In short, you are not you, and no entity is itself in the way we communicate it. Each entity is a unique ID, and that unique ID is assigned to nodes that include more common references, such as names and characteristics.
Section 58
[T]here may be an entity node related to the city [Philadelphia], an entity node related to the movie [Philadelphia], and an entity node related to the cream cheese brand [Philadelphia]. Each of these nodes may have a unique identification reference, stored for example as a number, for disambiguation within the knowledge graph. In some implementations, disambiguation in the knowledge graph is provided by the connections and relationships between multiple nodes. For example, the city [New York] may be disambiguated from the state [New York] because the city is connected to an entity type [City] and the state is connected to an entity type [State]. It will be understood that more complex relationships may also define and disambiguate nodes. For example, a node may be defined by associated types, by other entities connected to it by particular properties, by its name, by any other suitable information, or any combination thereof. These connections may be useful in disambiguating, for example, the node [Georgia] that is connected to the node [United States] may be understood represent the U.S. State, while the node [Georgia] connected to the nodes [Asia] and [Eastern Europe] may be understood to represent the country in eastern Europe.
While Section 58 is focused on discussing how specific entities can be identified by their nodes and connection, what’s really important here is that this is the method by which they will determine which answer is more likely to be correct. This will be based on a combination of nodes, as discussed in this section, and domains, as discussed previously. If I ask Google the question:
“Who was in Philadelphia?”
Google understands that the most likely reference based on the type of question (that I’m searching for people) is the movie, “Philadelphia.” It could be answered with a list of all the known people to have ever visited the city, but it’s unlikely that’s the information I want. Thus, Google provides an answer based on the movie. If I change my question to:
“How many people are in Philadelphia?”
The answer Google gives is 1.553 million. It could have answered with the total number in the cast of the movie, but it has selected what it feels is the most likely answer being sought based on the entities available and the framing of the data being sought.
Section 61
[N]odes and edges define the relationship between an entity type node and its properties, thus defining a schema.
Here we see Google essentially turning the unstructured data into a structure by creating its own schema of the edges and nodes where it was previously undefined. This will allow Google to generate its own schema for Person (for example) and constantly adjust, add and remove the schema associated with it.
Section 68
[S]eparate knowledge graphs are maintained for different respective domains, for different respective entity types, or according to any other suitable delimiting characteristic.
In this section, we see Google creating separate types of knowledge graphs for different types of data. That is, framing answers differently based on the type of information being requested. We’ll get into why this is important below.
So what?
Now that we’ve made it to the end of the critical bits of information, you may be left asking, “So what?” Good question.
While understanding how Google organizes data is, unto itself, a good thing, there are specific actionable items we can take away from this that can dramatically improve our rankings and relevancy. The best part is, they’re not hard and don’t actually take much effort — just an understanding of what you’re looking for.
- Include the data that makes you relevant. OK, now I’ll take off my “Captain Obvious” hat and point out that if we simply look to the site an answer is drawn from and what data it has on the entity, we will gain a greater understanding of what Google finds relevant to that specific topic. While Google wants to give an answer, they also want their users to have access to more complete data if desired. Thus, they will more likely rank a site that has not just the answer they want but the likely supporting information searchers may also be looking for.
- Create structured unstructured data. While it’s obviously ideal to use markup to structure your data for the engines, it’s also important to frame your content such that the information can be connected without it. Google is looking through content to determine its own connections, so using a statement such as “Dave Davies was a guitarist for The Kinks” will aid Google in understanding specifically which Dave Davies you are referring to, what his role was and who that role was for. A statement such as “Dave Davies of The Kinks” will likely be picked up as the correct entity; however, the data will not be viewed as fully complete. That’s fine for Google, as they can get this information in many other places. Still, if we want to rank well, we should strive to be thorough.
- And more structure. It’s been said before, and this patent reinforces, that we need to look to the way knowledge is passed on and structure our own data accordingly. If you look to the answer given to the question, “who is dave davies” above, you’ll see that the answer is given in paragraph format. If we consider the patent, we’ll consider that this is how Google is connecting the dots between entities for these types of queries. Thus, if we have a page on Dave Davies, we want to structure the information in paragraph format rather than in lists. This would be different from “how do I …” type queries that often resort to lists in their answer formats. This is what was discussed in Section 68, and it will impact not just our ability to rank as the answer to questions, but also how Google interprets our website and the effectiveness of our content structure.
Conclusion
Entities are, in my ever-so-humble opinion, one of the most important aspects of Google’s algorithm to understand, and this patent adds to that understanding. Understanding entities is understanding how Google views the connections between everything it encounters. This helps dictate how you should structure your content (and what that content should include) to be deemed not just relevant, but the most relevant.
And what more could you want than that?
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author