Here’s what happened when I followed Googlebot for 3 months
This experiment uncovered no direct way to bypass the First Link Counts Rule with modified links but it was possible to build a structure using Javascript links.

On internet forums and content-related Facebook groups, discussions often break out about how Googlebot works – which we shall tenderly call GB here – and what it can and cannot see, what kind of links it visits and how it influences SEO.
In this article, I will present the results of my three-month-long experiment.
Almost daily for the past three months, GB has been visiting me like a friend dropping by for a beer.
Sometimes it was alone:
[02/09/2018 18:29:49]: 66.249.76.136 /page1.html Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
[02/09/2018 19:45:23]: 66.249.76.136 /page5.html Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
[02/09/2018 21:01:10]: 66.249.76.140 /page3.html Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
[02/09/2018 21:01:11]: 66.249.64.72 /page2.html Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
[02/09/2018 23:32:45]: 66.249.64.72 /page6.html Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
Sometimes it brought its buddies along:
[16/09/2018 19:16:56]: 64.233.172.231 /page1.html Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
[16/09/2018 19:26:08]: 66.249.69.235 /image.jpg Googlebot-Image/1.0
[27/08/2018 23:37:54]: 66.249.76.156 /page2.html Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)
And we had lots of fun playing different games:
Catch: I observed how GB loves to run redirections 301 and crawl images, and run from canonicals.
Hide-and-seek: Googlebot was hiding in the hidden content (which, as its parents claim, it does not tolerate and avoids)
Survival: I prepared traps and waited for it to spring them.
Obstacles: I placed obstacles with various levels of difficulty to see how my little friend would deal with them.
As you can probably tell, I was not disappointed. We had tons of fun and we became good friends. I believe our friendship has a bright future.
But let’s get to the point!
I built a website with merits-related content about an interstellar travel agency offering flights to yet-undiscovered planets in our galaxy and beyond.
The content seemed to have a lot of merits when in fact it was a load of nonsense.
The structure of the experimental website looked like this:

I provided unique content and made sure that every anchor/title/alt, as well as other coefficients, were globally unique (fake words). To make things easier for the reader, in the description I will not use names like anchor cutroicano matestito, but instead refer them as anchor1, etc.
I suggest that you keep the above map open in a separate window as you read this article.
Part 1: First link counts
One of the things that I wanted to test in this SEO experiment was the First Link Counts Rule – whether it can be omitted and how it influences optimization.
The First Link Counts Rule says that on a page, Google Bot sees only the first link to a subpage. If you have two links to the same subpage on one page, the second one will be ignored, according to this rule. Google Bot will ignore the anchor in the second and in every consecutive link while calculating the page’s rank.
It is a problem widely overseen by many specialists, but one that is present especially in online shops, where navigation menus significantly distort the website’s structure.
In most stores, we have a static (visible in the page’s source) drop-down menu, which gives, for example, four links to main categories and 25 hidden links to subcategories. During the mapping of a page’s structure, GB sees all the links (on each page with a menu) which results in all the pages being of equal importance during the mapping and their power (juice) is distributed evenly, which looks roughly like this:
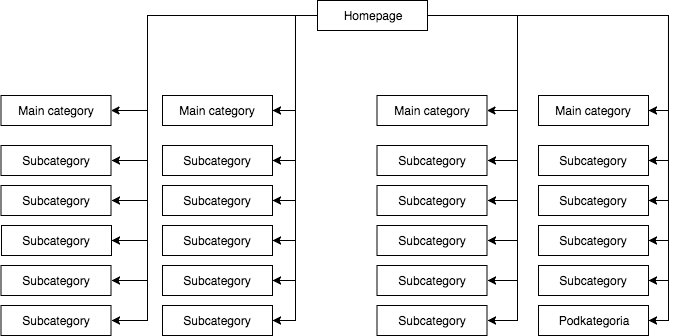
The most common but in my opinion, the wrong page structure.
The above example cannot be called a proper structure because all the categories are linked from all the sites where there is a menu. Therefore, both the home page and all the categories and subcategories have an equal number of incoming links, and the power of the entire web service flows through them with equal force. Hence, the power of the home page (which is usually the source of most of the power due to the number of incoming links) is being divided into 24 categories and subcategories, so each one of them receives only 4 percent of the power of the homepage.
How the structure should look:

If you need to fast test the structure of your page and crawl it like Google does, Screaming Frog is a helpful tool.
In this example, the power of the homepage is divided into four and each of the categories receives 25 percent of the homepage’s power and distributes part of it to the subcategories. This solution also provides a better chance of internal linking. For instance, when you write an article on the shop’s blog and want to link to one of the subcategories, GB will notice the link while crawling the website. In the first case, it will not do it because of the First Link Counts Rule. If the link to a subcategory was in the website’s menu, then the one in the article will be ignored.
I started this SEO experiment with the following actions:
- First, on the page1.html, I included a link to a subpage page2.html as a classic dofollow link with an anchor: anchor1.
- Next, in the text on the same page, I included slightly modified references to verify whether GB would be eager to crawl them.
To this end, I tested the following solutions:
- To the web service’s homepage, I assigned one external dofollow link for a phrase with a URL anchor (so any external linking of the homepage and the subpages for given phrases was out of question) – it sped up the indexing of the service.
- I waited for page2.html to start ranking for a phrase from the first dofollow link (anchor1) coming from page1.html. This fake phrase, or any other that I tested could not be found on the target page. I assumed that if other links would work, then page2.html would also rank in the search results for other phrases from other links. It took around 45 days. And then I was able to make the first important conclusion.
Even a website, where a keyword is neither in the content, nor in the meta title, but is linked with a researched anchor, can easily rank in the search results higher than a website which contains this word but is not linked to a keyword.
Moreover, the homepage (page1.html), which contained the researched phrase, was the strongest page in the web service (linked from 78 percent of the subpages) and still, it ranked lower on the researched phrase than the subpage (page2.html) linked to the researched phrase.
Below, I present four types of links I have tested, all of which come after the first dofollow link leading to page2.html.
Link to a website with an anchor
< a href=”page2.html#testhash” >anchor2< /a >
The first of the additional links coming in the code behind the dofollow link was a link with an anchor (a hashtag). I wanted to see whether GB would go through the link and also index page2.html under the phrase anchor2, despite the fact that the link leads to that page (page2.html) but the URL being changed to page2.html#testhash uses anchor2.
Unfortunately, GB never wanted to remember that connection and it did not direct the power to the subpage page2.html for that phrase. As a result, in the search results for the phrase anchor2 on the day of writing this article, there is only the subpage page1.html, where the word can be found in the link’s anchor. While Googling the phrase testhash, our domain does not rank either.
Link to a website with a parameter
page2.html?parameter=1
Initially, GB was interested in this funny part of the URL just after the query mark and the anchor inside the anchor3 link.
Intrigued, GB was trying to figure out what I meant. It thought, “Is it a riddle?” To avoid indexing the duplicate content under the other URLs, the canonical page2.html was pointing at itself. The logs altogether registered 8 crawls on this address, but the conclusions were rather sad:
- After 2 weeks, the frequency of GB’s visits decreased significantly until it eventually left and never crawled that link again.
- page2.html wasn’t indexed under the phrase anchor3, nor was the parameter with the URL parameter1. According to Search Console, this link does not exist (it is not counted among incoming links), but at the same time, the phrase anchor3 is listed as an anchored phrase.
Link to a website from a redirection
I wanted to force GB to crawl my website more, which resulted in GB, every couple of days, entering the dofollow link with an anchor anchor4 on page1.html leading to page3.html, which redirects with a 301 code to page2.html. Unfortunately, as in the case of the page with a parameter, after 45 days page2.html was not yet ranking in the search results for the anchor4 phrase which appeared in the redirected link on page1.html.
However, in Google Search Console, in the Anchor Texts section, anchor4 is visible and indexed. This could indicate that, after a while, the redirection will begin to function as expected, so that page2.html will rank in the search results for anchor4 despite being the second link to the same target page within the same website.
Link to a page using canonical tag
On page1.html, I placed a reference to page5.html (follow link) with an anchor anchor5. At the same time, on page5.html there was unique content, and in its head, there was a canonical tag to page2.html.
< link rel=“canonical” href=”https://example.com/page2.html” />
This test gave the following results:
- The link for the anchor5 phrase directing to page5.html redirecting canonically to page2.html was not transferred to the target page (just like in the other cases).
- page5.html was indexed despite the canonical tag.
- page5.html did not rank in the search results for anchor5.
- page5.html ranked on the phrases used in the page’s text, which indicated that GB totally ignored the canonical tags.
I would venture to claim that using rel=canonical to prevent the indexing of some content (e.g. while filtering) simply could not work.
Part 2: Crawl budget
While designing an SEO strategy, I wanted to make GB dance to my tune and not the other way around. To this aim, I verified the SEO processes on the level of the server logs (access logs and error logs) which provided me with a huge advantage. Thanks to that, I knew GB’s every movement and how it reacted to the changes I introduced (website restructuring, turning the internal linking system upside-down, the way of displaying information) within the SEO campaign.
One of my tasks during the SEO campaign was to rebuild a website in a way that would make GB visit only those URLs that it would be able to index and that we wanted it to index. In a nutshell: there should only be the pages that are important to us from the point of view of SEO in Google’s index. On the other hand, GB should only crawl the websites that we want to be indexed by Google, which is not obvious to everyone, for example, when an online shop implements filtering by colors, size and prices, and it is done by manipulating the URL parameters, eg.:
example.com/women/shoes/?color=red&size=40&price=200-250
It may turn out that a solution which allows GB to crawl dynamic URLs makes it devote time to scour (and possibly index) them instead of crawling the page.
example.com/women/shoes/
Such dynamically created URLs are not only useless but potentially harmful to SEO because they can be mistaken for thin content, which will result in the drop of website rankings.
Within this experiment I also wanted to check some methods of structuring without using rel=”nofollow”, blocking GB in the robots.txt file or placing part of the HTML code in frames that are invisible for the bot (blocked iframe).
I tested three kinds of JavaScript links.
JavaScript link with an onclick event
A simple link constructed on JavaScript
< a href=”javascript:void(0)” onclick=”window.location.href =’page4.html’” >anchor6< /a >
GB easily moved on to the subpage page4.html and indexed the entire page. The subpage does not rank in the search results for the anchor6 phrase, and this phrase cannot be found in the Anchor Texts section in Google Search Console. The conclusion is that the link did not transfer the juice.
To summarize:
- A classic JavaScript link allows Google to crawl the website and index the pages it comes upon.
- It does not transfer juice – it is neutral.
Javascript link with an internal function
I decided to raise the game but, to my surprise, GB overcame the obstacle in less than 2 hours after the publication of the link.
< a href=”javascript:void(0)” class=”js-link” data-url=”page9.html” >anchor7< /a >
To operate this link, I used an external function, which was aimed at reading the URL from the data and the redirection – only the redirection of a user, as I hoped – to the target page9.html. As in the earlier case, page9.html had been fully indexed.
What is interesting is that despite the lack of other incoming links, page9.html was the third most frequently visited page by GB in the entire web service, right after page1.html and page2.html.
I had used this method before for structuring web services. However, as we can see, it does not work anymore. In SEO nothing lives forever, apart from the Yellow Pages.
JavaScript link with coding
Still, I would not give up and I decided that there must be a way to effectively shut the door in GB’s face. So, I constructed a simple function, coding the data with a base64 algorithm, and the reference looked like this:
< a href=”javascript:void(0)” class=”js-link” data-url=”cGFnZTEwLmh0bWw=” >anchor8< /a >
As a result, GB was unable to produce a JavaScript code that would both decode the content of a data-URL attribute and redirect. And there it was! We have a way to structure a web service without using rel=nonfollows to prevent bots from crawling wherever they like! This way, we do not waste our crawl-budget, which is especially important in the case of big web services, and GB finally dances to our tune. Whether the function was introduced on the same page in the head section or an external JS file, there is no evidence of a bot either in the server logs or in Search Console.
Part 3: Hidden content
In the final test, I wanted to check whether the content in, for example, hidden tabs would be considered and indexed by GB or whether Google rendered such a page and ignored the hidden text, as some specialists have been claiming.
I wanted to either confirm or dismiss this claim. To do that, I placed a wall of text with over 2000 signs on page12.html and hid a block of text with about 20 percent of the text (400 signs) in Cascading Style Sheets and I added the show more button. Within the hidden text there was a link to page13.html with an anchor anchor9.
There is no doubt that a bot can render a page. We can observe it in both Google Search Console and Google Insight Speed. Nevertheless, my tests revealed that a block of text displayed after clicking the show more button was fully indexed. The phrases hidden in the text ranked in the search results and GB was following the links hidden in the text. Moreover, the anchors of the links from a hidden block of text were visible in Google Search Console in the Anchor Text section and page13.html also began to rank in the search results for the keyword anchor9.
This is crucial for online shops, where content is often placed in hidden tabs. Now we are sure that GB sees the content in hidden tabs, indexes them, and transfers the juice from the links that are hidden there.
The most important conclusion that I am drawing from this experiment is that I have not found a direct way to bypass the First Link Counts Rule by using modified links (links with parameter, 301 redirects, canonicals, anchor links). At the same time, it is possible to build a website’s structure using Javascript links, thanks to which we are free from the restrictions of the First Link Counts Rule. Moreover, Google Bot can see and index content hidden in bookmarks and it follows the links hidden in them.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author