How to earn your place in Google’s index in 2020
The four distinct types of indexing problems and how to identify them.
The game has changed. On average, 15-20% of your URLs are not indexed by Google.
This is on top of partial indexing issues for pages that are actually indexed. Partial indexing is when your URL is indexed by Google but some of the content of the page isn’t indexed for numerous reasons.
The larger your website is, the more likely you are to struggle with indexing. Just to give you some examples:
- Walmart: only 61% indexed by Google,
- Yoox.com: only 19% of its content is indexed.
E-commerce stores, publishers, even blogs. Nobody is immune to this issue.
Walmart, Verizon, Medium.com — the type of the website doesn’t matter.
Medium.com is one of my favorite examples with ~20% of its URLs not indexed by Google, but the list of unindexed websites is very long. Our database is filled with thousands of big brands, brands you know, websites you visit every day that are struggling with getting their unique, indexable URLs indexed by Google.
This article will shed some light on this problem and help you not only understand it but also diagnose, monitor, and fix it on your website.

Before we get started discussing solutions to this challenge, let me shed some light on the history of indexing, partial indexing, and rendering SEO.
A bit of history
Indexing issues are not just about JavaScript anymore.
The first time I saw a partially indexed page, I was amazed by this new phenomenon, but it was easy to explain this problem in 2017. Google would index the HTML content and skip parts of the page that relied on JavaScript.
We started tracking indexing issues of our clients and other large, popular websites hoping to find out what was causing them. We quickly realized that indexing problems come in all possible shapes and sizes.
Partial indexing is often connected to a website using JavaScript, but this is slowly changing. There are more and more “JavaScript-free” websites that struggle with partial indexing.
To understand this problem, we needed more data. We needed to understand the scale of the problem. Last year, we started building our own toolset to track Google’s indexing problems, and this article will summarize the last few years of our research into crawling, rendering, and indexing trends, data from our toolset, and last but not least, Google’s feedback and reaction to us announcing our findings in my “Rendering SEO manifesto” during the SEJ eSummit in June.
Let’s start with the four distinct types of indexing problems you may encounter.
URL indexing
This problem is the most severe and also the easiest to understand. If your whole URL is not indexed by Google, then it is an overarching problem.
Why do I call it URL indexing? In the past, we used the term “HTML indexing” instead, but we realized that it is not the best idea anymore. You can have partial indexing issues with HTML websites now which makes this term confusing and obsolete. From now on, I’ll stick to URL indexing to make it a bit more precise.
Example of indexing problems on the URL level
Let’s have a look at one of the URLs from our database. We’ll go through a sample diagnostic path to see if the URL is properly indexed by Google.
Before going through all these steps, make sure that the URL in question is not canonicalized, no-indexed, blocked in robots etc.
At the time of writing this article, this URL (like other URLs mentioned in this post) hasn’t been indexed for several months, but I am pretty sure it will be indexed quickly after publication of this article due to external linking and traffic sent to it. Feel free to DM me for a list of URLs that are not indexed by Google if you want to have a look.

Let’s start with the good old site: command check in Google.
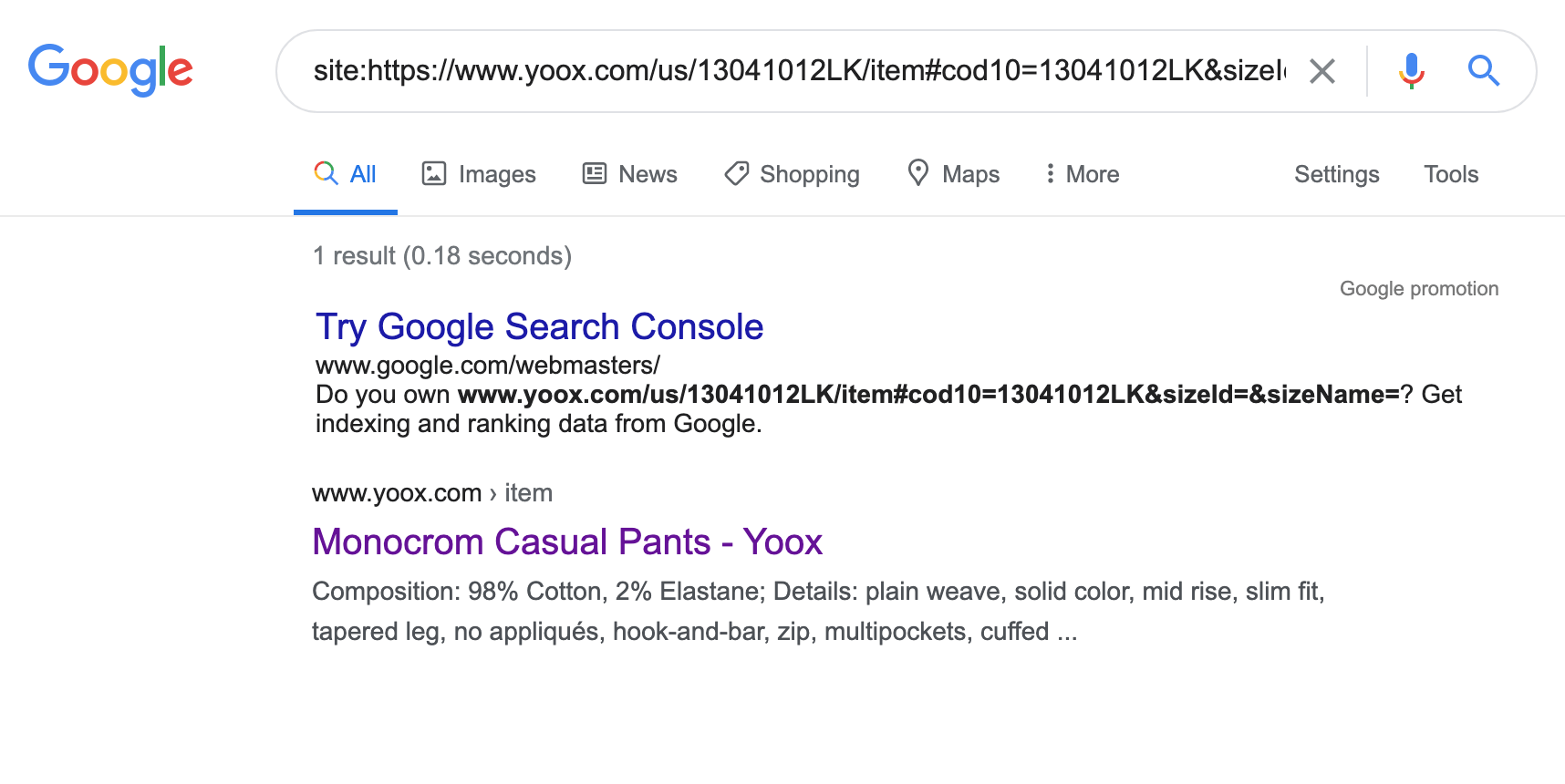
We can see that Google didn’t return any results for this URL, but our work is not done.
Site: command often returns false negatives. There is a way around it though (for now).
We usually go with two extra searches just to be sure that our diagnosis is right.
1. “Brand name” + site command
Simply add the brand’s name before the site: command

2. “Keyword” + site command
Add a word that is often used within the content before the site: command to double-check if your results are precise.
In this example, I went with the word “shoes” as this is a product listing for shoes.


Now we can be sure that this URL is not indexed by Google.
Below are some additional examples of pages that haven’t been indexed on a URL level.
- https://www.yoox.com/us/36955859MP/item
- https://www.yoox.com/us/12227254FL/item
- https://www.target.com/p/harry-potter-film-vault-volume-5-by-jody-revenson-hardcover/-/A-77392918
- https://medium.com/@dhbogucki/of-course-our-relationship-to-technology-is-changeable-526c8f84e4d3
- https://www.overstock.com/Lighting-Ceiling-Fans/Siesta-Key-Resin-Table-Lamp/9075408/product.html
- https://www.bostonglobe.com/news/world/2019/11/18/samoa-closes-schools-measles-epidemic-kills-least/GmMvr2OMsIiLMBGaZmrKKP/story.html
- https://www.yoox.com/us/14014778UC/item
- https://www.qvc.com/%22As-Is%22-Judith-Ripka-14K-Gold-Multi-Gemstone-%26-Diamond-Charm-Necklace.product.J361517.html
Mobile-first related partial indexing
Mobile-first indexing (and crawling) came with some new, interesting challenges. Many websites introduced two separate versions of content served to users depending on the device they’re using.
I want to show you a very simple example of how this can cause indexing problems on your website.
Let’s dive into this example from Yoox.
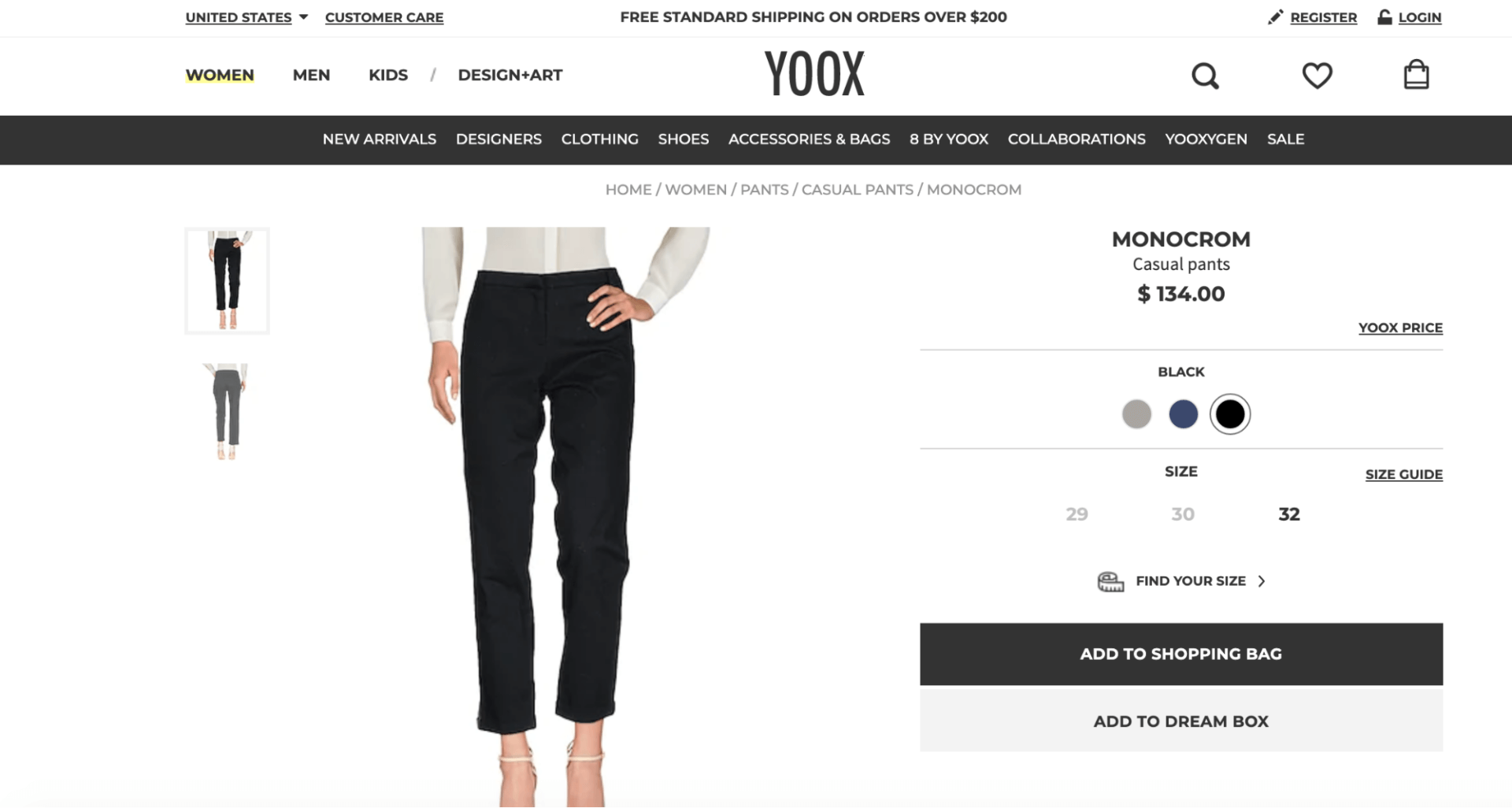
After a quick check, we can see that this URL is indexed by Google.

Is it fully indexed though? Let the fun begin.
We’ve been tracking Yoox.com for almost a year now. I am pretty sure that it is crawled by the mobile Googlebot agent which leads it to have mobile-first partial indexing problems.
How to find Mobile version vs. desktop version differences?
First, we need to see how the mobile and desktop versions of the URL differ. There are several ways to do that. One is simply opening the mobile version and desktop side by side to look for differences.
Chrome – side by side visual comparison
This is how I usually start my comparisons when analyzing potential mobile-first partial indexing issues related.
If you were good at finding differences between two pictures as a kid, this will probably do the trick for you in most cases.
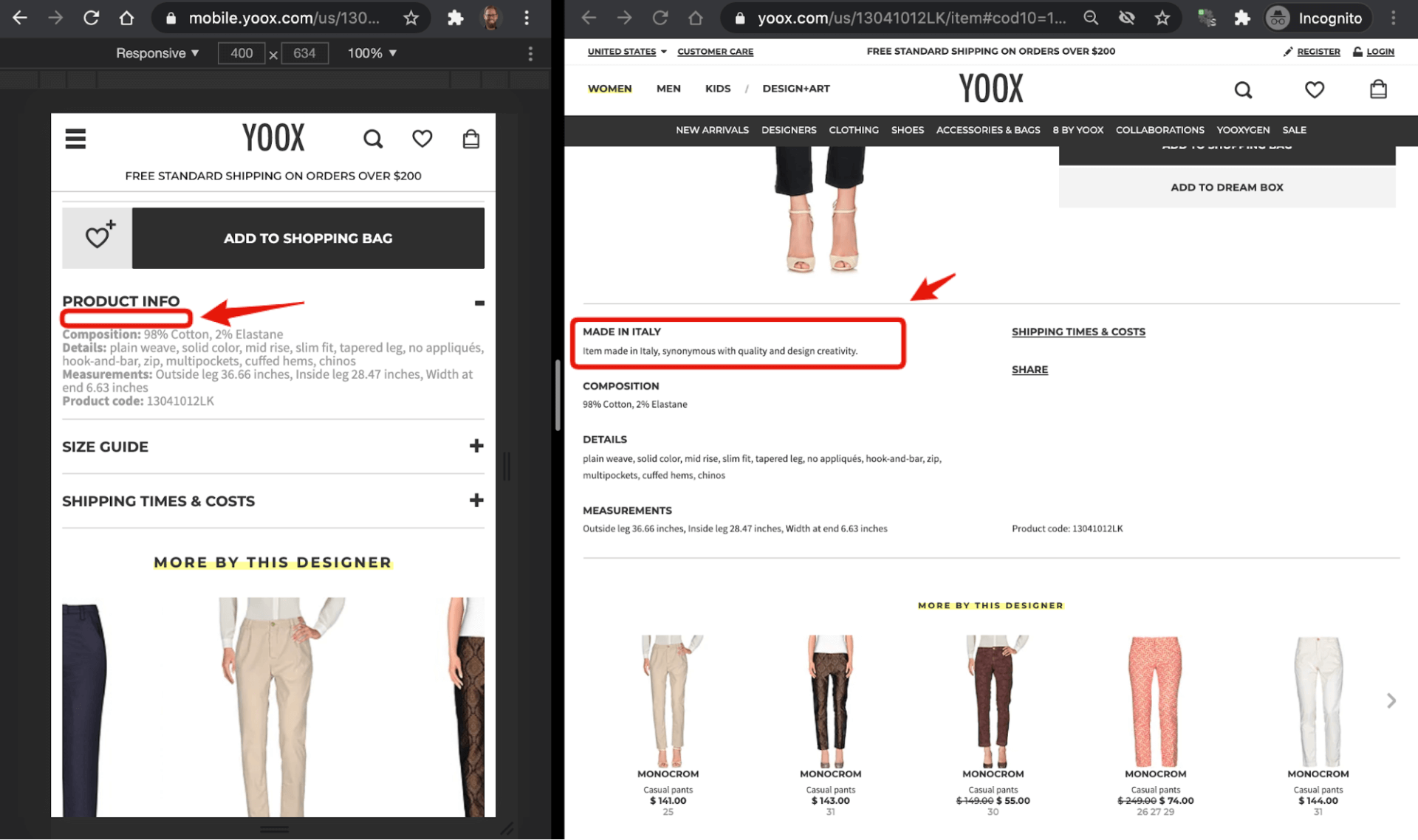
As you can see on the screenshot above, there is a part of the product description on the desktop version that is not presented on the mobile version of the page.
Some projects are a bit more complex than others, and sometimes you simply want to double-check if you found all of the problems.
In some (rare) cases, you may want to dig a little deeper and open up Diffchecker.
Diffchecker
Running source code through Diffchecker is a little bit geekier and requires a little bit more understanding of HTML code, but after spending some time with it, you’ll find that it is not that complicated after all.
I prefer to keep the mobile version on the left-hand side and desktop version of the source code on the right-hand side. This way all the content “additions” are marked green, but feel free to do it the way that works best for you.
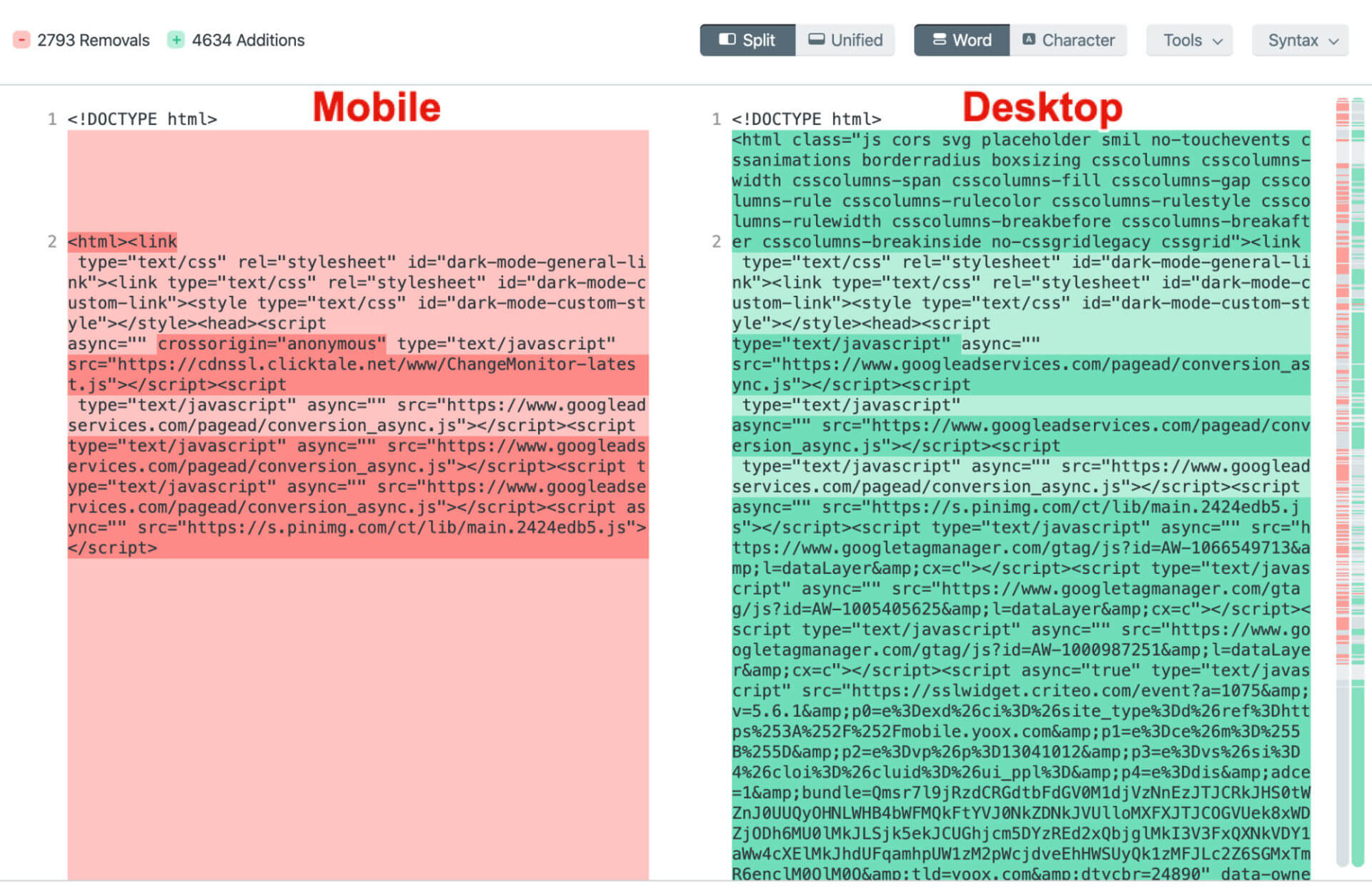
After a few minutes of browsing and trying to make sense of this code, you can find content that is visible in the desktop version, but not visible in the mobile version of this page.
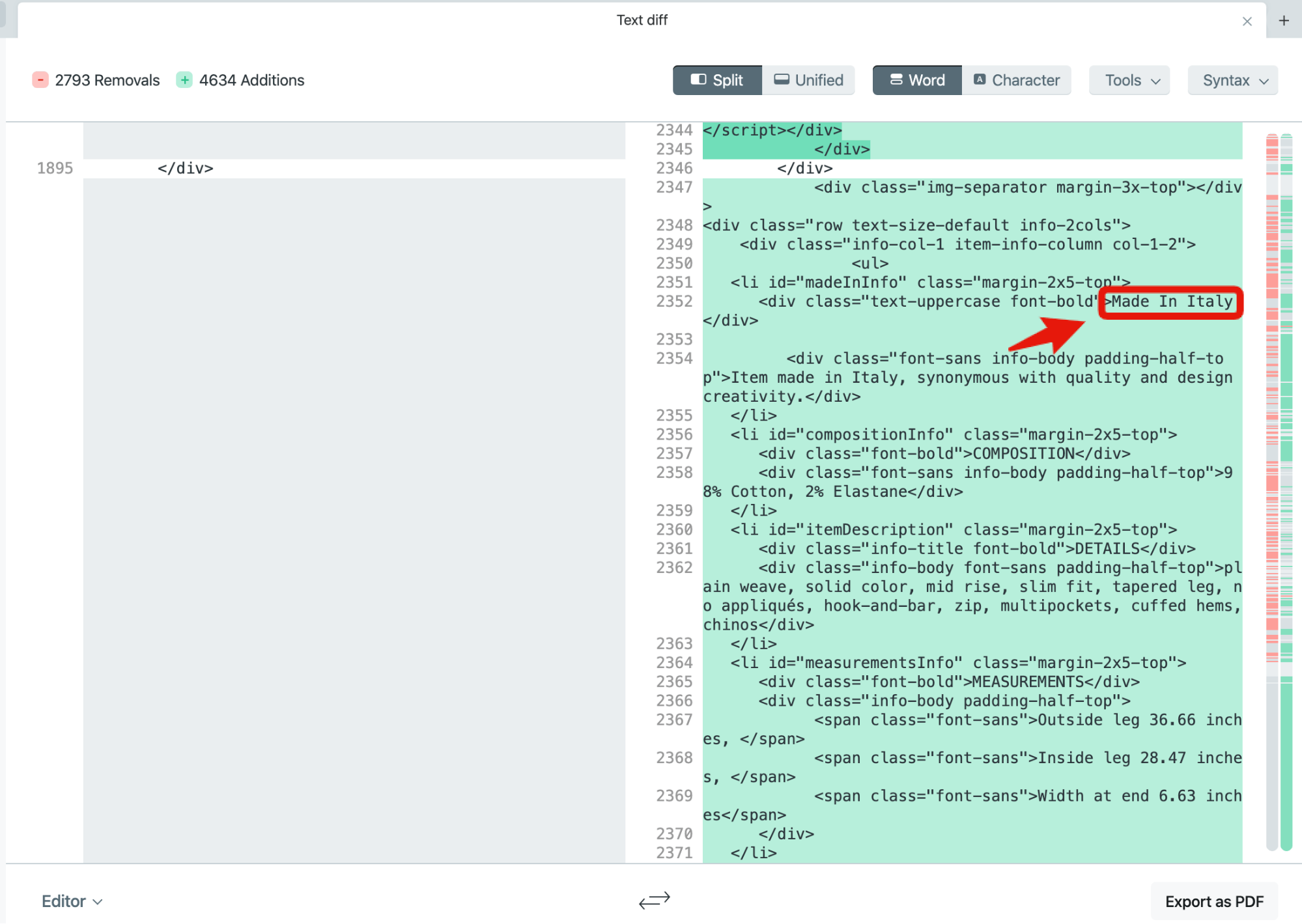
Getting the final confirmation
Now all that is left is to check if Google is also seeing this problem (some websites may be still crawled and indexed by a desktop Googlebot user agent).
Insert the text that is not indexed in quotation marks before the site command and the URL to get the final confirmation of your diagnosis. In our case it is
“made in italy” site:https://www.yoox.com/us/13041012LK/item#cod10=13041012LK&sizeId=&sizeName=
Mobile-first partial indexing is an exciting problem to diagnose, you’ll find it comes in all shapes and sizes: from a small part of the product’s description as we saw above, to tabbed content not being indexed, to even desktop version being indexed and mobile version not indexed by Google (for websites that are not mobile-first indexed yet).
The most important thing is that now you understand how to find, diagnose, and fix this problem for your website.
Now let’s look into the geekiest partial indexing problem: JavaScript related partial indexing.
JavaScript related partial indexing (the most popular partial indexing problem)
JavaScript-related partial indexing was my “gateway drug” into indexing problems. I first saw it in the wild more than 5 years ago and I was instantly hooked. I was shocked to see how many websites have large parts of their content not indexed by Google.
JavaScript partial indexing is the most popular and unfortunately the most severe indexing problem as it often affects the main content of the page. As a consequence, it makes it almost impossible for this page to rank well.
For now, let’s focus on the most popular JavaScript partial indexing problem – dynamically added content. Walmart.com is struggling with this problem quite a bit. Let’s dive right into it.
The URL we will analyze:
https://www.walmart.com/ip/Hipshot-Guitar-Extender-GT1-Black/220718905
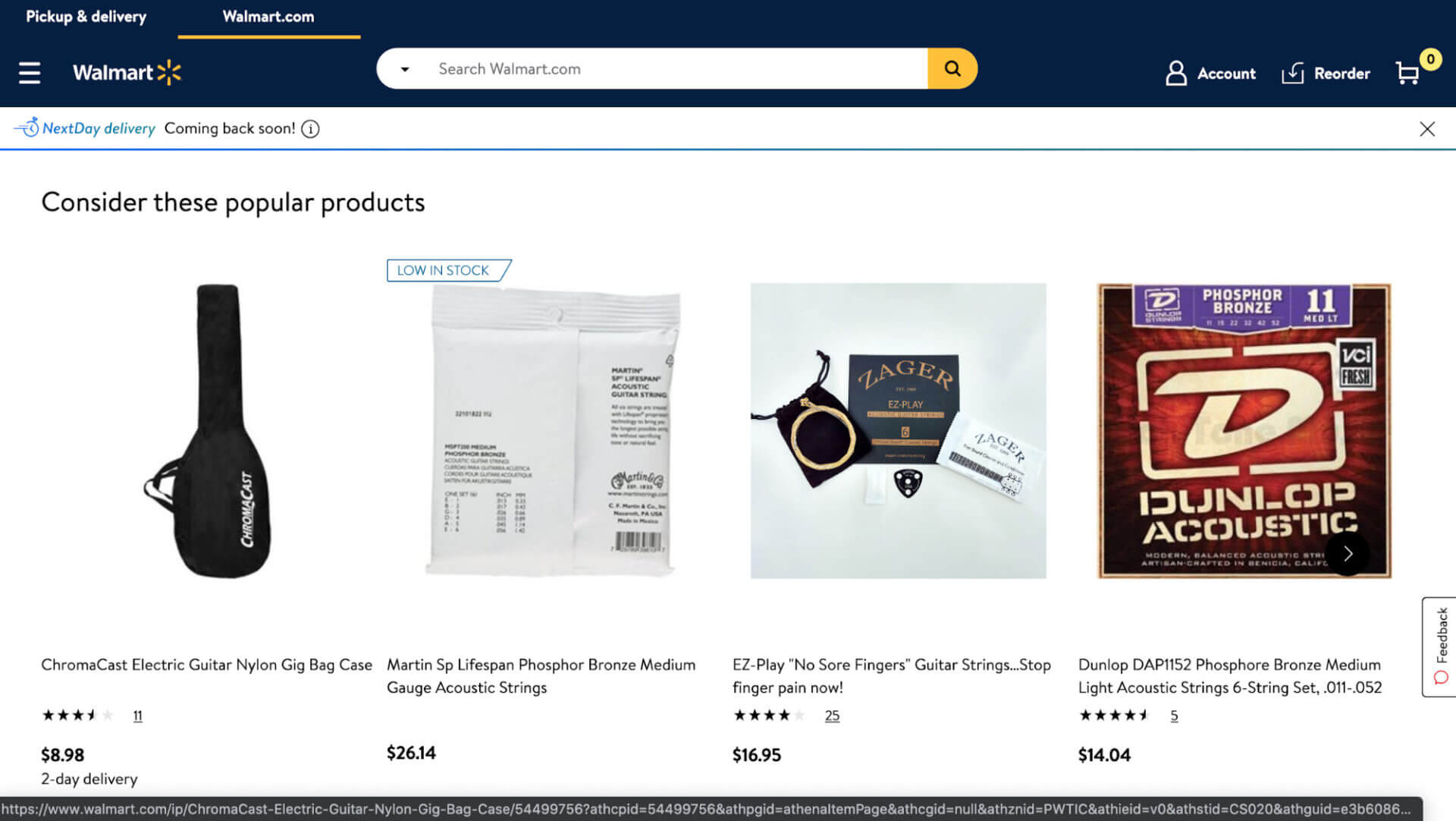
I chose this URL for a number of reasons
- JavaScript content is loaded above the main product (probably due to this product being currently out of stock).
- The way that this JavaScript content is loaded is causing a huge layout shift as you can see in the video below:
- JavaScript content is visible on both mobile and desktop. However, on a mobile device, JavaScript content is placed underneath the product description.
- With ~4MB of JavaScript and ~6 seconds of scripting, this page makes a perfect candidate for JavaScript-based indexing problems.
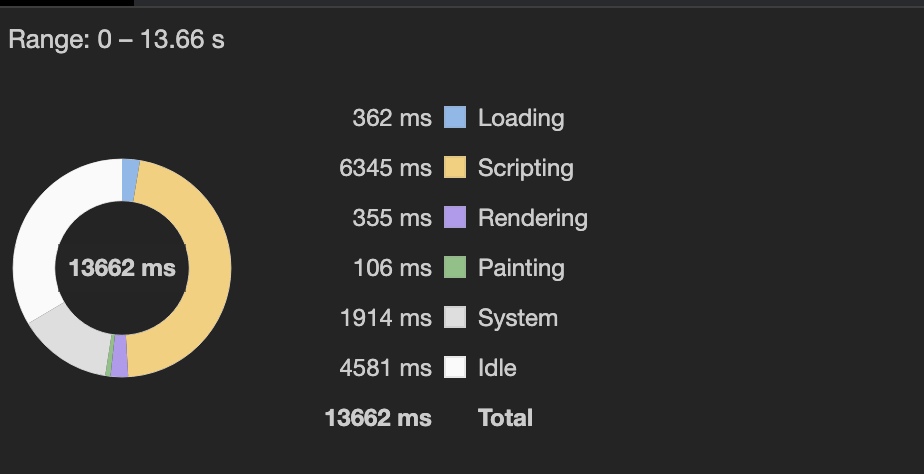
- We’ve been tracking this URL for a few months now and I’m pretty sure that this page won’t be fully indexed even after this article is published.
Now, let’s dive into the diagnostics.
Step 1
Check what content is not visible with JavaScript disabled. You can disable JavaScript in Chrome Dev Tools, but there is also an easier and quicker way. Simply download the “Quick JavaScript Switcher” Chrome plugin.
Video embedded
https://www.dropbox.com/s/eyn8owc8y28ymx3/Screen%20Recording%202020-08-26%20at%2011.49.16.mov?dl=0
You can see that the whole “Consider these popular products” section disappears with JavaScript switched off.
Step 2
Now all that is left for us is to see if Google decided to render and index JavaScript dependent content. To do so, simply use the site: command + “Consider these popular products”.
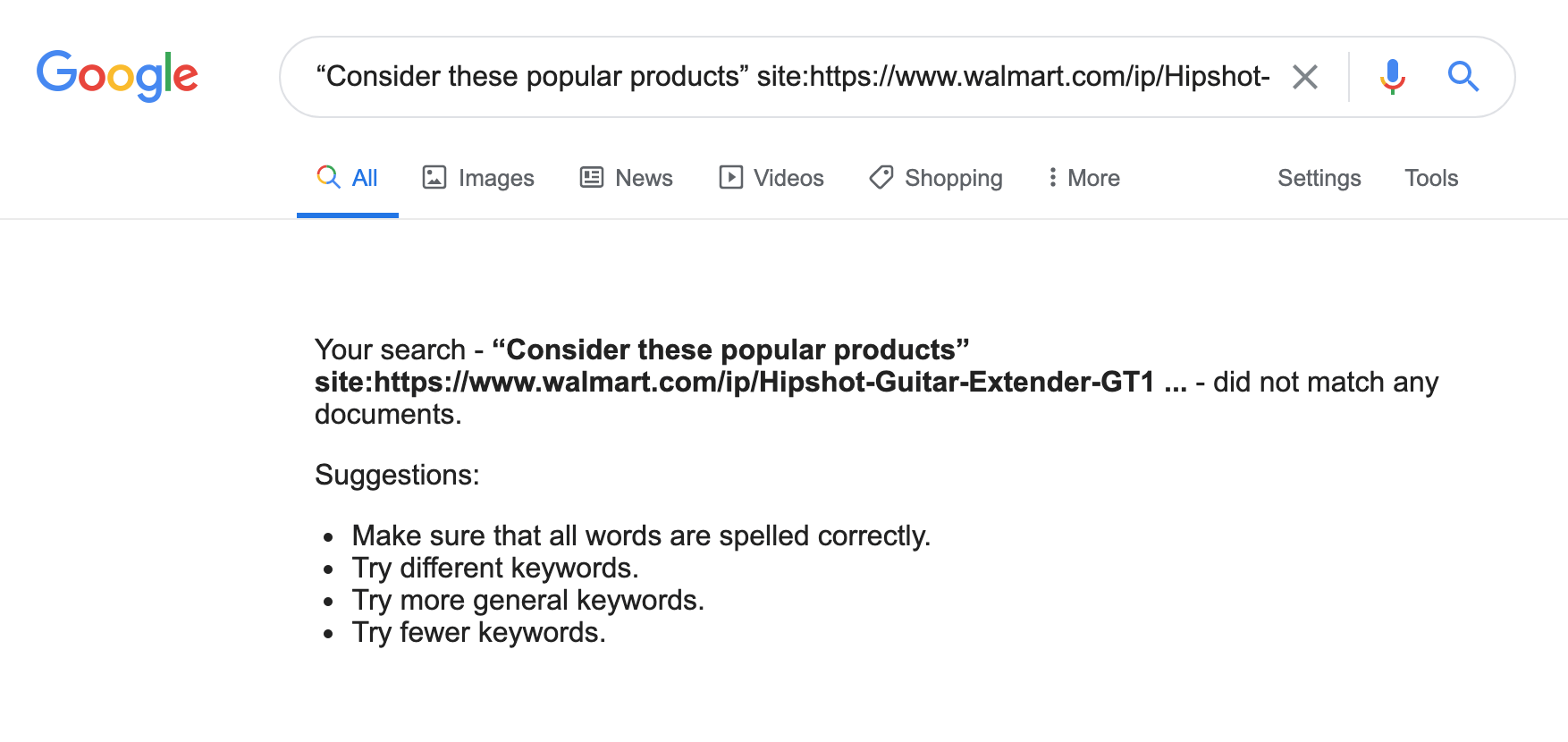
Now we can clearly see that Google didn’t index this part of the page’s content.
How to fix it?
Fixing this problem is a topic for a whole other article, but to keep it simple, you have a few options:
- Server-side render (preferred solution) or prerender (often, not the best solution) JavaScript content for search engines.
- Consider optimizing the JavaScript code responsible for generating the “Consider these popular products” section. In fact, in the case of Walmart, this should be done anyway due to all web performance and UX (layout shift) problems this section generates.
- Consider removing this section altogether. This may sound extreme, but in some cases, if your web development team cannot quickly optimize this section, removing it until they do could be a better solution for your users and for the search engines.
Here are a few other URLs + fragments to play with:
Layout based partial indexing
This is our latest finding in the field of Rendering SEO, indexing and how Google understands the layout of your page. Googlers actually confirmed layout-based indexing problems we presented during our Rendering SEO manifesto in June 2020.
Before I explain this part in-detail, let’s hear a quick explanation of this phenomenon from our webinar with Google’s Martin Split.
Let me quickly explain how layout-based partial indexing works.
- Google has limited resources.
The World Wide Web is getting flooded with content every day. This problem has grown so significant that Google needs to save their resources to keep indexing and ranking valuable content
- Google can skip indexing part of your page if it is not directly related to your page’s main content.
As Martin explained it, if your page is about dogs, from the search engine’s point of view, it is crucial to make sure that all of the valuable dog content is indexed. This means that all of your “similar products”, “you may also be interested in” etc. sections may be skipped from indexing altogether as they don’t bring value to search engines. Let’s call this process Search Engine’s Decluttering.
- It is your responsibility as a technical SEO to be able to track it, diagnose and understand all the layout based indexing issues.
Partial indexing may not always be a bad thing. However in many cases, parts of your page that Google chose not to index, are parts that are made “for SEO reasons”.
- Sections linking to new products to make sure they are indexed
- Page Rank sculpting
- All other forms of internal links to “boost indexing and crawling”
All of the strategies I mentioned above are slowly going away. The data we gather in TGIF show that in many cases, those solutions often do more harm than good as they are not getting indexed and they make it very difficult to get crawl data that actually reflects your website’s structure as Google sees it.
Let’s look at some examples of partial HTML indexing. You already know how to diagnose partial indexing so I am going to leave this to you as your homework assignment. :)
- site:https://www.merriam-webster.com/words-at-play/the-good-the-bad-the-semantically-imprecise-november-16-2018 “SCOTUS: ‘Arbitrary and Capricious'”
- site:https://www.merriam-webster.com/words-at-play/the-good-the-bad-the-semantically-imprecise-november-16-2018 “More Words At Play'”
- site:https://www.walgreens.com/store/c/saba-ultra-invisible-long-thin-pads-with-wings/ID=prod6381549-product “frequently bought with”
How to earn your place in Google’s index?
Over the last few years, I spent hundreds of hours looking into how rendering and indexing works at Google. This year, Google reached out to us and actually confirmed our findings and to my surprise, Googlers also seem to be very interested in getting this message across.
The sad part is that when talking about this topic, I noticed how hard it actually is for Googlers to get the SEO community to change our ways.
JavaScript SEO, understanding how Google renders your content and how they understand your layout, information architecture, basics of web performance and real user metrics are still not nearly as popular as PageRank sculpting, footer links, “SEO texts”, “similar items” that “boost indexing”.
I truly hope that this article and all of the research into Rendering SEO I am sharing with you will help you understand those geeky parts of technical SEO a little bit more so we can all focus on building better, faster websites that are not only easier for the search engines to understand, websites that actually get indexed by Google (and other search engines) as it is not something that happens by default anymore.
We need to earn our place in Google, and for the first time in the history of technical SEO we have so much understanding into how crawling, rendering and indexing works. Let’s use it to our advantage.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


