How Search Engines Process Links
Ever wondered how search engines crawl, analyze, index, and rank pages? Columnist Jenny Halasz has created a helpful primer on the link graph to answer these questions.

Have you ever wondered why 404s, rel=canonicals, noindex, nofollow, and robots.txt work the way they do? Or have you never been clear on quite how they do all work? To help you understand, here is a very basic interpretation of how search engines crawl pages and add links to the link graph.
The Simple Crawl
The search engine crawler (let’s make it a spider for fun) visits a site. The first thing it collects is the robots.txt file.
Let’s assume that file either doesn’t exist or says it’s okay to crawl the whole site. The crawler collects information about all of those pages and feeds it back into a database. Strictly, it’s a crawl scheduling system that de-duplicates and shuffles pages by priority to index later.

While it’s there, it collects a list of all the pages each page links to. If they’re internal links, the crawler will probably follow them to other pages. If they’re external, they get put into a database for later.
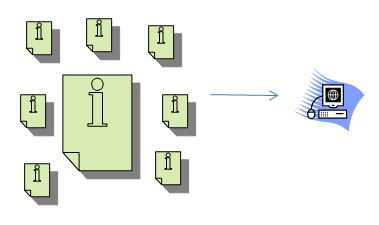
Processing Links
Later on, when the link graph gets processed, the search engine pulls all those links out of the database and connects them, assigning relative values to them. The values may be positive, or they may be negative. Let’s imagine, for example, that one of the pages is spamming. If that page is linking to other pages, it may be passing some bad link value on to those pages. Let’s say S=Spammer, and G=Good:
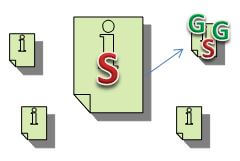
The page on the top right has more G’s than S’s. Therefore, it would earn a fairly good score. A page with only G’s would earn a better score. If the S’s outweighed the G’s, the page would earn a fairly poor score. Add to that the complications that some S’s and some G’s are worth more than others, and you have a very simplified view of how the link graph works.
Blocking Pages With Robots.txt
Let’s go back to that original example. Suppose the robots.txt file had told the search engine not to access one of those pages.
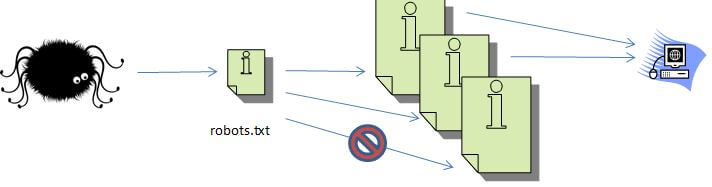
That means that while the search engine was crawling through the pages and making lists of links, it wouldn’t have any data about that page that was included in the robots.txt file.
Now, go back to that super simple link graph example. Let’s suppose that the page on the top right was that page that was blocked by robots.txt:

The search engine is still going to take all of the links to that page and count them. It won’t be able to see what pages that page links to, but it will be able to add link value metrics for the page — which affects the domain as a whole.
Using 404 Or 410 To Remove Pages
Next, let’s assume that instead of blocking that page with robots.txt, we simply removed it. So the search engine would try to access it, but get a clear message that it’s not there anymore.

This means that when the link graph is processed, links to that page just go away. They get stored for later use if that page comes back.

At some other point (and likely by a different set of servers!), priority pages that are crawled get assigned to an index.
How The Index Works
The index identifies words and elements on a page that match with words and elements in the database. Do a search for “blue widgets.” The search engine uses the database to find pages that are related to blue, widgets, and blue widgets. If the search engine also considers widget (singular) and cornflower (a type of blue) to be synonyms, it may evaluate pages with those words on the page as well.
The search engine uses its algorithm to determine which pages in the index have those words assigned to them, evaluates links pointing to the page and the domain, and processes dozens of other known and unknown metrics to arrive at a value. If the site is being filtered for poor behavior like Panda or Penguin, that is also taken into account. The overall value then determines where in the results the page will appear.
This is further complicated by things webmasters might do to manipulate values. For example, if two pages are very similar, a webmaster may decide to use rel=canonical to signal the search engine that only one of those pages has value. This is not definitive, though. If the “cornflower widget” page is rel=canonical-ed to the “blue widgets” page, but the cornflower widget page has more valuable links pointing to it, the search engine may choose to use the cornflower widget page instead. If the canonical is accepted, the values of both elements on the pages and links pointing to the pages are combined.
Removing Pages With NoIndex
Noindex is more definitive. It works similarly to robots.txt except that instead of being prevented from crawling that page, the search engine is able to access it, but then is told to go away. The search engine will still collect links on the page to add to the database (unless a directive on the page also indicates not to follow them, i.e. nofollow), and it will still assign value to links pointing to that page.

However, it will not consolidate value with any other pages, and it will not stop value from flowing through the page. All noindex does is request the search engine not assign the page to its index.
Therefore, there is only one definitive way to stop the flow of link value at the destination. Taking the page away completely (404 or 410 status) is the only way to stop it. 410 is more definitive than 404, as you can read here, but both will cause the page to be dropped out of the index eventually. There are multiple other ways to stop link flow from the origination of the link, but webmasters seldom have control over other sites, only their own.
Hopefully, this primer has helped you understand how pages are accessed by search engines and the difference between robots.txt, noindex, and not found, especially as they relate to links. Please leave any questions in the comments and be sure to check out my session at SMX Advanced: The Latest in Advanced Technical SEO.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author