Up Close @ SMX: Enhancing Results With Structured Data & Markup
When you think about the job the search engines have to do it’s pretty daunting. Given a collection of mostly wildly unstructured data from an endless number of sources, Bing, Google and the others have to somehow make sense of all that information and then give it back to us on demand in a way […]
When you think about the job the search engines have to do it’s pretty daunting.  Given a collection of mostly wildly unstructured data from an endless number of sources, Bing, Google and the others have to somehow make sense of all that information and then give it back to us on demand in a way we’ll understand.
Given a collection of mostly wildly unstructured data from an endless number of sources, Bing, Google and the others have to somehow make sense of all that information and then give it back to us on demand in a way we’ll understand.
Fortunately, web masters have more tools than ever to present that data, and the search engines are getting smarter about how they accept it. Using structured data and markup including RDFa, schema, hCard, Open Graph, and Twitter Cards.
In my personal experience, hCard and those schema relative to location were the first we saw in the wild, followed shortly by reviews — product, business and media. With the hCard microformat we were able to mark up Name, Address, Phone Number and other entity level data important for local search.
In the Super Session: Enhancing Search Results With Structured Data & Markup, Disney Interactive’s Jeff Preston, Jay Myers of BestBuy.com, and Define Media Group’s Marshall Simmonds talked through a number of examples of the effective use of structured data markup and their impacts on search engine ranking, accessibility of data and usability for searchers.
The session was moderated by Elisabeth Osmeloski, Director of Audience Development at Third Door Media, with Q&A coordination provided by Bill Hunt, President of Back Azimuth.
Marshall Simmonds Of Define Media Group
First to the podium was Marshall Simmonds, Founder and CEO of Define Media Group who showed a number of examples from his experience working with very big sites.
Marshall took us through the evolution of indexation and then looked at examples for the implementation and impact for various structured data vocabularies. According to Marshall’s research, 30% of queries today deliver rich media in the Universal Search Results. For a good example of what some of these look like, Dr. Pete at Moz has put together the Mega-SERP: A Visual Guide to Google.
Adding to the complexity of the rendering of data in the SERPs is the fact that each of the browsers, and each of the engines, may use structured data differently. Marshall states (I think I heard this right) that there are 2 major and 2 minor updates / day in the Google algorithms.
For his presentation, Marshall looked at data since 2012 representing nearly 10 billion page views from which he was able to make some determinations of both SERP impact and traffic impact from those vocabularies and schemas his sites had implemented.
We in the SEO community have invested a lot of time and energy in Authorship, both for ourselves and on behalf of clients. The bad news from Marshall’s data is that even though there was a pretty significant SERP impact, e.g. more of our pretty faces showing up in results, the impact on traffic was negligible. Also, as Google has rejiggered the factors by which those author profile photos are shown, it’s been difficult to assure who will show and who won’t.
Marshall outlined some of the factors for Author images to show in the SERPs:
Factors – site level
- Authority of the site
- “High quality content”
- Domain longevity
- Varies based on query
Factors – author level
- Reputation – who you are, where you publish, how long
- Quality of content
- Authority of site contributing to – Guest blogging is ok!
- Varies based on query
And, you’ll be glad to know, Marshall thinks that not only is guest blogging OK, it seems as though guest blogging on authority sites may have a positive impact on your reputation.
Other data types that Marshall talked about the markup of were:
- TV Reviews
- Product Reviews
- Recipes
- Articles
- Video
My big takeaway from this confirms our recent thinking at Search Influence which is that one should try to structure all the data.
From Marshall’s examples, it would seem that if you’re a news site or publisher, that you really want to invest in media (e.g. TV, live entertainment) and product reviews, recipes if it makes sense, and video schema.
The case for TV Reviews:
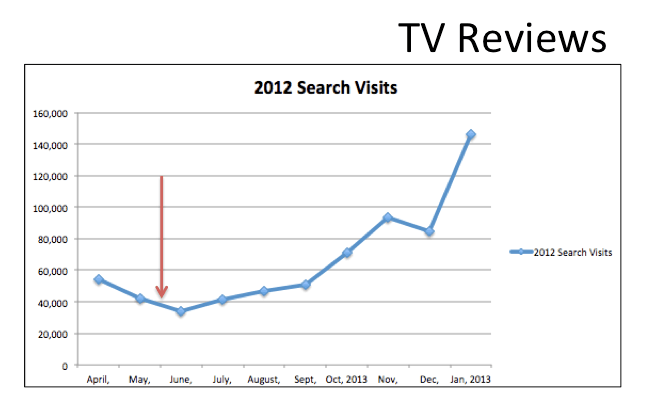
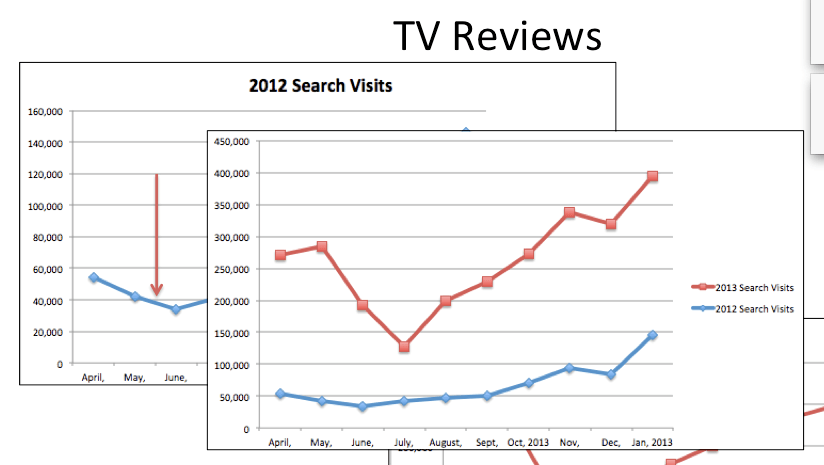
Marshall summarizes the results of his study as follow:
- Authorship – Slow-Medium, Sporadic Appearance – Minimal traffic impact
- TV Reviews – Fast indexation, Slower Appearance (seasonality) — Medium traffic impact
- Product Reviews – Fast indexation, Fast Appearance – Good traffic impact
- Recipes – Fast indexation, Fast appearance – Minimal traffic impact
- Article – Difficult to track, Doesn’t require Schema.org – Favors big brands – Good traffic impact
- Video – Fast indexation, Very Fast appearance – Significant impact
His presentation included some great tools as well. You should check it out on the SMX Slideshare embedded below.
Jay Myers Of BestBuy.com
Next up was Jay Myers, Emerging Digital Platforms Product Manager – Product Recommendations at BestBuy.com. Jay told the story of how Best Buy originally started down the structured data path on the belief that “Every store has valuable data that should be exposed”.

Jay Myers
I know from personal experience that Best Buy now does an exceptional job of presenting the rich data one needs as a customer and was pleased to see Jay talk about the genesis of that. As it turns out, Jay and Best Buy were very early in their use of structured data, most particularly RDFa.
In the early days of Best Buy’s path down the structured data road, Jay was contacted by Martin Hepp, keeper of the Good Relations Ontology — a structured markup vocabulary which predated schema by a few years.
Along with other efforts, Jay and his team marked up product pages with RDFa and saw a 2X YoY increase in traffic to their store pages. Again, Jay is quick to point out there were multiple efforts ongoing.
Their initial efforts included:
- Publish data that has valuable meaning beyond keywords
- “Clean” and “Cool” URLS
- Syntax: RDFa – Resource Description Framework in Attributes
- Ontologies used included:
- GoodRelations – The Web Vocabulary for Ecommerce
- FOAF – Friend of a Friend
- GEO – Basic methods for representing spatially-located things
According to Jay, the “Best Buy shopping URLs served as rich data experiences”.
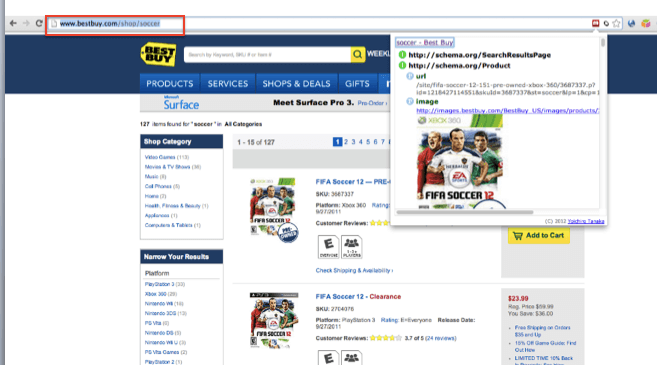
Now, as the technologies have matured, Best Buy is using vocabularies from Microdata and Schema.org. In addition to their on-site markup, Best Buy is taking advantage of rich data to deliver to customers information before the click. For example, delivering Stock data right in the SERPs.
Jay also gave an interesting preview of the future of structured data in the form of Rich Pins, Gmail Actions in The Inbox and more.
Jeff Preston Of Disney Interactive
The final presenter was Jeff Preston, Senior Manager, SEO at Disney Interactive who spoke about Schema.org, Open graph and Twitter Cards. Jeff showed a number of examples of how Disney uses these technologies on their entertainment properties. And they were pretty cool.

Jeff Preston
Jeff started by pointing out that structured data is not a cure all. First, a company has to fix their site’s underlying SEO problems. Much like in architecture school, where we learned “you can’t fix anything with paint”.

Jeff’s presentation was a great review of these technologies with some good examples from the Disney portfolio.
Some of the more interesting highlights from Jeff’s talk were an example of where they used schema site navigation markup to influence site links in the SERPs.
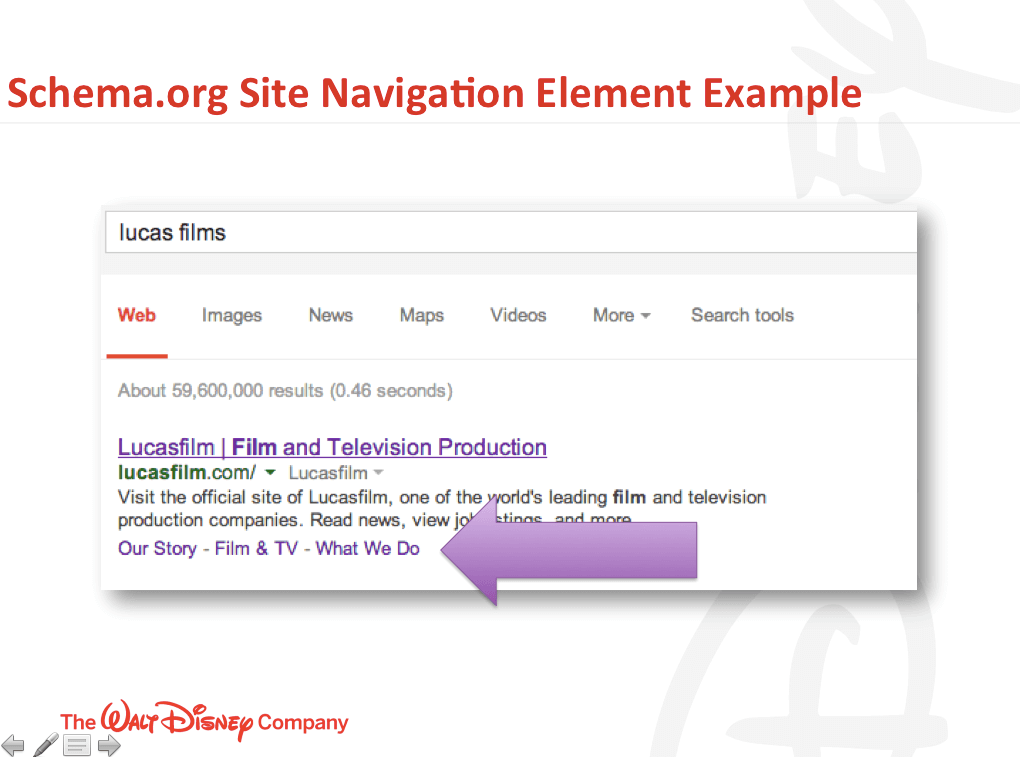
This example was so cool I saw Marshall taking a picture of it.
Another useful example was regarding the use of Twitter Cards. Jeff’s team had set a Twitter Card for a specific URL for an upcoming movie, Big Hero 6, and was able to have that be the default card for tweets, even when re-tweeting a prior, different image.
Before:
See a clip of the teaser trailer and poster for #BigHero6: https://t.co/A1K4bgcDA5 pic.twitter.com/SRdoxNFa8G
— Oh My Disney (@OhMyDisney) May 21, 2014
After:
These New Images from Big Hero 6 Are Awesome | Oh My Disney https://t.co/9ns8ZC9Bhf — Jeff Preston (@jeffreypreston) May 23, 2014
Jeff talked about the knowledge graph, and what data sources might influence it, including Wikipedia, Freebase and Schema.org.
Freebase — another Google product — doesn’t get enough attention, but in Jeff’s case, edits there were able to affect display of movie data in a short period of time.
Jeff really helped to bring focus to the SEO benefit of some of these tools. As we all know, attention is the greater asset searchers can give and for Jeff, rich data allows more room in the SERP, stream and feed, giving you more opportunity to keep their attention.
Questions And Answers
In the Q&A, the panelists asked the best questions.
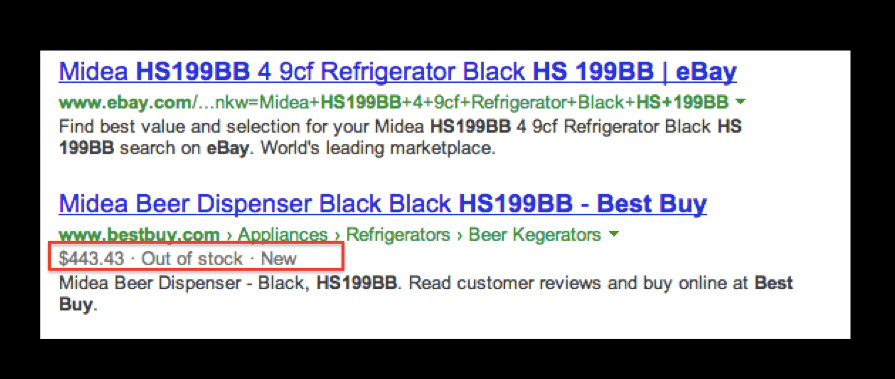
Marshall asked Jay if he was concerned that by driving so much information to the SERP there wasn’t a risk of inaccuracy due to Google’s update lag. E.g., if an item showed out of stock in the SERP would he worry about Google not updating in time to serve a customer need. Marshall says “I’d be scared Google wouldn’t come back and recrawl.”
Jay indicated that in Best Buy’s case they identify stock as True/False, in other words, we have it or we don’t — they update those flags daily and they trust Google to pick up the new data.
There was discussion of the Knowledge Graph, and what’s driving its inclusion in the SERPs by way of the mini-knowledge graph — a small gray “more info” link in the SERPs themselves. Marshall suggested that this may be driven by rel=publisher (which doesn’t get nearly enough play, in my opinion).
Elisabeth asked in the Q&A for examples of when one wouldn’t want to have markup data on their sites. As in, is there a time when you would want to not make data accessible? The panel universally said there was not. More accessible data makes for better information retrieval and better SEO.
I was reminded in the question about accessibility of data of a conversation I had in 2006 with a Yellow Pages publisher. The CTO of a large yellow pages company was telling me all about their “anti-scraping technology” while I was telling him the greatest imperative was to get their data accessible to search engines.
The final question, and one we struggle with often was “Are you worried about a future when searchers won’t have to come to your site”?
To which Jay responded “it’s already happening. We want to be found in all the relevant places.” And Jeff indicated it wasn’t so much of a problem for entertainment, but that his colleagues in sports have expressed concern regarding scores and the like.
My takeaways were: markup all the things and if you’re a news or media site look for ways to further enrich the data you already have.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author