Technical SEO in the wild: Real-world issues and fixes
A website has a lot of moving parts that affect one another and sometimes a tiny little change can cause a huge problem.
A lot of what is written about technical search engine optimization is pure theory; ideal-world scenarios of how websites should interact with search engine crawlers and indexing systems.
In the real world, things get messy. Websites aren’t pristine content delivery systems, search engines aren’t infallible artificial intelligence overlords and people who code websites make plenty of inadvertent mistakes.
Over the years I’ve analyzed countless websites for technical SEO issues, and I’ve encountered numerous problems that aren’t easily explained by pure SEO theory. Instead, these issues required some practical approaches to resolve, and sometimes the root cause of the issue remains unexplained.
Here I will outline some of these issues and hopefully give you a few ideas to troubleshoot and fix similar problems yourself if you ever happen to come upon them.
Structured data and rich snippets
One of my clients had recently migrated their website to a new technology stack that was, by all accounts, faster and better optimized than the previous version of their website. Before the migration, this client enjoyed a lot of rich snippets in Google’s search results. Specifically, they had star-rating snippets on most of their key pages.
However, after their migration, they quickly lost all of these star ratings. And we couldn’t figure out why.
Google’s Structured Data Testing Tool (SDTT) offered no help. The structured data on the site was properly recognized by the tool and seemed to be perfectly valid markup. So why did Google ignore the markup and remove the star-rating snippet from this client’s pages?
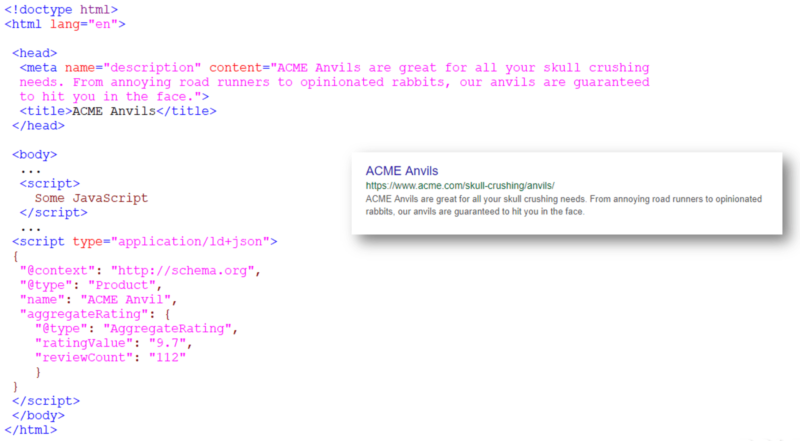
We decided to try something that we thought wouldn’t make much difference, but ended up solving the whole issue: we moved the structured data snippet to the < head > section of the page’s source code.
This made no difference for the SDTT, as it didn’t affect the markup’s validity in any way. It was more a last-gasp effort to see if the order in which things appeared in the HTML source code affected the way Google processed it.
Shortly after we made this change, the site’s rich snippets rapidly started coming back. Within a few days, all of the lost star-rating snippets had returned.
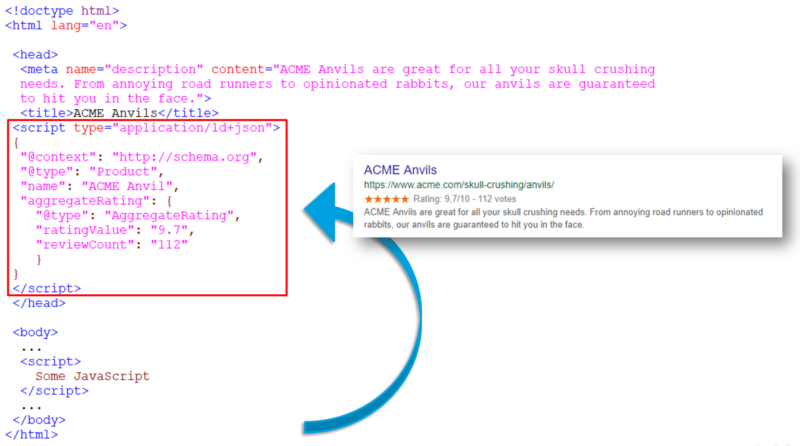
The position of the structured data markup made a huge difference in how Google handles it.
While theoretically, it shouldn’t have made any difference where the markup sits – as long as it is present in the raw HTML source code – in practice the snippet should be in the < head > section for a site to achieve rich snippets in search engine results pages.
This is not immediately evident from Google’s documentation. There is no explicit mention of having to put the markup in a page’s < head > section and not in the < body >.
Yet, off the back of this issue, I have made it my recommendation to always put your structured data markup in the < head > section of a page’s HTML source code. This seems to result in easier processing of the structured data by Google and has helped with achieving rich snippets for more of my clients.
Hreflang meta tags and iframes
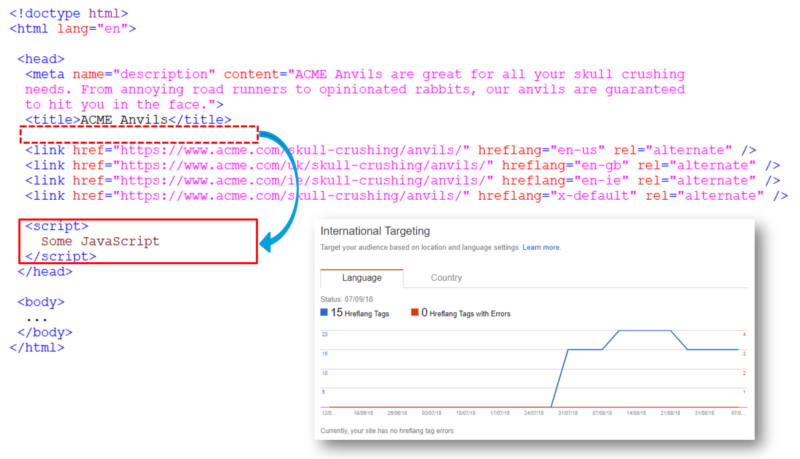
I encountered a similar issue fairly recently. A client’s site had implemented hreflang meta tags on their homepage to indicate alternative versions targeting different countries. These hreflang tags were perfectly valid and present in all versions of the homepage, yet Google failed to recognize them.
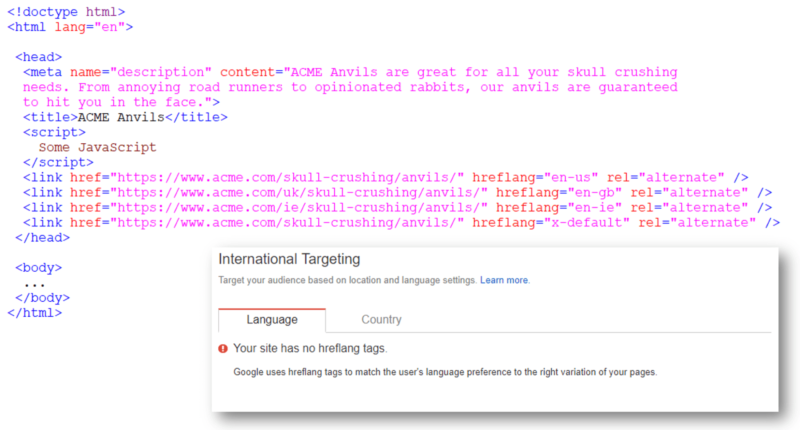
The client’s developers had racked their brains trying to figure out what could prevent Google from processing these hreflang meta tags. The tags were present in the page’s HTML source code in the < head > section, as they are supposed to be, and they had full reciprocity from all the other homepages. There shouldn’t have been any issue with these tags.
And yet, Google did not report them in Search Console and tended to show the wrong country’s version in its international search results.
When I took on this client, one of the first things I did was to compare the page’s HTML source code to the completed DOM. The former is what you see when you do a “view source” on a page, and the latter is what the browser uses to show the page to end users when all client-side code (such as JavaScript) is executed.
And here I spotted something very interesting: in the raw HTML code there was a piece of JavaScript that sat above the hreflang meta tags. When the page was fully rendered and all the client-side code was executed, the JavaScript had inserted an < iframe > in the page.
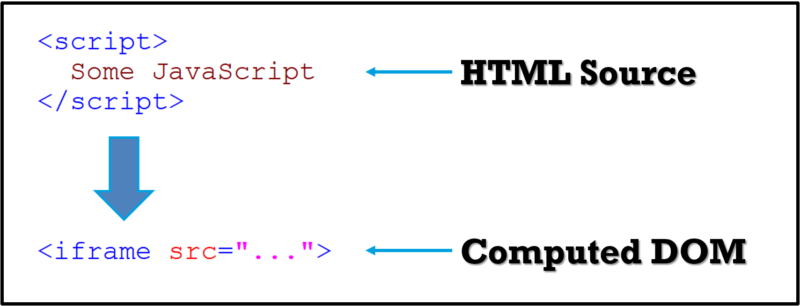
This iframe then sat above the hreflang meta tags. And this, as it turns out, was a problem.
You see, iframes don’t belong in a webpage’s < head > section. According to the official HTML5 standard, iframes are only supposed to exist in a page’s < body > section. Putting an iframe in the < head > section of a webpage’s code is against the official W3C standard.
When Google indexes webpages, it tries to account for a lot of such standard-breaking issues. It’s very rare to find a webpage that has completely W3C compliant code. Fortunately, HTML is a very tolerant markup language. Web browsers and search engines can handle most webpages just fine even if those pages have invalid markup.
This instance, however, proved to be problematic, and it relates to Google’s two-stage indexing process. The first stage of indexing is based on a webpage’s HTML source code and no client-side scripts are executed as part of this indexing process. Then Google also does a second-stage indexing of the same page, where client-side scripts are loaded and the page is fully rendered as a web browser would.

In this second stage of indexing, the JavaScript in the page’s HTML source that sits above the hreflang tags is executed, and the iframe is inserted into the page’s code.
As I was analyzing this issue, I remembered a recent twitter conversation between Jamie Alberico and Google’s John Mueller about exactly this: iframes in the < head > section of a page’s rendered code:
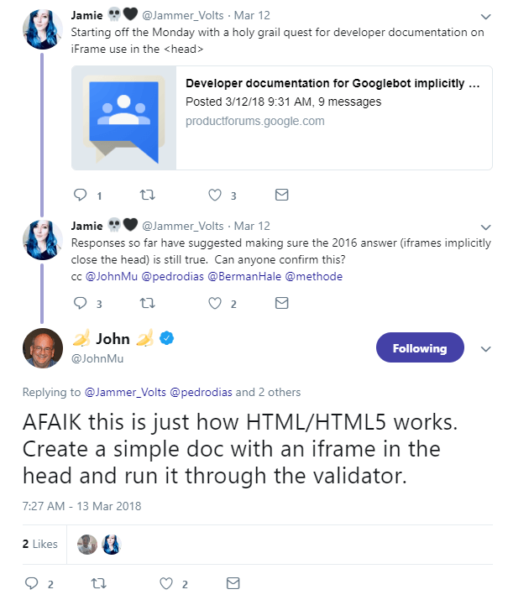
In a nutshell, iframes don’t belong in the < head > of a page’s code; they are supposed to be in a page’s < body > section. When Google sees an iframe in the < head >, it assumes the < head > has ended and the page’s < body > has begun.
Conversely, hreflang tags are only valid if they exist in a page’s < head > section. Any hreflang tags in a page’s < body > are seen as invalid and duly ignored by Google.
It seems that Google processes hreflang meta tags as part of the second stage of indexing. This created a perfect storm for my client where Google renders the page and the iframe is inserted into the code. This then caused Google to prematurely process the rest of the code as part of the < body > and thus ignore the presence of the hreflang tags.
Again, once we found the underlying issue, the solution was simple. We moved the offending JavaScript to the end of the < head > section where any insertion of an iframe could cause no damage.
Within a few days, Google recognized the page’s hreflang meta tags and started reporting their presence in Search Console.
Googlebot and automatic IP redirects
Several years ago I encountered an issue that, at the time, really confused me. A client had just launched a new version of their site and as part of their expansion strategy they had different country versions of their site; one aimed at the USA, one at the UK and one for the rest of the world.
The US version of the site very quickly began to rank and seemed to perform well. However, the UK and rest of the world sections were hardly getting any traffic from Google. Historically the UK had been the client’s biggest audience and the new site was massively underperforming in the British market.
Looking at the data in Webmaster Tools didn’t help either. This was way before Google renamed it to Search Console and gave us more useful data. At that time, all I had to go on was the Index Status report which showed a fairly low number of indexed pages. The Sitemaps report also didn’t help much – we had submitted one XML sitemap containing all of the site’s pages and here too we only saw a low level of indexing with no real hint as to what caused the issue.
A week or two after the site’s launch, I woke up in the middle of the night with a “Eureka” moment. I suddenly knew what the root problem was.
You see, this new site used automatic redirects based on a user’s IP address. The site would determine what country a visitor’s IP address was associated with and then automatically redirect the visitor to the correct version of the site’s content.
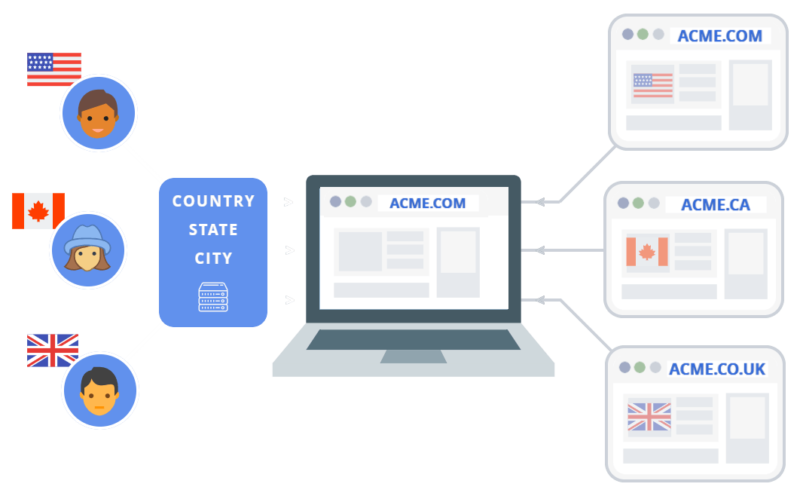
When Googlebot crawls a site, it does so primarily from IP addresses based in the US. It very rarely, if ever, crawls websites from international IP addresses.
Because the site’s automatic IP redirects were present on all pages, every attempt to view a page that didn’t align with your current country meant that you’d be redirected to the right country.
For Googlebot, this meant that it couldn’t see any other section of the site except the US section.
Whenever Googlebot tried to crawl the pages in the UK and rest of the world sections, it would be redirected by the site to the US section. So while Googlebot had full visibility on the American pages, it couldn’t see – and thus couldn’t index – the other sections of the site.
Once we understood the problem, the solution was simple: we changed the automatic IP redirect to make exceptions for Googlebot visits. That way, Googlebot was never redirected to any specific country and could freely crawl the entire website.
After we made this change, the level of indexing on the site improved massively and the UK section gained a lot of traffic from Google in a short amount of time to bring it back to pre-migration levels.
Technical SEO in the real world
What I hope these examples show is that in the real world, technical SEO issues can be very tough to identify. A website has a lot of moving parts that affect one another and sometimes a tiny little change can cause a huge problem somewhere down the line.
When you analyze a website, you don’t always have all the data you’d like to. The IP redirect issue, for example, would have been easier to identify if we’d had different XML sitemaps for each country version but that wasn’t the case so we had to extrapolate from what little information we had.
It takes a good understanding of SEO in general, and technical SEO in particular, to be able to identify, analyze and fix such issues. Having a good understanding of how search engines crawl and index web pages is mandatory – this is the root of all technical SEO.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author