Do As I Say, Not As I Do: A Look At Search Engines & SEO Best Practices
Now that the holidays are upon us, we all probably could use some cheering up. So I thought I’d have some fun with our favorite search engines: Google, Yahoo, Bing, YouTube, and Blekko. At Nine By Blue, I have been developing software that automatically checks sites for technical SEO best practices. Normally we run it […]
Now that the holidays are upon us, we all probably could use some cheering up. So I thought I’d have some fun with our favorite search engines: Google, Yahoo, Bing, YouTube, and Blekko.
At Nine By Blue, I have been developing software that automatically checks sites for technical SEO best practices. Normally we run it on our clients’s sites to quickly check for issues and monitor them for any future problems.
But I was curious to see what I would find if I pointed the software at some typical pages on the search engines’s sites and then compare their implementations with the technical SEO best practices that we typically recommend.
Below is a list of some of the issues that I found in no particular order.
Disclaimer #1: This list is intended to point out how difficult it is to fully optimize a site for SEO, especially large-scale enterprise sites. I’m not claiming that I could have done any better, even if I had full control of these sites.
Disclaimer #2: Yes, I’m aware of Google’s SEO report card, but I have never read it because it is too long. Also, I didn’t want to be influenced by it.
Use a Link Rel=Canonical Tag On The Homepage
Most of the sites that I reviewed had many different URLs that lead to the home page. This can be because of tracking parameters (i.e. https://www.site.com/?ref=affilliate1) or default file names (i.e. https://www.site.com/index.php), or even duplicate subdomains (https://www1.site.com/).
Because of this, I always recommend putting a link rel=canonical tag on the home page. This ensures that links to these different home page URLs all get counted as pointing to the same URL. I also recommend adding this tag for any other pages that might have similar issues.
I was surprised to find that Bing was the only site that had a proper link rel=canonical tag on the home page.
YouTube also has a link rel=canonical tag, but it was pointing to an improper URL “/” instead of the full URL “https://www.youtube.com/”.
Avoid Duplicate Subdomains & 301 Redirect Them To The Main Subdomain
With a few exceptions, I have been able to find a duplicate copy of the sites that I review.
I have a list of typical subdomains — like www1, dev, api, m, etc. — that will generally turn up a copy of the site. Other duplicate copies of a site can be found at the IP address (i.e. https://192.168.1.1/ instead of https://www.site.com/) and by probing DNS for additional hostnames or domains.
These duplicate subdomains or duplicate sites have a negative effect on SEO because they make the search engines crawl multiple copies of your site just to get one copy. It can also cause links intended for a particular page to be spread out among multiple copies, reducing the page’s authority.
The best way to fix this is to use a permanent (301) redirect to canonical subdomain’s version of that URL. If that isn’t possible, then a link rel=canonical tag pointing to the canonical subdomain page will work almost as well.
For example, an entire duplicate copy of Bing.com is available at https://www1.bing.com/. Compounding this is the fact that the page has a link rel=canonical tag also pointing to https://www1.bing.com/ and all the links on the page point to www1 as well.
Other subdomains, such as www2 through www5 and www01, all properly redirect to www.bing.com with a 301.
Blekko has an old, pre-launch copy of its site at https://api.blekko.com/. (Here is their old executive page.) Fortunately, this subdomain has a robots.txt file that is preventing it from being crawled. But these pages, like the old executive page at https://api.blekko.com/mgmt.html is also available at https://dev.blekko.com/mgmt.html and the main subdomain at https://blekko.com/mgmt.html.
It would be better to 301 redirect these URLs to the current management page at https://blekko.com/ws/+/management than to leave multiple copies of them on different subdomains.
YouTube redirects its duplicate subdomains www1 through www5 to www.youtube.com, which is in line with best practices. Unfortunately, it redirects with a 302 (temporary) redirect rather than a recommended 301 (permanent) redirect.
Use Permanent Redirects From https: URLs To http: URLs IF They Don’t Require SSL
Another type of duplicate copy of a site that I usually find is the SSL/https version of the site. https is appropriate for pages that require security, like a login page or a page for editing a user profile, but for pages that don’t require security, it is a source of duplicate content causing crawl inefficiency and link diffusion.
The recommended solution for this is to redirect pages from https to http whenever possible.
Our software detected duplicate https copies of most pages, including Microsoft’s help pages, the YouTube about pages, Google’s corporate page, and even the Google webmaster guidelines.
The duplicate content issue with the Google webmaster guidelines page (and the other Google help pages) is compounded by a link rel=canonical tag that points to either the http or https version of the URL, depending on URL is requested.
It is important to make sure that the link rel=canonical tag always points to the intended canonical version of the page, so be careful when dynamically generating this element.
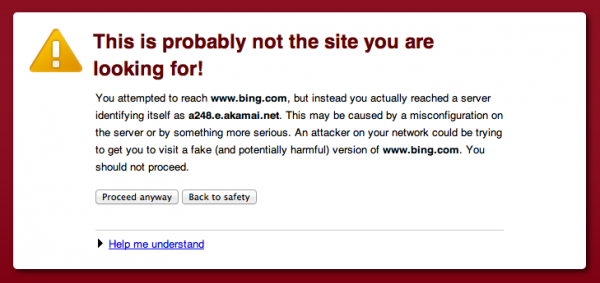
A request for https://www.bing.com/ results in a security warning (shown below) due to a mismatched SSL certificate. This is common for sites using Akamai for global server load balancing.
It even pops up for https://www.whitehouse.gov/. I’m not aware of a way to get around this issue, though I would love to talk with something at Akamai about this.
Use Robots.txt File To Prevent URLs From Being Crawled
Sites generally have different types of pages that they don’t want to have search engine’s index. This could be because these pages are unlikely to convert or aren’t a good experience for users to land on, like a “create an account” or “leave a comment” page. Or it could be because the page is not intended for Web browsers, like an XML response to an API call.
Bing’s search API calls, which are made to URLs starting with https://api.bing.com/ or https://api.bing.net/ can be crawled by spiders according to the robots.txt file. This can be devastating to crawl efficiency because search engines will continue to crawl these XML results even though they are useless to browsers.
A search on Google for [site:api.bing.net OR site:api.bing.com] currently returns about 260 results, but based on analysis I have done on clients’ Web access log files, it is many times more URLs than these have been crawled and rejected.
Use ALT Attributes In Images
Images should always be given alternate text via the ALT attribute (not TITLE or NAME as I have seen on some sites). This is good for accessibility issues like screen readers, and it provides additional context about a page to search engines.
Though many images on the pages that were checked had appropriate alternate text, I couldn’t help but notice that Duane Forrester’s image on his profile page didn’t. But he is in good company because Larry, Sergey, Eric, and the rest of the Google executive team don’t either.
Avoid Use Of Rel=Nofollow Attributes On Links To “sculpt PageRank”
A rel=nofollow attribute on a link tells search engines not to consider the link as part of its link graph. Occasionally, I will review a site that attempts to use this fact to control the way that PageRank “flows” through a site.
This technique is generally considered to be ineffective and actually counterproductive, and I always recommend against it. (There are still valid uses for rel=nofollow attributes on internal links, such as link to pages that are excluded from being crawled by robots.txt.)
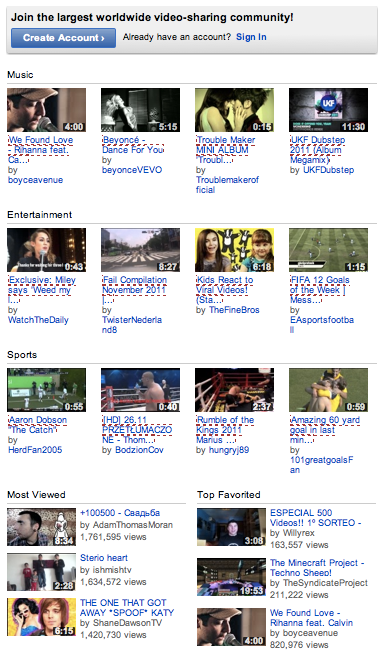
None of the search engine pages I checked were using rel=nofollow attributes in this way with the exception of the YouTube home page.
In the image below, nofollowed links are highlighted in red. Links to the most viewed and top favorited are being shown to search engines but general music, entertainment, and sports videos are not.
Return Response Codes Directly
A URL that doesn’t lead to a valid page should return a 404 (page not found) response code directly.
If an invalid URL is sent to Bing’s community blog site, it will redirect to a 404 page. Here is the chain:
- The URL https://www.bing.com/community/b/nopagehere.aspx returns a 302 (temporary) redirect to
- the URL https://www.bing.com/community/error-notfound.aspx?aspxerrorpath=/community/b/nopagehere.asp, which returns a 404 (page not found) response.
The recommended best practice would be for the first URL to return a 404 directly. If that isn’t possible, then the redirect should be changed to a 301 (permanent) redirect.
Yahoo’s corporate information pages do something interesting when they get an invalid URL.
A request to https://info.yahoo.com/center/us/yahoo/anypage.html, which is not a valid URL, correctly returns a 404 (page not found) response.
But the 404 page contains an old school meta refresh with a time of one second that redirects to https://info.yahoo.com/center/us/yahoo/.
A 301 redirect to this page is the recommended way to handle these types of invalid URLs.
Support If-Modified-Since/Last-Modified Conditional GETs
I am a big fan of using cache control headers to increase crawl efficiency and decrease page speed. (My article on this topic is here.)
I found it interesting that out of all the URLs that were checked only a few Google URLs supported If-Modified-Since requests and none of the URLs supported If-None-Match.
Periodically Check Your DNS Configuration
As part of a site review, I like to use on-line resources like https://intodns.com/ and https://robtex.com/ to check the DNS configuration.
DNS is an important part of technical SEO because if something breaks with DNS, then the site will go down and it isn’t going to get crawled. Fortunately, this rarely happens.
However, I have reviewed sites that had their crawling affected by DNS changes. And I have reviewed several large sites that had their DNS servers on the same subnet, essentially creating a single point of failure for their entire business.
As expected, all the search engines had no serious DNS issues. I was surprised to see that two of them had recursion enabled on their name servers because in some rare instances that can be a security risk.
My recommended best practice is to run these types of checks at least once a quarter.
Conclusion
These are a few of the issues that were found that I commonly see or think are important. There were others, but they were relatively minor or subtle things like short titles, duplicate/missing meta descriptions, missing headers, and too many static resources per page.
Normally, I would have access to Web access log files and webmaster tools, which allows our software to check a lot more things.
I hope this gives you some ideas for things to check on your own site. And I hope that when you find something that you realize that even the search engines have their own technical SEO issues from time to time.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author