The EU’s Right To Be Forgotten Is A Mess & How Google’s Making It Worse
“The road to hell is paved with good intentions,” the saying goes. There are plenty of good intentions with the EU’s Right To Be Forgotten mandate, as well as Google’s attempt to meet new obligations under it. Things are still going to hell regardless. Thanks to the new right, the EU has helped enable convicted […]

“The road to hell is paved with good intentions,” the saying goes. There are plenty of good intentions with the EU’s Right To Be Forgotten mandate, as well as Google’s attempt to meet new obligations under it. Things are still going to hell regardless.
Thanks to the new right, the EU has helped enable convicted pedophiles to ask that their actions be forgotten. It has ensured that businesses convicted of fraudulent activities can seek to have these hidden from the public. And it led this week to censorship of content from at least three major EU news publications.
Google, which initially objected to this new right, has now collaborated with it. Google has readily seized upon the role of censor, something that in other countries it has rejected with reluctance. Worse, Google’s attempts at transparency about its censorship have only lead to more confusion.
Below, I’ll go through some of the issues that we’ve seen develop since the right was established in May of this year.
The Censorship That’s Happening
Before getting into details, a refresher of what exactly Google is censoring. People can request that listings they object to be removed from showing on searches for their names — and only their names. If Google grants the request, the listings will continue to show for other types of searches that are not names. In particular:
- Removals only happen for searches on names, including searches that contain names along with other words. So — according to what Google has confirmed for Search Engine Land — if an “Emily White” objected to a story showing for her name, and Google granted a removal, the story would no longer appear for her name or for her name with other words such as “Emily White bankrupt”
- Removals only happen in the EU for country-specific versions of Google. For example a removal means content would not appear on Google UK for anyone going there worldwide.
- Removals do not happen for Google.com. However, listings at Google.com might often be different from EU-versions of Google for reason other than possible removals
- Listings continue to appear for other searches that aren’t names
To date, according to new stats Google gave the Guardian, Google says it has received more than 70,000 requests to remove about 275,000 individual listings, with most requests coming from France, Germany, the UK, Spain and Italy, in that order. Currently, about 1,000 requests per day are coming in.
The EU Court Of Justice Gave Too Broad A Ruling
Many people can sympathize with someone wanting their one-time mistake or a long-ago embarrassing action not showing up in the top search engine results for their name. That was core to the case that established this new right. A Spanish businessman was tired that a 1998 news article about the auction of his property to pay debts was showing up for his name. After so much time had passed, was it really that relevant?
The European Court of Justice felt that it wasn’t. It also felt that anyone in the EU should have the right to ask for material to be removed if they consider it to be “inaccurate, inadequate, irrelevant or excessive,” to cite the EU’s fact sheet about the ruling (PDF).
Those simple criteria belie some difficult decisions. How exactly does someone decide what’s inaccurate, inadequate, irrelevant or excessive? How do you make this determination balanced against another fundamental EU right, the public’s right for access to information.
The court provided none of this. It simply said that search engines should accept these requests and somehow make their own decisions. If also gave a provision that if a search engine rejected a request, this could be appealed to privacy regulators or the courts.
EU’s Censorship Guidelines: Just Like China’s
You know what other place imposes censorship restrictions on search engines without clear guidelines? China.
When Google was doing censorship in China, the government didn’t hand it a list of words to block. Google, like other companies, was just supposed to magically figure out what it should censor. As Steven Levy describes in his excellent book, In The Plex:
Though the government demanded censorship, it didn’t hand out a complete list of what wasn’t allowed. Following the law required self-censorship, with the implicit risk that if a company failed to block information that the Chinese government didn’t want its citizens to see, it could lose its license.
That was actually an interesting problem, and if nothing else, Googlers loved to solve such brain-twisters. In this case, they came up with an elegant solution. Google would exhaustively examine and probe the sites of competitors, such as China’s top search engine, Baidu, testing them with risky keywords, and see what they blocked.
As with China, the EU expects Google and other search engines to just somehow figure all this out, to make incredibly difficult judgment calls on a case-by-case basis — decisions that before this ruling might have involved judges or government bodies specifically charged with this type of work. And when Google gets it wrong, there’s an EU official ready to criticize, as has happened this week.
Google Didn’t Have To Collaborate
Make no mistake. Google didn’t want to have to to the type of censorship now being imposed upon it by the EU. It fought the initial case. Google CEO Larry Page recently spoke to a wish that the new right could have been implemented by the EU in a more practical manner.
But Google has been complying with the new right, and faster than its competitors. Bing and Yahoo, also subject to the removals mandate, have yet to remove anything.
Where Google has gone wrong, in my opinion, is in complying with the right by actually making decisions itself about whether something should be removed. It didn’t have to do that. It could be — and should be — rejecting every one of these requests as a judgment call that it shouldn’t be making.
I covered this in my initial Q&A about the Right To Be Forgotten, and I’ll revisit that now:
So Google will make these decisions?
If it was smart, it wouldn’t, except in very limited cases. Those cases might be the reasons where Google already makes such decisions, such as when social security numbers or credit card numbers are published online. Removing that type of information isn’t controversial. Making a judgment call on whether a story about someone convicted for having child porn is controversial.
But doesn’t Google have to make these decisions?
No, it does not. One strategy would be for Google (or any search engine) to decide not to decide. Any request it receives, it could respond that unless the request relates to some very specific situations, it will be rejected because Google doesn’t believe it can fairly judge between the right of privacy and the right of free speech. Instead, Google could recommend that someone go to a particular country’s privacy agency for a ruling and let that agency make the call.
Google, from my reading of the court ruling and its overview press release, is free to reject any request without penalty. If there’s rejection, people can then appeal — and a regulatory body can make the final decision.
Rather than do that, Google has put together a process of making judgments that we know little about. I’ve asked the company several times for how the process works. It won’t open up. Nor am I likely the only one who’s been asking and not getting answers.
Charles Arthur at the Guardian notes that he understands Google has a team of paralegals trying to make decisions. My understanding is that Google also may have drafted up some general guidelines about what is and isn’t acceptable for removal. There’s also an advisory group that was formed involving Google execs and outsiders, at the end of May. If it has made any decisions, none of that has been made public, that I’ve seen.
And Now Google’s Judgment Calls Are Blowing Up
That leads to this week’s news — that three UK newspapers got notices that some of their content would no longer show up for certain searches. Which searches? That’s not said, which in turn has lead into confusion about what’s being censored.
I’ll get back to that. The most important point is that Google put itself in the position of censoring the press. And it is censorship. Censorship is when you remove content. Yes, the EU has imposed this censorship on Google, but it was Google that decided to censor these publications from its results.
And yes, it is censorship even if the articles themselves were not removed entirely from Google or available to be easily found for other types of searches. Again, censorship is when you remove content. If it wasn’t censorship, then Google wouldn’t be disclosing that it happens with new notices that appear for some searches.
You can also expect this is going to get worse. Soon after the BBC and the Guardian reported getting notices about the removals, the Daily Mail was prompted to check if it had gotten one. Almost certainly, other press publications in the EU have also received them. They just haven’t bothered to log into their Google Webmaster Center consoles to discover the notices yet.
Just wait. Some of these removals are going to deal with stories about violent criminals or pedophiles. When that happens, and it will, you can expect to see some headlines like “Google hides pedophiles” appear.
Google’s Notices Are Confusing Publishers
Soon after the new Right To Be Forgotten came into being, Google said that it would let publishers know if they had content removed. The idea behind this was to be transparent. To a degree, it has helped. Without this, news of Google’s press censorship would have never happened.
The notices only say that pages were removed for some searches, not what the exact searches were. That lead directly to Robert Peston, the BBC’s economics editor, making an incorrect assumption that his story had been dropped for all searches. As Peston wrote on Wednesday (I’ve bolded the key parts):
This morning the BBC received the following notification from Google:
Notice of removal from Google Search: we regret to inform you that we are no longer able to show the following pages from your website in response to certain searches on European versions of Google: https://www.bbc.co.uk/blogs/legacy/thereporters/ robertpeston/2007/10/merrills_mess.html
What it means is that a blog I wrote in 2007 will no longer be findable when searching on Google in Europe.
Peston was wrong. It didn’t mean that his blog post wasn’t findable when searching on Google in Europe.
Speaking on BBC Radio 4 today, Peston said (in a segment that begins 2:10 in):
When you get sent these notifications by Google, they’re very general. It was, you know, an inevitable reaction by me, when i got the email from Google saying that my particular story was no longer going to be searchable, to think it had been cast out into oblivion, because that is what the email absolutely unambiguously implied.
Part of me thinks Peston perhaps could have read that notice a bit more closely before making the assumption that he did, because as the bold parts show, it doesn’t “absolutely unambiguously” imply his story was going to be dropped entirely.
But watching him react, as well reading a story from the Guardian that illustrated stories supposedly being dropped for a particular name when they had not, it’s clear the notices need to improve. “Certain searches” is much broader than saying “for a particular name.” The link these notices include to a FAQ page provides no helpful explanation of what’s going on.
Good intentions; bad delivery, and Google ends up with a mess this week.
Google’s Notices Make Everyone “Guilty” Of Trying To Hide
Google has long disclosed when it is required to do censorship by posting notices at the bottom of its search results, when material has been removed. So soon after the Right To Be Forgotten ruling, it declared it would have similar notices when material was removed under that.
The idea seemed to be that these notices would only appear when material was really removed. But if Google did that, then it would be pretty easy for anyone with an unusual name to be publicly exposed as having gotten something forgotten. The EU regulatory bodies, in particular, seemed concerned about that.
As a result, Google is making the notices show up for searches on any names, regardless of whether there has been a removal or not. Our story below explains more:
This is already leading to some terrible conclusions. For example, after the BBC’s Peston reported about his story being removed, some people assumed that the person who made that request must have been the subject of the story, former Merrill Lynch chairman Stan O’Neal. To check this, they searched on his name, where this notice appeared (as it still does) at the bottom of the results:
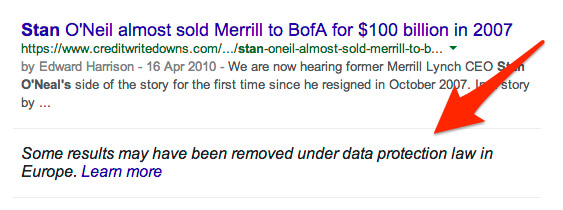
That notice is proof of nothing. It may appear for any name search, regardless if a removal actually happened for that name. As it turns out, the BBC story was removed, as Google explained in the aforementioned Radio 4 program, because someone who commented on the story decided that the comment violated their privacy and thus was subject to a Right To Be Forgotten removal — which Google granted.
Comparing Googles Is No Guide
Adding to the confusion is the attempt by some to look at Google.com as a way to compare what may have been removed from an EU-version of Google.
This is far from foolproof. Any country-specific version of Google will have different results than Google.com because of geographic adjustments. In short, Google uses a system to try and show the most relevant results based on someone’s geography. Heck, even two different people in nearby cities in the US going to Google.com might get different results.
Consider this side-by-side search for a name I picked at random, with Google.com on the left and Google UK on the right (click to enlarge):
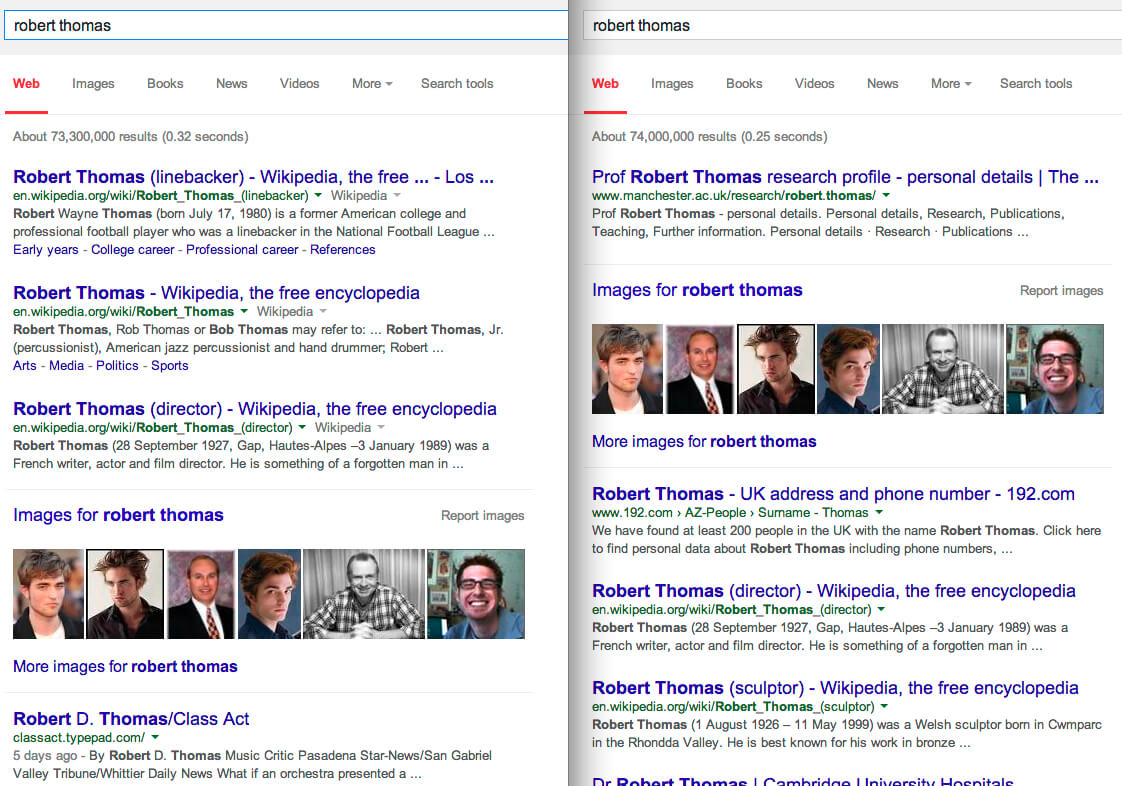
These are nothing alike. And that’s not because the UK version has had some type of Right To Be Forgotten removals that have changed all the results. It’s part of Google’s regular regionalization.
If you understand search engines well, you get this. Many people — including many journalists — do not. As a result, you can expect to see more attempts to somehow check results in the EU against those in the US to prove what’s been removed. In reality, many of these attempt might prove nothing at all.
Google’s Reversals Make System Seem Worse
As it turns out, Google now has reversed its decision to remove apparently three of the links that had been pulled, relating to a story about former Scottish football referee Dougie McDonald, the Guardian reports, as does Reuters.
I haven’t been able to get Google to confirm this directly to me with more specifics, and Google’s director of communications in Europe, Peter Barron, didn’t address this at all in the Radio 4 interview I’ve mentioned (nor did the interviewer raise it, oddly). But with both the Guardian and Reuters independently saying it, that seems to be the case.
But why were these removed? What mistake was made to pull them in the first place? What’s preventing future mistakes like this from happening. It’s just silence, from Google — and that doesn’t instill faith in the system where it’s continuing to pull material.
It’s Not Part Of Google’s Master Plan To Stop EU Censorship
I’ve seen several articles suggesting that this week’s events have been part of some plan by Google to raise attention about the EU censorship it is required to do, as a means of putting pressure on getting it stopped. In the Radio 4 interview, the interviewer couldn’t seem to get enough of trying to advance this theory.
I doubt it. I highly doubt it. And here’s how I’ll debunk it.
First, if Google wanted to gum up the works, it could have rejected all requests, as I explained above. That would have put huge pressure on privacy regulators to deal with this situation, which in turn would have put huge pressure on various EU governments on how they really wanted to enforce this court mandate. Google didn’t do that.
Second, it’s not like Google did anything special to only have these notices hit news publishers. Any publisher and any owner of a web site might get them — and are getting them — as we reported this week:
That news publishers were hit by this is a byproduct of Google’s compliance with the ruling, not some type of attempt by Google to single out news publishers. This is important, so I’ll put it in bold: this was not targeted only at media outlets.
Third, Google is dealing with thousands of these requests. Which is more reasonable — that it carefully selected a few examples of articles at news publications that it could censor, in hopes that the right technical people get notices to pass on to editors? That’s one of the suggestions that Mathew Ingram at GigaOm summarizes. Far more reasonable is that some paralegal pushing through hundreds of requests per day just isn’t spending that much time debating them.
Fourth, far from fighting this law, Google is doing almost unprecedented reaction to support it. Sure, there was no way for it to appeal the process. But it could have delayed things more, asking for time to meet with regulators to better understand how to implement it — or for its advisory comittee to do public or semi-public discussions of what should be pulled or not.
Google didn’t do that. It rapidly rolled out a form, followed by fast removals. And I suspect this is in large part because Google, which already has struggled with privacy issues in the EU and is still awaiting an anti-trust ruling, doesn’t want to be seen as dragging its feet at all.
In fact, I suspect that inside Google, there’s absolute horror that EU officials might think that it’s somehow trying to be obstinate about removals. That’s purely my speculation, not based on any source but instead looking at how quickly Google reacted to comply.
Time For A Pause? Time For More Transparency?
What’s Google have to say about the latest developments? “It’s a learning process,” said Google’s Barron, in the Radio 4 interview, echoing the standard statement the company sent me:
We have recently started taking action on the removals requests we’ve received after the European Court of Justice decision. This is a new and evolving process for us. We’ll continue to listen to feedback and will also work with data protection authorities and others as we comply with the ruling.
My feedback would be what I said before: don’t be the arbiter of what to censor. Google’s not well qualified to do that, and it’s attempts to do so will only continue to generate controversy as we’ve seen this week. Reject requests under the reasoning that Google isn’t the competent authority to judge, then let the privacy regulators make the decisions.
Alternatively, perhaps the system needs to go on hold. The initial flood of requests has turned into a trickle. Rushing this isn’t necessary and likely only going to lead to more mistakes.
At the very least, stop talking the transparency talk and start walking the transparency walk. Provide a lot more information about how requests are being processed, along with some general stats about the types being handled, granted, whether they involved news publications and so on.
Postscript: This story was updated to note that Google has confirmed that removals happen both for searches on names and those names plus other words.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author