How To Improve Crawl Efficiency With Cache Control Headers
Way back at the end of the last century, I worked for a company called Inktomi. Most people remember Inktomi as a search engine, but it had several other divisions. One of these divisions (the one I worked for) sold networking software, including a proxy-cache called Traffic Server. It seems weird now, but Inktomi made […]
Way back at the end of the last century, I worked for a company called Inktomi. Most people remember Inktomi as a search engine, but it had several other divisions. One of these divisions (the one I worked for) sold networking software, including a proxy-cache called Traffic Server.
It seems weird now, but Inktomi made more money from Traffic Server than it did from the search engine. Such were the economics of the pre-Google Internet. It was a great business until 1) bandwidth got really, really cheap and 2) almost all of the customers went out of business in late 2000/early 2001. (Most of Inktomi was acquired by Yahoo! in 2002, and Traffic Server was released as an open source project in 2009.)
Because of my work with proxy caches, I’m always surprised when I do a technical review of a site and find that it has been configured not to be cached. When optimizing a website for crawling, it’s helpful to think of a search engine crawler as a web proxy cache that is trying to prefetch the website.
One quick note: When I talk about a “cached” page, I’m not referring to the “Cached” link in Google or Bing. I’m referring to a temporarily stored version of a page in a search engine, proxy-cache, or web browser.
As an example of a typical cache-unfriendly website, here are the HTTP response headers from my site, which is running my ISP’s default Apache install and WordPress more or less out of the box:
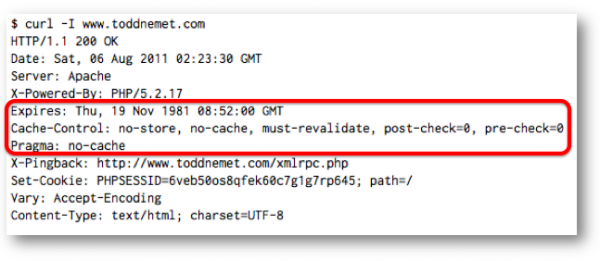
The three lines circled in red are HTTP-ese for “Don’t cache this ever, under any circumstances.”
A little more detail about these headers:
- Expires: indicates how long a proxy-cache or browser can consider a document “fresh” and not have to go back and get it. By setting this to a date two decades ago, the server is indicating that it should never be considered fresh.
- Cache-control: is used to explicitly tell proxy-caches or browsers information about the cacheability of the document. “no-store” and “no-cache” tell it not to cache the document. “must-revalidate” means that the cache should never serve the document without checking with the server first. “post-check” and “pre-check” are IE-specific settings that tell IE to always retreive the document from the server.
- Pragma: is an HTTP request header, so it has no meaning in this instance.
Cache Control Headers & Technical SEO
So what do cache control headers have to do with technical SEO? They matter in two ways:
- They help search engines crawl sites more efficiently (because they don’t have to download the same content over and over unnecessarily).
- They increase the page speed and improve user experience for most visitors to your site. It can even potentially improve the experience for first-time visitors.
In other words, by adding a few lines to your Web server configuration to support caching, it’s possible to have more of your site crawled by search engines while also speeding up your site for users.
Let’s look at crawl efficiency first.
Crawl Efficiency
Only two pairs of cache control headers matter for search engine crawling. These types of requests are called “conditional GETs” because the response to a GET will be different depending on whether the page has changed or not.
Searchengineland.com happens to support both methods, so I will be using it in the examples below.
Last-Modified/If-Modified-Since
This is the most common and widely-supported conditional GET. It is supported by both Google’s and Bing’s crawlers (and all browsers and proxy caches that I’m aware of).
It works like this. The first time a document is requested a Last-Modified: HTTP header is returned indicating the date that it was modified.
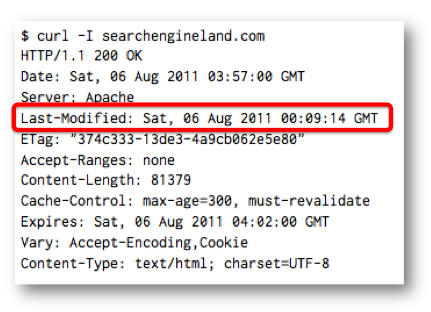
The next time the document is requested, Googlebot or Bingbot will add a If-Modified-Since: header to the request that contains the Last-Modified date that it received. (In the examples below, I’m using curl and the -H option to send these HTTP headers.)
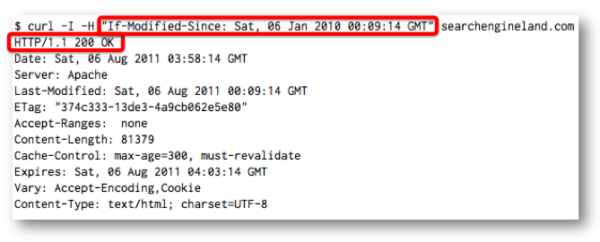
If the document hasn’t been modified since the If-Modified-Since date, then the server will return a 304 Page Not Modified response code and no document. The client, whether it is Googlebot, Bingbot, or a browser, will use the version that it requested previously.

If the document has been modified since the If-Modified-Since date, then the server returns a 200 OK response along with the document as if it were responding to a request without an If-Modified-Since header.
ETag/If-None-Match
If-None-Match requests work in a similar way. The first time a document is requested, an Etag: header is returned. The ETag is generally a hash of several file attributes.
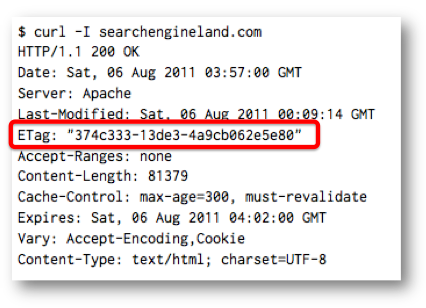
The second request includes an If-None-Match: header containing that ETag value. If this value matches the ETag that would have been returned, the server returns a 304 Page Not Modified header.
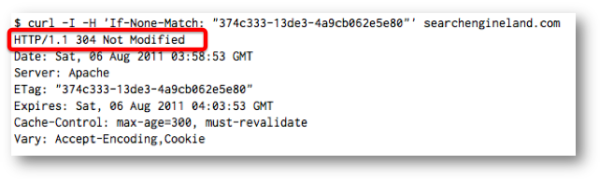
If the ETag doesn’t match, then a normal 200 OK response is returned.

ETag/If-None-Match is definitely supported by Bing, but it’s unclear whether Google supports it. Based on the analysis of log files that I have done, I’m pretty sure that Googlebot web requests don’t support it. (It’s possible that other Google crawlers support it, though. I’m still researching this, and I’ll post a follow up article if/when I get more information.)
One common problem with ETag/If-None-Match support pops up with websites that load-balance between different back end servers. Many times, the ETag is generated from something that varies from server to server, such as the file’s inode, which means that the ETag will be different for each back end server.
This greatly reduces the cacheability of load-balanced websites because the odds of requesting the same document from the same server decreases in proportion to the number of back end servers.
In general, I recommend implementing Last-Modified/If-Modified-Since instead of ETag/If-None-Match because it is supported more widely and has fewer problems associated with it.
When To Use These Conditional GETs
Conditional GETs should be implemented on any static Web resources, including HTML pages, XML sitemaps, image files, external JavaScript files, and external CSS files.
- For Apache, the mod_cache module should be installed and configured. If the server still isn’t supporting conditional GETs check for a CacheDisable line in the httpd.conf or a .htaccess file somewhere.
- For IIS7, caching is controlled by the <caching> element in the site configuration file. I’m not sure how to enable it in IIS6, though it appears to be enabled by default.
For dynamic, programmatically generated files, the HTTP headers associated with conditional GETs need to be sent from the page code. You need to do some back of the envelope calculations on two factors to determine if this is worth it.
- Does it take as many resources (for example, calls to back-end databases) to determine whether the page has changed versus generating the file itself?
- Does the page change often compared to how often the page is crawled by search engines?
If the answer to both questions is yes, then it may not be worth implementing support for conditional GETs in your code for dynamic pages.
Page Speed
I also recommend setting expiry times for static resources that don’t change often, such as images, JavaScript files, CSS files, etc.
This allows browsers to store these resources and reuse them on other pages on your site without having to unnecessarily download them from the Web server.
Also, it is likely that these resources will get stored in a proxy cache somewhere in the Internet where it will be served more quickly to other users, even on their first visit.
There are two ways to set an expiry time using HTTP cache control headers.
- Expires: <date>, which indicates the date before which a resource can be stored.
- Cache-control: max-age=<seconds>, which indicates the number of seconds that a resource can be stored.
The expiry time can be set up to a maximum of one year, according to the HTTP spec. I recommend setting it at a minimum of several months.
Configuring Expiry Time
For Apache, it requires installing the mod_expires tag and creating some ExpiresDefault or ExpiresByType lines. Cache-control also requires mod_headers.
IIS7 can be configured through IIS Manager or some command line tools. See this link for more details.
For resources that are generated dynamically, these headers can be added programmatically like any other header. Just make sure that the Expires: date is in the right format or it likely will be ignored.
Other Resources
Below are some additional resources relate to caching, since this article only scratches the surface of the HTTP cache control protocol. I recommend checking out the links below to learn more about it.
Testing cache control headers
- Redbot.org, written by “mnot“, is the best cache-checking tool I am aware of. I use it all the time when assessing sites.
- Microsoft has a very useful tool for looking at headers that is available here.
I’m also a big fan of using curl -I from the command line to look at headers directory.
Advanced reading
- Google’s page speed article on leveraging caching.
- Yahoo’s best practices article for speeding up a web site contains some information about caching (click on the “Server” category):[[[]]]
- Bing outlines their support for conditional GETs and includes some helpful links here.
- Mnot has an excellent, thought slightly dated, overview of caching that is very useful.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author