9 easy-to-miss crawl reports in Screaming Frog and DeepCrawl that pack serious SEO punch
Troubleshooting SEO issues on a site or performing a technical SEO audit? If so, columnist Glenn Gabe recommends some powerful but little-known reports in two popular crawling tools.

I’ve written extensively in the past about using various crawl tools to help with SEO. The reason is simple. Based on the number of audits I’ve completed, I’d say you never truly know what’s going on with a large and complex site until you crawl it.
My two favorite tools for crawling websites are DeepCrawl (where I’m on the customer advisory board) and Screaming Frog. Both are excellent tools packed with valuable functionality.
I typically use DeepCrawl for enterprise-level crawls, while I use Screaming Frog on small to medium-sized websites. I also use both together, as there are times an enterprise crawl will yield findings that warrant a smaller, surgical crawl. So to me, the sum of combining DeepCrawl with Screaming Frog is greater than its parts: 1+1=3.
Both tools provide a wealth of data, but I’ve found that there are some powerful and important reports that lie in the shadows. In this post, I’m going to quickly cover nine easy-to-miss crawl reports that pack serious SEO punch. And two of those reports are part of DeepCrawl 2.0, which should be released soon (within the next few weeks). Let’s begin.
Hidden Frog: easy to miss, yet powerful, Screaming Frog reports
Redirect chains
Most SEOs know that you need to redirect old URLs to their newer counterparts when going through a website redesign or CMS migration. But I’ve seen too many people check the initial 301 redirect and stop their research. DON’T MAKE THAT MISTAKE.
A 301 can lead to a 200 header response code, which is great. But it can also lead to a 404, which isn’t great. Or it can lead to another 301, or another five 301s. Or maybe it leads to a 500 (application error). Just because a URL 301 redirects doesn’t mean it properly resolves after the redirect. That’s where the Redirect Chains report in Screaming Frog shines.
Make sure you check the box for “Always Follow Redirects” in the settings, and then crawl those old URLs (the ones that need to redirect).
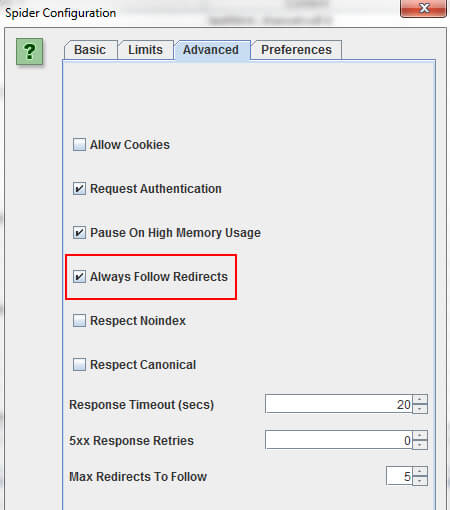
Screaming Frog will follow the redirects, then provide the full path from initial redirect to 200, 301, 302, 404, 500 and so on. To export the report, you must click “Reports” in the main menu, and then select Redirect Chains.
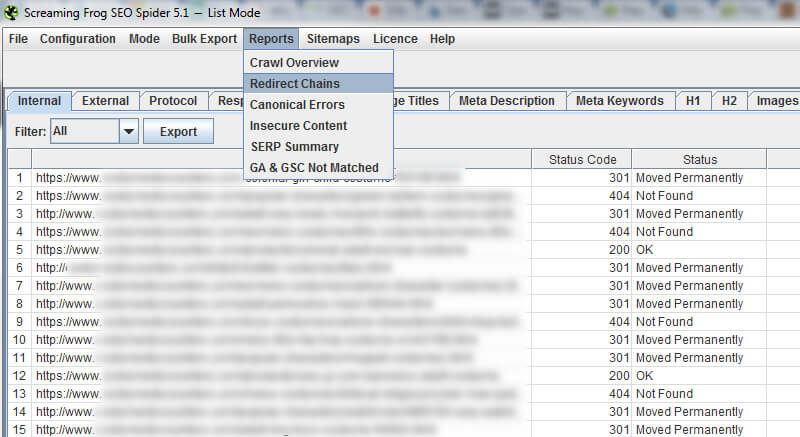
Once in Excel, you will see the original URL that redirected and then how the URL you are redirecting to resolves. And if that second URL redirects, you can follow the redirect chain. Again, this is critically important to know. If your 301s lead to 404s, then you can lose rankings and traffic from the pages that used to rank well. Not good, to say the least.

Insecure content
Many sites are moving to HTTPS now that Google is putting the pressure on. When you move to HTTPS, there are several items to check to ensure the migration is being handled properly. One of those items is ensuring you don’t run into a content mismatch problem. That’s when you deliver insecure elements over secure URLs.
If you do, you will see an error like this:
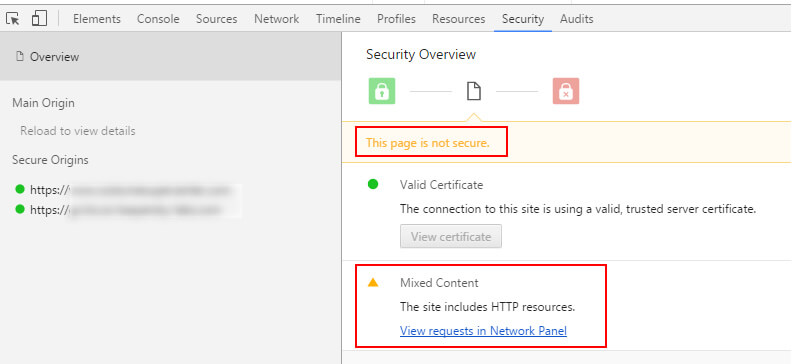
Many people don’t know this, but Screaming Frog has a report built in that shows insecure content. Once again, head to the “Reports” drop-down in the main menu and select “Insecure Content.” The report will list the source of the insecure content and which HTTPS URLs it’s being delivered to.
Once you run the report after migrating to HTTPS, you can export it and send the data to your developers.

Canonical errors
The canonical URL tag is a powerful way to make sure the search engines understand your preferred URLs (the proper pages that should be indexed.) This can help cut down on duplicate content, and it can consolidate indexing properties from across multiple URLs to the canonical one.
But the canonical URL tag is also a great way to destroy SEO with one line of code. I’ve seen many botched implementations of the canonical tag over the years. And in a worst-case scenario, it can cause massive SEO problems — for example, canonicalizing an entire site to the home page or pointing rel canonical to pages that 404, redirect to 404s and so on.
There are many ways to botch rel canonical, but the problem for SEOs is that it lies beneath the surface. The tag is invisible to the naked eye, which is makes it very, very dangerous. So Screaming Frog provides a “Canonical Errors” report that can help you surface those problems quickly. Just head to the “Reports” menu again, and select “Canonical Errors.”
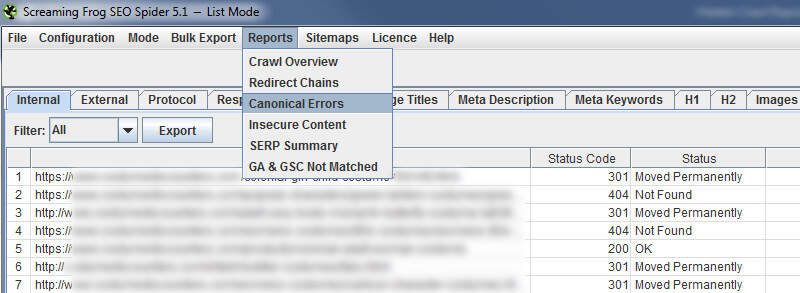
After exporting the report, you will see each canonical error that Screaming Frog picked up during the crawl. You might be shocked at what you find. The good news is that you can send the report to your dev team so they can hunt down why those errors are happening and make the necessary changes to fix the core problem.
Going deeper with DeepCrawl
Pagination: First Pages
Pagination is common across large-scale sites, especially e-commerce sites that contain categories filled with many products.
But pagination is also a confusing subject for many SEOs, which often yields an improper setup from a technical SEO standpoint. From noindexing component pages to mixing noindex and rel next/prev tags to other problematic combinations, you can often send Google very strange signals about your pagination.
DeepCrawl 1.9 (the current version) contains some extremely valuable reports that can help you hunt down those problems. For example, when you’re crawling a large and complex site, pagination can sometimes lie deep in a site (beyond the obvious areas). The “First Pages” report will show you the first pages in a pagination (URLs that contain a rel= “next” tag). This can help you track down the starting point for many instances of pagination on a large-scale website.
You’ll find the set of pagination reports in DeepCrawl by clicking the “Content” tab and then scrolling to the bottom of the Content Report. Here is a screen shot of the First Pages report.

Once you find pagination via the First Pages report, you can dig deeper and find out if pagination has been set up properly. Are the component pages linked together? Is rel next/prev being used properly? How about rel canonical? Are the component pages being noindexed? Are they being canonicalized to the first page?
You can find out the answers to all these questions and more. But again, you need to find all instances of pagination first. That’s where this report helps.
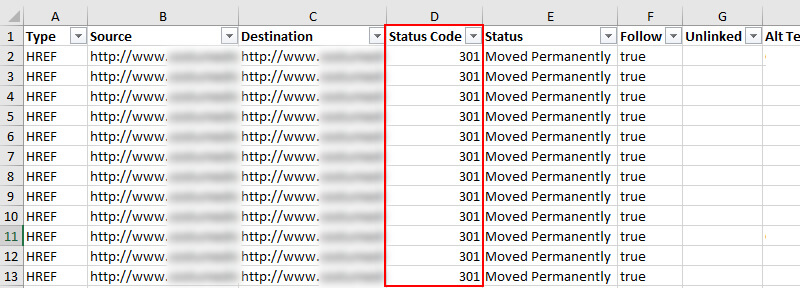
Pagination: Unlinked Paginated Pages
The next piece of the puzzle is tracking down component pages that are included in rel next/prev tags but aren’t linked together on the site. Finding those pages can help surface technical SEO problems. For example, URLs that contain a rel next tag should be linking to the next component page in the set. Pages with both rel=”next” and rel=”prev” should be linking to both the previous and next pages. So on and so forth.
If you find rel next/prev tags without the URLs being linked together, that could signal deeper problems. Maybe there’s legacy code on the site that should have been removed. Maybe there should be links to the component pages, but they aren’t showing up in the code or on the page. Maybe there’s not a “next page,” but there’s still a rel=”next” tag, which points to a 404. Again, you never know what you’re going to find until you dig in.
Max Redirections
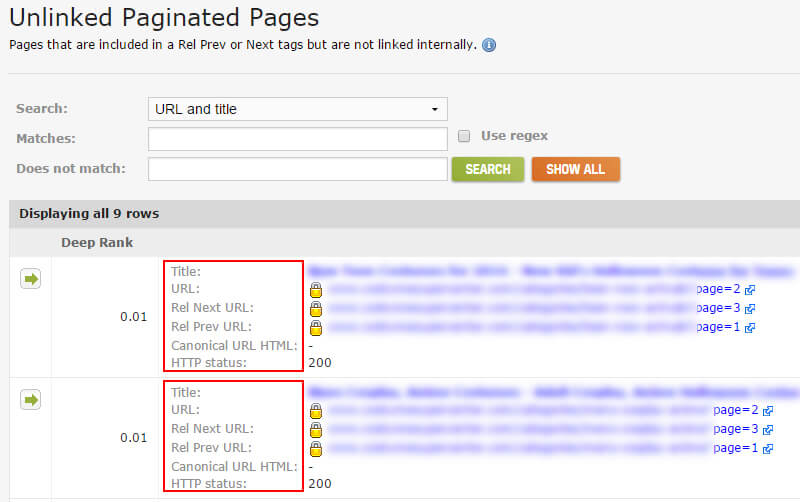
I mentioned earlier that some redirects daisy-chain to even more redirects. And when that happens multiple times, it can potentially cause problems, SEO-wise. Remember, you should redirect once to the destination page, if possible. As Google’s John Mueller explained, if Google sees more than five redirects, it can stop following, and it might try again during the next crawl.
DeepCrawl provides a “Max Redirections” report that provides all URLs that redirect more than four times. It’s a great way to easily view and analyze those URLs. And of course, you can jump to fix those redirect chains quickly. You can find the Max Redirections report in DeepCrawl by clicking the “Validation” tab and scrolling to the section labeled “Other.”
Pages with hreflang tags (and without)
Hreflang is a great way to tie multiple language URLs together. Google can then supply the correct version of the page in the SERPs based on the language of the user.
But based on my experience, I’ve seen a boatload of hreflang errors during audits. For example, you must include return tags on pages referenced by other pages in the cluster. So if your “en” page references your “es” page, then then “es” page must also reference the “en” page. Here’s an example of “no return tags” errors showing up in Google Search Console.

In addition, there are other ways to botch hreflang tags, like providing incorrect language and country codes, incorrectly using x-default and so on. Therefore, you definitely want to know all of the pages that contain hreflang so you can dig deeper to understand if those tags are set up properly.
In DeepCrawl, there are several reports for analyzing hreflang. The most basic, yet still powerful, is the “Pages with hreflang Tags” report. It will list all pages that contain hreflang tags, provide all of the tags found on each page and indicate whether they are being supplied in the HTML of the page, via XML sitemaps, or delivered via the response header. You can find the set of hreflang reports in DeepCrawl by clicking the “Validation” tab and scrolling to the section labeled “Other.”
Remember, on-page tags are easier to pick up since they are in the code, but when hreflang is delivered via the response header or in sitemaps, you won’t know that by simply looking at the page. DeepCrawl’s hreflang report will surface this information for you.

Bonus: DeepCrawl 2.0 launching soon
I mentioned earlier that I’m part of the customer advisory board for DeepCrawl. Well, I’ve been testing the newest version in beta, version 2.0, and it’s nearing launch. As part of version 2.0, there are some new and incredibly valuable reports. I’ll touch on two of them below. Remember, you can’t access these reports in the current version (1.9), but you will be able to in 2.0, which should launch within the next few weeks.
Disallowed JS/CSS
In order for Googlebot to accurately render a page, it needs to retrieve the necessary resources (like CSS and JavaScript). If those resources are blocked by robots.txt, then Google cannot accurately render the page like a typical browser would. Google is on record explaining that blocking resources can “harm the indexing of your pages.” Not good, to say the least.
Using Fetch as Google in Google Search Console and selecting “fetch and render” is a great way to check how Googlebot can render individual pages. But what about checking 50,000 pages, 500,000 pages, 1,000,000 pages or more? Well, there is a new report in DeepCrawl 2.0 that surfaces disallowed resources like JavaScript and CSS, and it’s a great way to quickly see which resources on a site are being blocked. Then you can rectify those problems quickly.
HTTP resources on HTTPS
There are many sites taking the plunge and moving to HTTPS. But there are also many sites incorrectly serving HTTP content over HTTPS (which will result in a content mismatch error). DeepCrawl 2.0 enables you to surface that problem across a large-scale crawl. Once you determine the HTTP resources being delivered on HTTPS, you can work with your developers to rectify the problem.

Next steps: Make sure you check these easy-to-miss crawl reports
Okay, now you have nine additional reports to analyze beyond the ones you might have known about (in both Screaming Frog and DeepCrawl). The reports I covered in this post provide a wealth of important data that can help you surface technical SEO problems. And those problems might be inhibiting your performance in organic search. So crawl away, and then check those reports! You never know what you are going to find.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author