Calling All Information Architects! Get With The SEO Program
Many SEO professionals try to understand information architecture (IA). Do information architects try to understand SEO? Here are some of my beefs with information architects.
In my previous column, Search Engine Optimization (SEO) Myths About Information Architecture, my colleagues and I pointed out some frustrations with SEO professionals’ concept of information architecture (IA).
For example, information architecture is not about PageRank sculpting. It’s about labeling and organizing content on a website to support usability and findability.
A successful site architecture addresses both information architecture and technical architecture. I often feel that search engine optimizers forget the searcher part of SEO. Hence, their understanding of information architecture is limited to querying behaviors only.
However, I also feel that information architects too quickly and too easily dismiss SEO for a number of reasons. Maybe they don’t understand SEO, being quick to succumb to the “snake-oil” stereotype. Or maybe they don’t have some of the technical knowledge that is a very much a part of successful SEO.
Many of my SEO colleagues work to understand and implement search-friendly information architectures. Personally? I believe it is long past due for information architects to get with the SEO program.
Here are some of my biggest beefs with many information architects.
Keywords Are Important — So Use Them Often & Use Them Well
When I listen to my information architect colleagues, I hear plenty of conversations about using the users’ language and understanding their mental models. I understand that during open and closed card-sort tests that one must never guide test participants with predetermined words to support ones personal mental model. I really do get that.
But I also see information architects deliberately remove important keywords from websites to support their version of findability. They believe redundancy is bad when some redundancy supports findability and the validation of information scent.
Part of the labeling process is establishing and maintaining aboutness with keywords. They belong on web pages, graphic images, video files, and so forth. Keywords should be implemented consistently and repeatedly when necessary.
Believe it or not, information architects and SEO professionals often face the same issues, as my colleague Alan Perkins, Managing Director of SilverDisc Limited, points out:
“I guess the biggest problem I come across with information architects is the same problem that SEOs come across with organisations generally – that is, they tend to have an internal perspective on the information which differs from the external perspective held by a website’s visitors. This is particularly true of in-house information architects. To give an example, they might use a label of ‘Polypropelene Drinking Vessels’ where the target market would use ‘Plastic Cups.’ It’s essential to architect using the words and phrases that your customers use if you wish to maximise SEO, conversion rates and profit. Too often, information architects will use in-house and industry jargon which cripples these three.”
Keyword research is an essential part of an SEO professional’s job. It should be a part of an information architect’s job as well. I am certainly not saying that an information architecture should be created based on keyword research data, but I am saying that I am a better information architect because keyword research tools are good source of web searcher data. Perkins continues:
“Information architects don’t think about keywords at all. They carefully work out home pages, category pages, product/information pages and so on, but when asked ‘If somebody was to search Google for x (where x is a term we’re highly relevant for and would like to rank for), which single page from this website would you like them to see in the Google search results?’, often you’ll see the jaw drop. Because there isn’t a page for x. There are hundreds of pages for x, smeared across the whole site. And not one of those pages, in and of itself, could possibly rank on Google for x.”
Which brings me to my next beef….
Treat Most Web Pages As A Point Of Entry
Search engine optimizers have to address how users/searchers arrive at a website via web search engine listings and links from external, third party resources.
Information architects? Their concern is architecting a site with the home page as the main point of reference. The problem? That single point of entry does not address searchers’ needs and goals once they arrive on a site.
The content, labels, and navigation systems provide information to search engines and third-party websites. Is that information scent and aboutness validated after a user/searcher clicks on those links?

Here’s a simple example. With an e-commerce site:
- A niche website, such as a shopping directory, often links to the home page.
- If a web searcher wants to view a list of items, he/she typically types in the plural form of a keyword. So the searcher expects to be delivered to a category page, which features a list of items. Commercial web search engines try to accommodate this type of informational query and feature a category page in search listings.
- A blogger might link to a specific product he/she likes.
Search engine optimizers do not want to break a successful information architecture. But we do want information architects to realize that every URL that is in a search engine’s index is a potential point of entry.
Information architects need to recognize and validate this viewpoint and context in wireframes, prototypes, organization, and labels. If you don’t accommodate the searcher viewpoint? You are limiting access to desired content, which brings me to….
Limiting Access To Desired Content
The most important page on a website isn’t typically a home page. With a hierarchical structure, the home page is emphasized and treated as the most important page. In other words, the parent-child links are emphasized.
The category-subcategory-content relationships among the content are deemed the most important links.
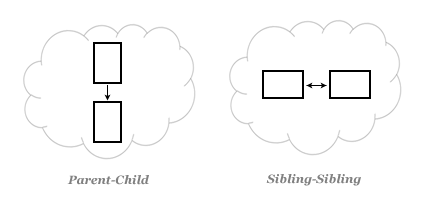
In reality, the hierarchical (vertical) links are not the only way that users/searchers discover and locate desired content. They also look at related content that isn’t necessarily grouped as a hierarchy.
In other words, the sibling-sibling (horizontal) relationships also accommodate findability. Information architects need to use both types of links on web pages to establish aboutness, validate information scent, and increase findability via both browsing and searching.
However, there is a flip side to limiting access to content. Sometimes, there is too much access to content. Too much access? How can a website deliver too much access?
Faceted Classification & Duplicate Content Delivery
According to Wikipedia, a faceted classification system allows the assignment of multiple classifications to an object, enabling the classifications to be ordered in multiple ways, rather than in a single, pre-determined, taxonomic (hierarchical) order. A single, top-down taxonomy can make content more difficult to find via both browsing and searching.
A single, top-down taxonomy can make content more difficult to find via both browsing and searching because users (and search engine spiders) must travel a specific path in order to access content. A faceted classification system, in theory, can make desired more findable because multiple paths to content are available.
Furthermore, faceted classification systems are favored among many web developers because they are scalable and do not require much face-to-face interaction with users.
Sounds like a great, simple solution to online information architecture, huh?
Not so simple. Instead of limiting access to desired content, faceted classification creates too much access to desired content. The main reason that web developers and information architects cannot visualize this is that they do not understand duplicate content delivery according to the commercial web search engines.
With a faceted navigation system, boilerplate elements are the same. The host name resolution is the same. The linkage properties are the same. The shingles are the same. And if information architects, SEO professionals, and web developers don’t know what these terms (host name resolution, linkage properties, shingles) mean? Guess what? You do not understand duplicate content delivery from a web searcher and a search engine perspective.
I have worked with faceted classification systems for many years and have seen searcher reactions to this type of navigation system. Faceted navigation is fine once users/searchers arrive at your site. They are not “fine” when web searchers see the same product listing over and over and over again in search engine results pages (SERPS).
Web searchers don’t only become annoyed with the website that appears to be getting an endless amount of search listings — they also become annoyed with the search engine delivering the repetitive search results.
Part of an information architect’s job is to prioritize. Well, information architects should prioritize the content that is to be delivered to the commercial web search engines.
How many information architects know how to do that? How many information architects care to do that? Without knowledge of web SEO, information architects (and web developers) do not realize how their decisions lead to a negative searcher experience.
Information architects — it’s long past due that you know and understand SEO. Kim Krause-Berg, founder of Cre8pc and Search Marketing/UX Manager for LiBeck Integrated Marketing, agrees with me.
“IAs are aware that SEO is a practice that includes information architecture, but I’m not seeing an understanding, or acceptance perhaps, about how IA can be applied by expert SEOs. True search engine optimization is intimately tied to search query types. The ‘old’ SEO technique of finding keywords to rank for is outdated because searchers have become more experienced and precise in what they’re searching for. Research on search engines, searcher behavior, and taxonomies show fascinating results where searchers aren’t satisfied with just findability. They respond to wantability. This means creating an entire information architecture that creates an experience, or an ‘this is an exactly perfect result’ reaction.”
Search Engine Land readers, do you have any beefs with information architects? Let us know in the comments below.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


