So, The CTO Hates Your SEO Project…
Columnist Eric Enge shares his tips for working with a dev team that doesn't fully understand search engine optimization.

You’ve come up with some fantastic SEO insight for your website. You know that it’s going to double your organic search traffic, and you are stoked! You bring the idea to the web dev project priority meeting and present it with a great deal of excitement, certain that it will be put to the top of the priority stack — after all, it’s a killer idea!
Then it happens. The CTO questions your competence. He or she simply believes that SEO does not work that way: “That’s stupid! Google isn’t stupid, so you must be wrong, and you are stupid.” Your jaw drops, and you don’t know what to do. The project is tabled, you have to regroup. Now, you have a much more difficult sales effort in front of you.

How can you avoid this scenario? How can you stop it from happening in the first place? The basic formula is simple:
- Understand the technical aspects of SEO better than anyone else in the room.
- Realize that you know more than anyone else as you present your plan, and let that confidence show in the presentation.
- Be able to back up your plan (and your confidence level) when the challenges arise.

In today’s column, I will focus on helping you succeed in getting your dev team to buy into those critical projects. Note that similar problems can happen with other people, as well, such as the PR team, the social media team, the CEO, etc. — but for today, the dev team will be the focus.
Classic Problems
I have had many arguments over the years with various developers, dev managers and CTOs on a variety of different points. Three of the most common ones are:
1. 302 Vs. 301 Redirects
To be fair, it does seem a bit odd that the search engines would treat these differently. For those of us in the industry, we simply know that 301 redirects are what Google prefers when content has been permanently moved.
Regardless, I still have these conversations with developers, partially because many web development platforms or content management systems default to a 302 redirect. This means you often end up with a 302 redirect simply because a developer does not pay enough attention to it.
Stuck on this one? Here are two resources to help simplify the task for you:
- Matt Cutts Explains Why Google Prefers 301 Redirects
- Excellent Explanation of the Difference Between 301 and 302 Redirects
2. Duplicate Content
There are tons of ways that sites end up with duplicate content. Once again, it can be as simple as the way your content management system is set up, or poor internal linking practices, such as linking to your pages many different ways, like linking to https://www.example.com/page/ and https://www.example.com/page and https://www.example.com/page/index.htm on your site.
I have had developers look at me like I was nuts when I explained that this makes a difference. You’ll hear things like, “Google should be able to figure that out.”
Interestingly enough, the example I gave using “example.com” was copied verbatim from the Google page on duplicate content. The rest of this Google article does a good job of laying out the issues from their perspective on duplicate content more broadly.

3. Thin Content
The causes of thin content are many and varied. One common reason this occurs is that key people involved in the site believe it gives search engines more opportunities to rank them for various search terms, so they crank out tons of pages.
However, populating tons of pages (be it tens of thousands, millions, or more) with quality content is tough, if not impossible. This leaves you with creating largely empty pages or pages filled with machine-generated content using the same sources of information available to many others.
The real issue for search engines is that they want users to get a great experience on every page they visit after clicking on one of their search results. Why? Because this defines how the user perceives the search engine. If the user ends up on a crappy page you created, they blame the search engine for sending them there. You can see the Google position on thin content here.
Basically, thin content pages give the search engines more reasons to devalue the site overall and thus lower the rankings of the pages they may have been willing to rank.
Getting Closure With Your Dev Team
For the three situations outlined above, the Google resources I provided are helpful, but often they are not enough. I have had conversations where some particularly obstinate people will still not buy in, for the simple reason that they can’t understand what makes it difficult for the search engines. To be fair, they recognize just how powerful Google’s computing technology is, and they can’t fully rationalize the reasons for the limitations.
The simple answer to what makes it so complex is scale. Let me illustrate:
- In October 2012, Matt Cutts told me that Google knew of 100 trillion web pages. More than two years later, it’s likely that this is now closer to 500 trillion.
- The search engines crawl a large percentage of these pages.
- They perform semantic analyses of all of the pages they crawl.
- They build a link map of interconnectivity out of all the links they detect.
- They throw this into a database replicated and distributed in data centers across many different points on the planet.
- They allow users to enter any arbitrary search query.
- They generally respond to that query in 0.4 seconds or less.
The technological scope of all this is staggering. Dealing with that scale has required them to make many simplifying assumptions. For example, the search engines actually have the capability to perform a certain amount of image recognition. You can see that by taking a picture of the Taj Mahal and dragging and dropping it into the search box in Google Image Search:

Once you drag it over the search box, it looks like this:
When you let go of the image, you will see the following results:
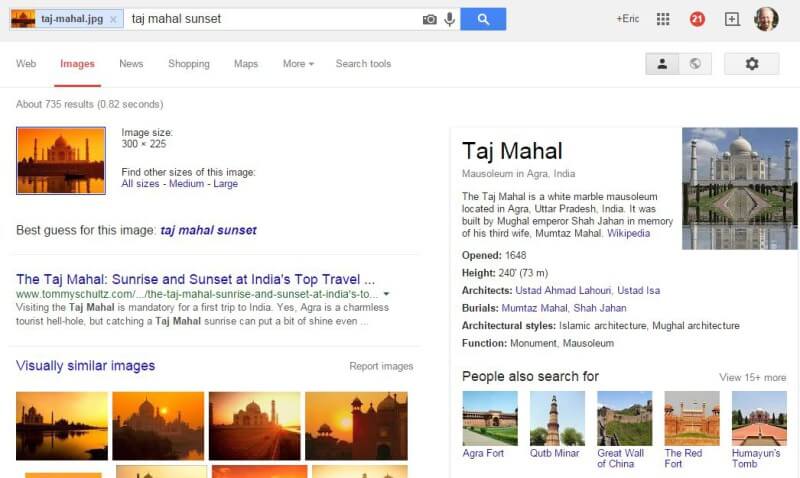
Yet, you can’t do that in the regular web search box, and Google will generally not perform image recognition in their regular web search results. You can see Google’s advice on using alt attributes here.
Why do they ask for this kind of help? Because it’s one thing to handle a one-off scenario where I drag one image over to a search box, and a completely different thing to perform image processing on all the images that Google might find on hundreds of trillions of web pages. It’s about scale.
The Bottom Line
Ultimately, you need to meet the dev team on their own turf, and get them to understand the needs of the search engines at a technical level. If that’s not you, then get some help from someone who can do that for you. If the developer in question honestly thinks you don’t know what you are talking about, and that you are proposing to waste his or her time, or the company’s resources, one can hardly blame them for not acting on your requests.
Before you go into that key meeting, have your technical chops all in line, so you can be credible in your explanation of what it is you are trying to accomplish. Once you earn their respect, the rest becomes a lot easier.
One final footnote, since earning a person’s respect is so critical to this process (as it is in many business and life situations): The first time you do this, make sure you focus on an SEO project that’s a layup — in other words, something that you are fully confident will bring great results. When you get someone to trust you for the first time, don’t let them down. Pick a clear and obvious winner if you can!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author