Employing Microformats & Structured Data For Enhanced Search Engine Visibility
With the introduction of the schema.org vocabulary, much attention has been focused on the benefits of employing structured data for improved visibility in the search engines. The mostly widely cited and easily verifiable of these benefits is the generation of rich snippets: a specially formatted search result block that includes information specific to the type […]
With the introduction of the schema.org vocabulary, much attention has been focused on the benefits of employing structured data for improved visibility in the search engines.
The mostly widely cited and easily verifiable of these benefits is the generation of rich snippets: a specially formatted search result block that includes information specific to the type of resource being referenced.
Might there be other SEO benefits to using structured data?
On one hand, Google has insisted that the advantage of employing structured data (in the form of structured markup) is limited to the production of rich snippets. On the other hand, bald claims have been made that structured data use, in and of itself, improves the ranking of Web pages in search.
I believe the truth lies somewhere in between. While employing structured data by no means guarantees superior rankings, the provision of metadata can potentially provide the search engines with a better understanding of what any given Web resource is about.
As I’ll argue, the search engines would have to willfully ignore in their ranking algorithms information they ascertained was reliable enough to return in a rich snippet. This is possible but (I think) highly unlikely.
Attribute-Based Structured Data
The most widely employed use of structured data for search visibility are mechanisms that rely on HTML attributes to encode metadata in web pages, usually referred to as structured markup.
With structured markup the presentation layer (what humans see when the look at a Web page) is separated from the data (what computers see).
In this way, search engines do less guesswork because they receive explicit information about elements on a page.
For example, 10:12 is less likely to be misinterpreted as a ratio when it is marked up in a time field.
The chief types of structured markup now widely supported are:
- Microformats – Structured markup for very specific topical realms, such as recipes (hRecipe) or people (hCard).
- Microdata – Structured markup based on HTML5 attributes and – in terms of official search engine support – referencing the schema.org vocabulary.
- RDFa – Structured markup that can draw on any number of vocabularies, making it very extensible but also more complex than microformats or microdata.
Any of these attribute-based markup formats are capable of producing rich snippets for currently supported types, such as online product offerings, reviews and events.
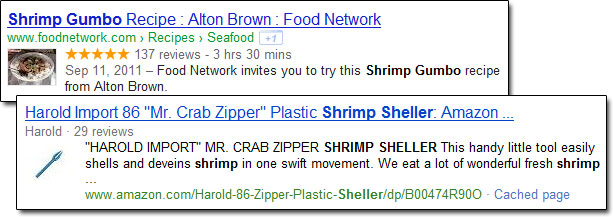
A recipe rich snippet from Google and a product rich snippet from Bing
But do they also facilitate better search engine visibility, either in the form of higher rankings in the SERPs, or the inclusion of pages in result sets for which they might otherwise be excluded?
Google asserts that “marking up your data for rich snippets won’t affect your page’s ranking in search results.”
But on the same page, we’re also informed that:
“Providing this information doesn’t affect the appearance of your content on your own pages, but it does help Google better understand and present information from your page.”
That structured markup helps Google better “present information” is, of course, self-evident insofar as they encourage its use for rich snippet generation.
What is more interesting is the statement that it helps Google to “better understand” content.
Is it not reasonable to think that when your content is better understood this might lead Google to include or elevate that content, at least where that improved understanding helped Google to better associate that content with a relevant query?
Bing ‘s article on annotating structured content provides a similar insight (without, as far as I can determine, speaking explicitly to the question of rankings, one way or the other):
“Annotating your data doesn’t actually change the visible content, but gives Bing valuable information on the type of content you’re hosting on your site. On our side, we put your annotations to good use, for example by using them to increase the visual appeal of your search results, or to supplement and validate our data sources.”
Like Google, Bing suggests here that the value of structured markup may extend past rich snippets (“the visual appeal” of search results), but also serve to provide additional information about the annotated content in general.
Again, it seems to me that better understood content, or content that might be deemed more trustworthy by dint of seemingly copasetic structured annotations, could at least potentially fare better in the search results for relevant queries.
I’ll return to this thought after looking at another type of data annotation by way of comparison: metadata rich XML files.
“Structured” Data: Beyond Attribute-Based Structured Markup
The search engines (and Google in particular) have long supported a number of different protocols that provide additional information about a resource directly through the provision of an XML file. Sitemaps and RSS feeds are what I’ll use as examples here.
To a semantic Web purist, these data types are not “structured data” because they are not, strictly speaking, related to the Resource Description Framework (RDF).
However, insofar as the search engines understand and readily consume these XML formats, they are capable of deriving the same sort of information from them as “true” structured data. In short, they provide the search engines with metadata about URIs.
Just as the benefits of structured markup may extend beyond the appearance of rich snippets in the SERPs, the benefits of sitemaps and RSS may extend past their traditionally-extolled virtues related to indexing and subscriptions, respectively.
XML sitemaps, at a basic level, allow webmasters to tell the search engines about the URLs available on a domain, and provide the search engines with hints that may expedite the re-indexing of important or frequently-changing pages.
However, they also allow webmasters to provide the search engines with more detailed information about a specific URL, including information that might not be available on the webpage itself.
Consider these examples of tags for different types of sitemaps and Google’s description of each.
- Video Sitemap <video:tag> – A short description “of key concepts associated with a video or piece of content”
- Google News Sitemap <stock_tickers> – The “stock tickers of the companies, mutual funds, or other financial entities that are the main subject of the article”
- Image Sitemap <image:geo_location> – “The geographic location of the image”
These tags all extend the value of sitemaps beyond ensuring or expediting indexation. They provide the search engines with additional information that may enable the resource to be displayed in the results for relevant queries.
The net impact of this, from an SEO perspective, is that videos, pages and images may appear in the SERPs on the basis of the metadata that has been provided.
In this way, an image tagged in an image sitemap with “Dublin, Ireland” may have a better chance of appearing in results for “photos Dublin” than the same image on another site lacking that geographical information.
Similarly, assigning a stock ticker symbol should certainly help Google ascertain whether or not a news article pertains to a corporate entity. If there’s any doubt in Google’s mind as to whether occurrences of “Apple” in a post refers to the company or the thing you eat, adding the markup “NASDAQ:AAPL ” should remove any ambiguity.
This is not to claim that employing sitemap tags is in itself sufficient to gain visibility in the SERPs for relevant queries. Google will certainly rely heavily on the context of the page in which an image appears to determine its geographical relevance, and it can almost certainly tell the difference between a fruit and a computer manufacturer in the absence of metadata.
But, if these types of sitemap-provided data do not at least potentially provide Google with a better understanding what a resource is about, then it strikes me as curious that they actively solicit this information.
The brief point I’ll make about RSS feeds are that they are conceptually similar to XML sitemaps in that they provide metadata that is consumed – and used – by the search engines (a fact often overlooked by webmasters that singularly regard RSS only as a subscription mechanism).
I once hounded a blog I read regularly to differentiate their site-wide <title> tag, although I was unable to cite their presence in the SERPs as a reason, as Google was returning the RSS title <item> in search snippets rather than the <title> tag itself. I won’t speculate on whether or not the provision of RSS aided in the ranking of their posts, but it unquestionably had a favourable influence on the visibility of those posts in the SERPs.
Visibility In Search Beyond Rich Snippets
When you use structured data, you provide the search engines with a better understanding of a resource. If employed successfully, structured data shouldn’t invoke a “uh-huh” but an A-HA! moment from the search engines: not “yeah, that’s a product price – so what?” but “that’s a product price – good to know!”
Just in the same way that traditional HTML optimization is beneficial because it provides the search engines with more information about a resource (an <img> ALT attribute, an <h1>-qualified title, and so on) so does structured data.
In the same way that a Google News sitemap can potentially help Google tell the difference between Apple and an apple, structured markup might also help in situations where disambiguation is an issue.
If you’ve told Google and Bing that your page is about the book Tom Jones rather than Tom Jones the performer, wouldn’t it stand to reason that the former would have a better chance of appearing in search results for the query “tom jones fielding” and the latter in results for “tom jones musician”?
So using structured data may not “get you high rankings” in the sense that links or lots of quality content might, but as with other metadata it absolutely has the potential to be beneficial.
If you’re a typical SEO you’ll optimize the <title> tag to make sure it contains important keywords and is descriptive of the page’s content. Does this guarantee that your page will have better visibility for a target search term? No.
But you have provided the search engines with further information about your page, that they’ll check against other data points and probably use if its valid – which is why a web page with a descriptive <title> tag typically outperforms a similar page that lacks one altogether.
The principle applies to all sorts of optimization techniques and strategies, such as optimized anchor text, flat information architecture and breadcrumbs.
These are all things that, like structured data, allow Google to better determine the topicality of your pages and your site, but themselves don’t guarantee “high rankings” simply because you’ve employed them.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author