How to fix ‘Blocked by robots.txt’ and ‘Indexed, though blocked by robots.txt’ errors in GSC
Confused by these Google Search Console errors? Learn what they mean, why they happen, and how to fix them effectively.
“Blocked by robots.txt.”
“Indexed, though blocked by robots.txt.”
These two responses from Google Search Console have divided SEO professionals since Google Search Console (GSC) error reports became a thing.
It needs to be settled once and for all. Game on.
What’s the difference between ‘Blocked by robots.txt’ vs. ‘Indexed, though blocked by robots.txt’?
There is one major difference between “Blocked by robots.txt” and “Indexed, though blocked by robots.txt.”
The indexing.
“Blocked by robots.txt” means your URLs will not appear in Google search.
“Indexed, though blocked by robots.txt” means your URLs are indexed and will appear in Google search even though you attempted to block the URLs in the robots.txt file.
Is my URL really blocked from search engines if I disallow it in the robots.txt file?
The answer: No.
No URL is entirely blocked from search engines indexing if you disallow the URL in the robots.txt file.
The scuttlebutt between SEO professionals and these Google Search Console errors is that search engines don’t completely ignore your URL if it’s listed as a disallow and blocked in the robots.txt file.
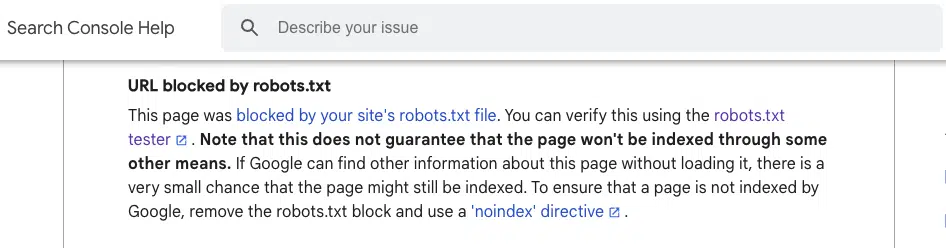
In its help documents, Google states it does not guarantee the page won’t be indexed if blocked by robots.txt.
I’ve seen this happen on websites I manage, and other SEO professionals as well.
Lily Ray shares how pages blocked by robots.txt files are eligible to appear in AI Overviews with a snippet.
This just in: pages blocked by robots.txt are eligible to appear in AI Overviews. With a snippet. 🙀
— Lily Ray 😏 (@lilyraynyc) November 19, 2024
Normally, when Google serves blocked pages in its search results, it shows “No information available for this page” in the description.
But with AIO, apparently Google shows a… pic.twitter.com/JrlSwWGJH9
Ray continues to show an example from Goodreads. One URL is currently blocked by robots.txt.
Something I see a lot of in AIO: seems like when a certain site is deemed as a good resource on the topic, that site might get 3-5 links within AIO.
— Lily Ray 😏 (@lilyraynyc) November 19, 2024
In this example, Goodreads has 5 different URLs cited in the response (including one currently blocked by robots.txt 😛) pic.twitter.com/Akilxvrk8v
Patrick Stox highlighted a URL blocked by robots.txt can be indexed if there are links pointing to the URL.
Pages blocked by robots.txt can be indexed and served on Google if they have links pointing to them.@danielwaisberg can you make this clearer in the live test warning in GSC? pic.twitter.com/6AybwEU8Bf
— Patrick Stox (@patrickstox) February 3, 2023
How do I fix ‘Blocked by robots.txt’ in Google Search Console?
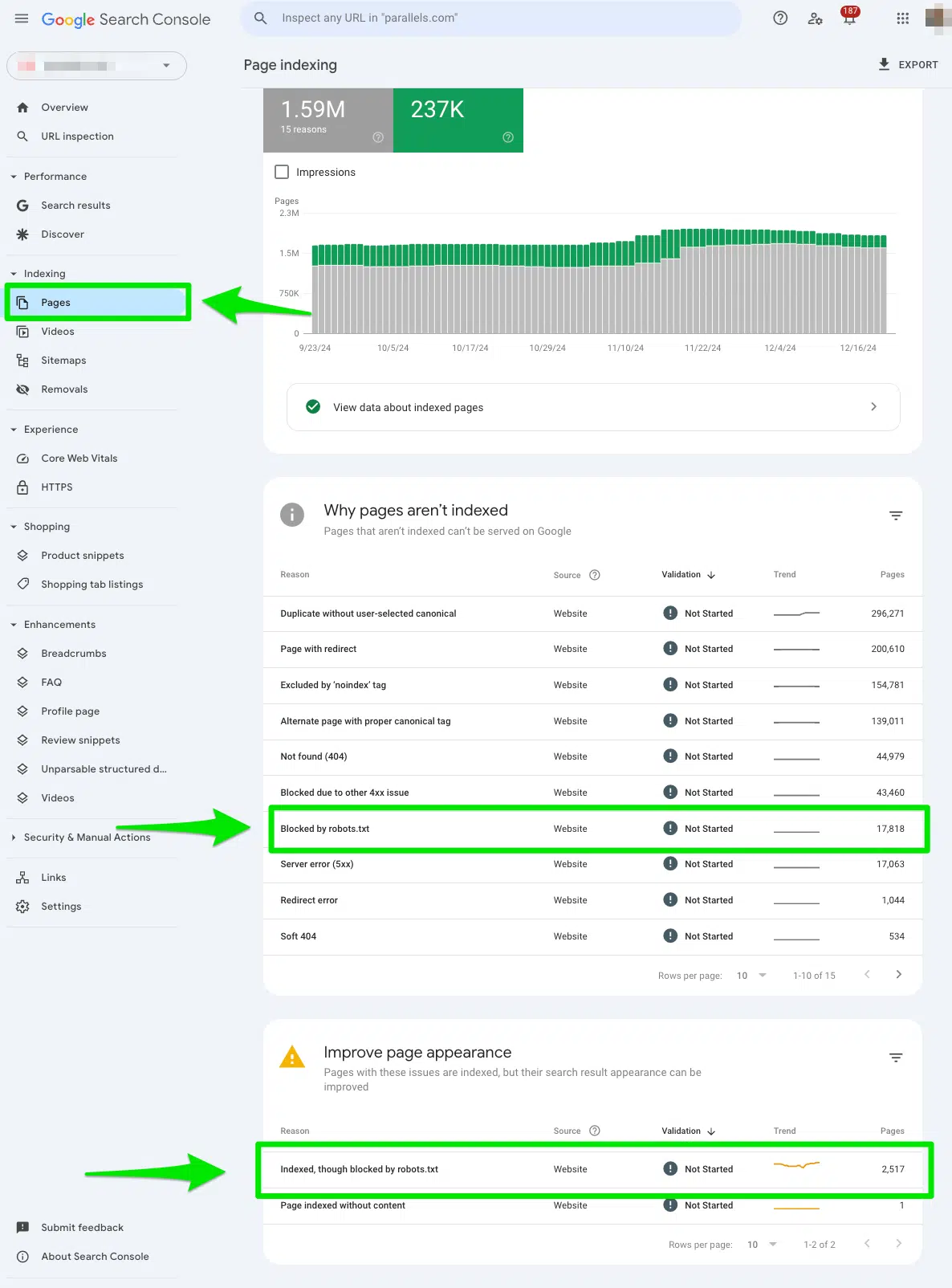
Manually review all the pages flagged in the ‘Blocked by robots.txt’report
First, I manually reviewed all the pages flagged in the Google Search Console “Blocked by robots.txt” report.
To access the report, go to Google Search Console > Pages > and look under the section Blocked by robots.txt.
Then, export the data to Google Sheets, Excel, or CSV to filter it.
Determine if you meant to block the URL from search engines
Scan your export document for high-priority URLs that are meant to be seen by search engines.
When you see the error “Blocked by robots.txt” it tells Google not to crawl the URL because you implemented a disallow directive in the robots.txt file for a specific purpose.
It’s completely normal to block a URL from search engines.
For example, you may block thank you pages from search engines. Or lead generation pages meant only for sales teams.
Your goal as an SEO professional is to determine if the URLs listed in the report are truly meant to be blocked and avoided by search engines.
If you intentionally added the disallow in the robots.txt, the report will be accurate, and no actions will be needed on your end.
If you added the disallow in the robots.txt on accident, keep reading.
Remove the disallow directive from the robots.txt if you accidentally added it by mistake
If you accidentally added a disallow directive to a URL by mistake, remove the disallow directive manually from the robots.txt file.
After you remove the disallow directive from the robots.txt file, submit the URL to the Inspect URL bar at the top of the Google Search Console.
Then, click Request indexing.
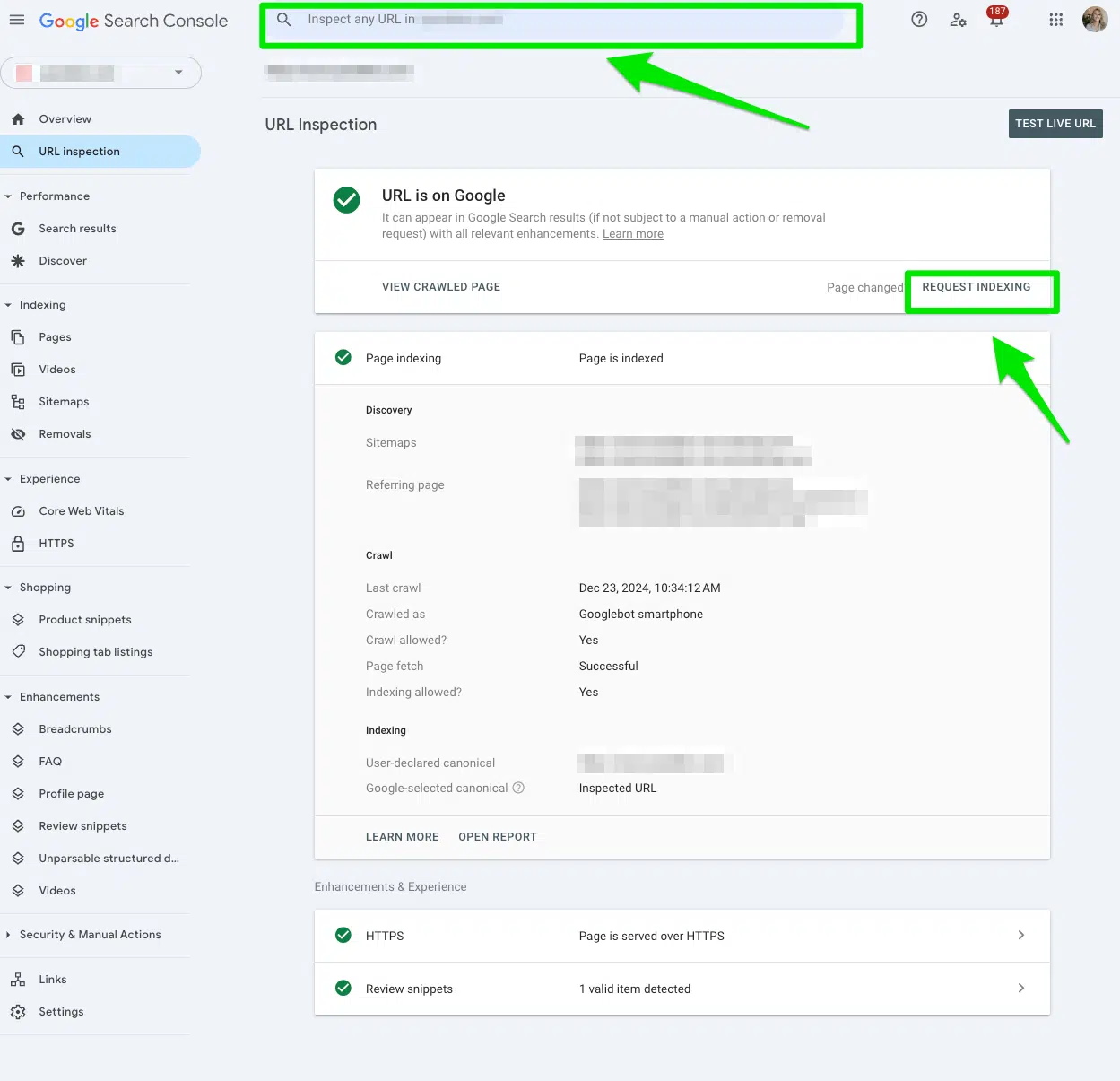
If you have multiple URLs under a whole directory, start with the first directory URL. It will have the biggest impact.
The goal is to have search engines recrawl these pages and index the URLs again.
Request to recrawl your robots.txt file
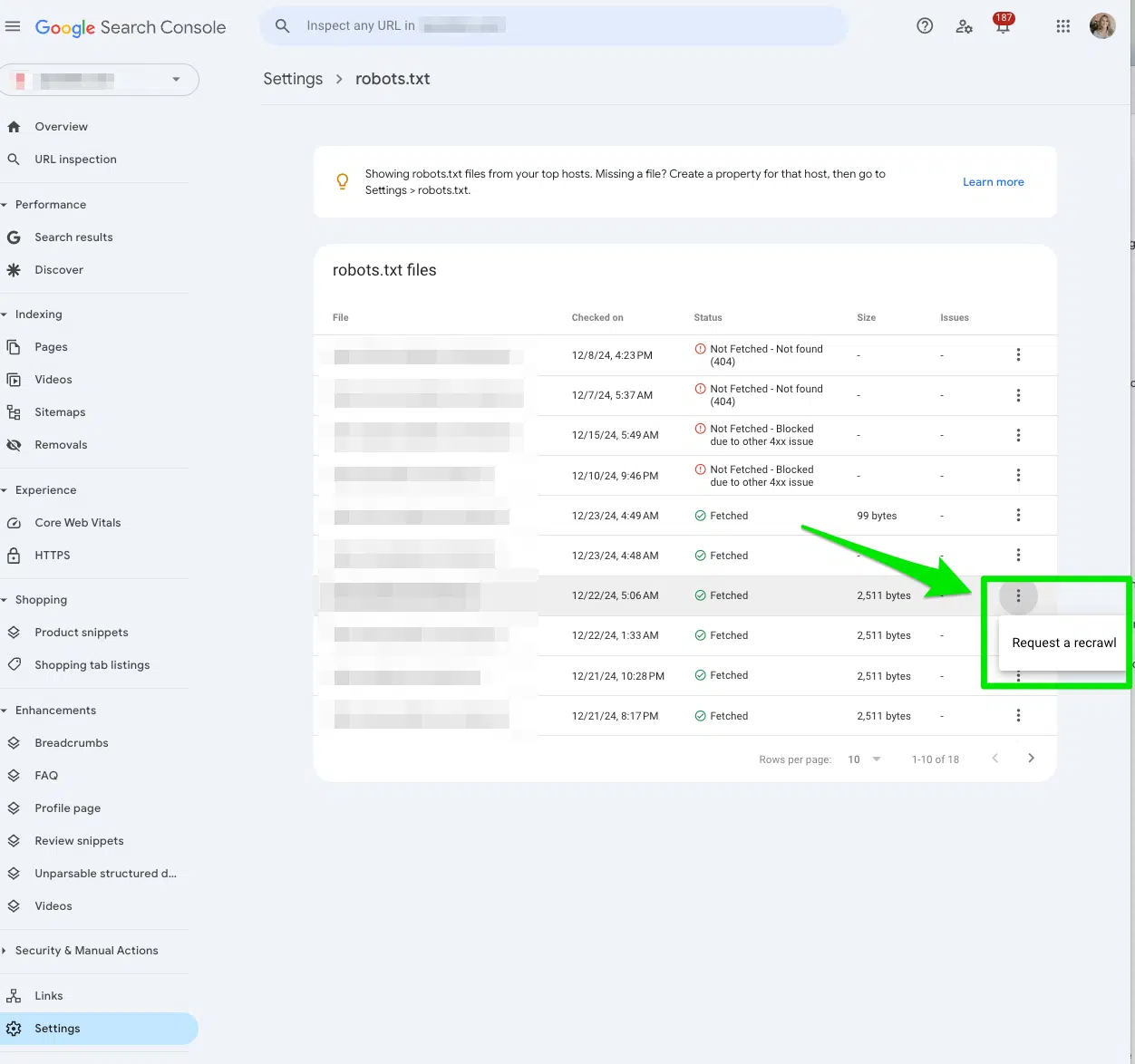
Another way to signal Google to crawl your accidentally disallowed pages is to Request a recrawl in Google Search Console.
In Google Search Console, go to Settings > robots.txt.
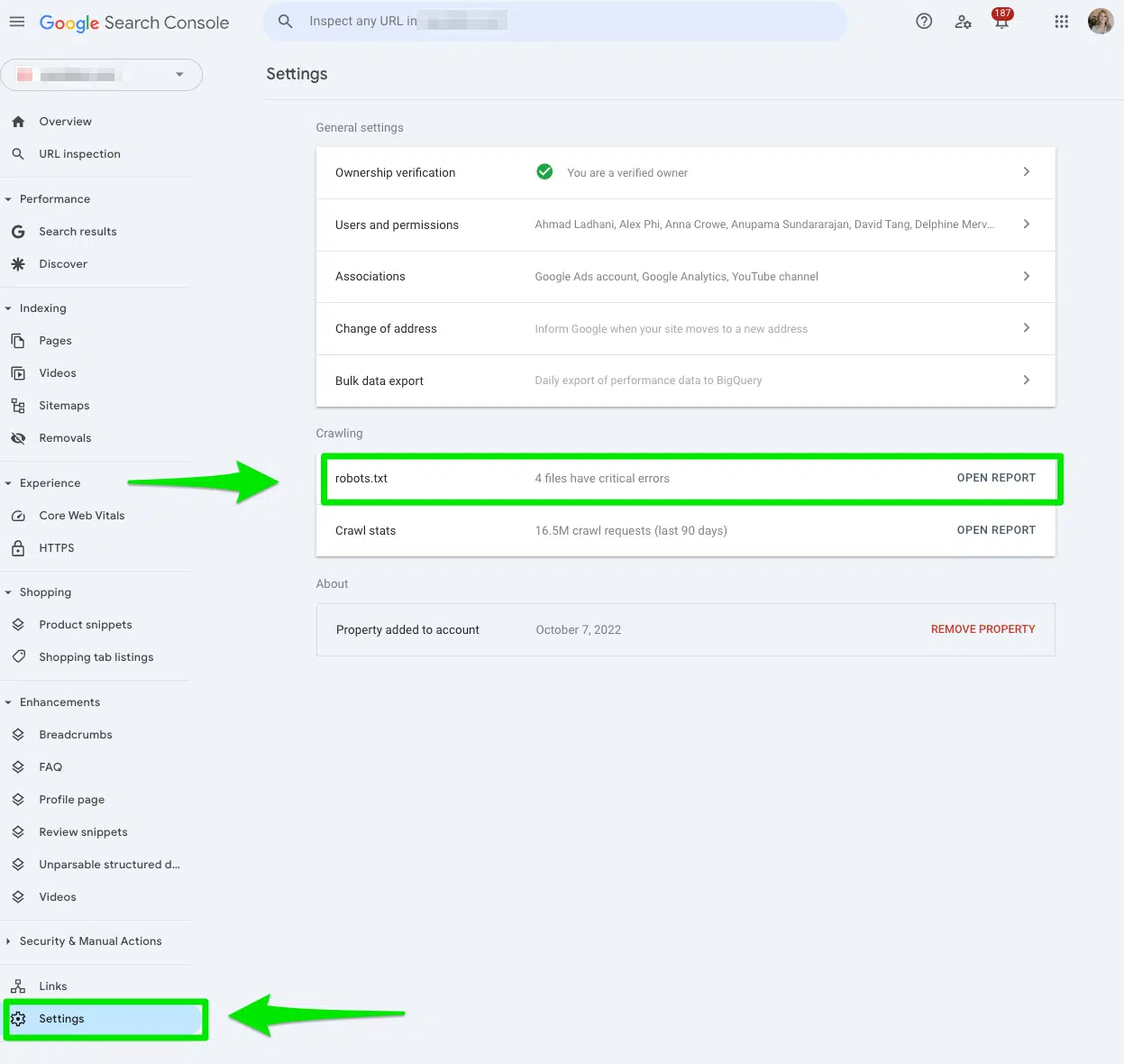
Then, select the three dots next to the robots.txt file you want Google to recrawl and select Request a recrawl.
Track the performance of before and after
Once you’ve cleaned up your robots.txt file disallow directives, and submitted your URLs to be recrawled, use the Wayback Machine to check when your robots.txt file was last updated.
This can give you an idea of the disallow directive’s potential impact on a specific URL.
Then, report on the performance for at least 90 days after indexing the URL.
How do I fix ‘Indexed, though blocked by robots.txt’ in Google Search Console?
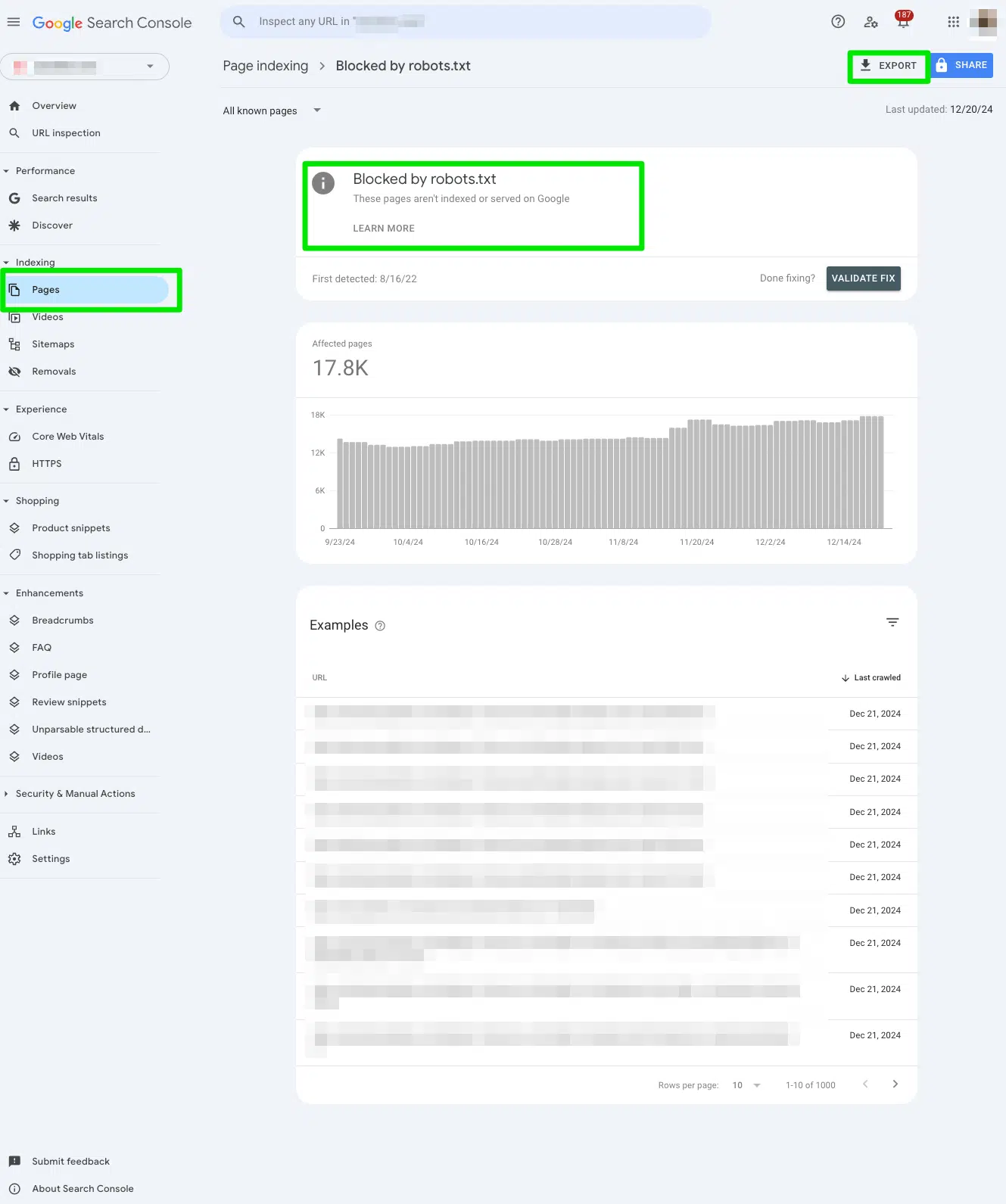
Manually review all the pages flagged in the ‘Indexed, though blocked by robots.txt’ report
Again, jump in and manually review all the pages flagged in the Google Search Console “Indexed, though blocked by robots.txt” report.
To access the report, go to Google Search Console > Pages > and look under the section Indexed, though blocked by robots.txt.
Export the data to filter it to Google Sheets, Excel, or CSV.
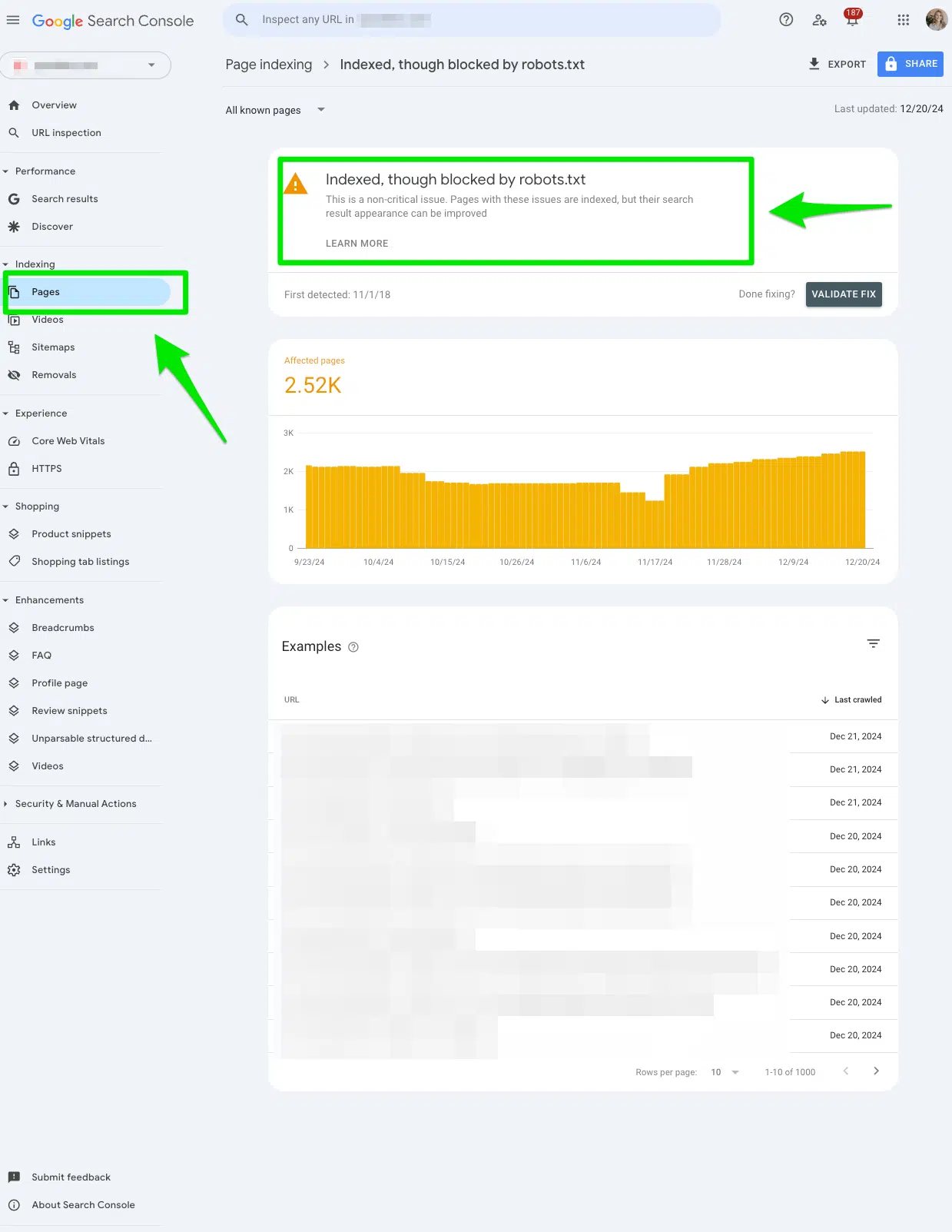
Determine if you meant to block the URL from search engines
Ask yourself:
- Should this URL really be indexed?
- Is there any valuable content for people searching on search engines?
If this URL is meant to be blocked by search engines, no actions need to be taken. This report is valid.
If this URL is not meant to be blocked by search engines, keep reading.
Remove the disallow directive from the robots.txt and request to recrawl if you want the page indexed
If you mistakenly added a disallow directive to a URL by accident, remove the disallow directive manually from the robots.txt file.
After you remove the disallow directive from the robots.txt file, submit the URL to the Inspect URL bar at the top of the Google Search Console. Then, click Request indexing.
Then, in Google Search Console, go to Settings > robots.txt > Request a recrawl.
You want Google to recrawl these pages to index the URLs and generate traffic.
Add a noindex tag if you want the page completely removed from search engines
If you don’t want the page indexed, consider adding a noindex tag instead of using the disallow directive in the robots.txt.
You still need to remove the disallow directive from robots.txt.
If you keep both, the “Indexed, though blocked by robots.txt” error report in Google Search Console will continue to grow, and you will never solve the issue.
Why would I add a noindex tag instead of using a disallow directive in the robots.txt?
If you want a URL completely removed from search engines, you must include a noindex tag. The disallow in the robots.txt file doesn’t guarantee a page will not get indexed.
Robots.txt files are not used to control indexed. Robots.txt files are used to control crawling.
Should I include both a noindex tag and a disallow directive to the same URL?
No. If you’re using a noindex tag on a URL, do not disallow the same URL in the robots.txt.
You need to let search engines crawl the noindex tag to detect it.
If you include the same URL in the disallow directive in the robots.txt file, search engines will have a hard time crawling that URL to identify that the noindex tag exists.
Creating a clear crawling strategy for your website is the way to avoid the robots.txt errors in Google Search Console
When you see either of the robots.txt error reports in Google Search Console spike, you may be tempted to renege on your stances for why you chose to block search engines from a specific URL.
I mean, can’t a URL just be blocked from search engines?
Yes, a URL should and can be blocked from search engines for a reason. Not all URLs have thoughtful, engaging content meant for search engines.
The natural, panacea to this error report in Google Search Console is always to audit your pages and determine if the content is meant for search engine eyes to see.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author