How Search Engines Work — Really!
For those of us in SEO (or aspiring to be), there are a lot of little details that fill our days. Server architecture, 301 redirects, 404 errors, title tags, and various other things. Sometimes, we forget to sit back and figure out what it all means. Add to that the fact that most SEOs were […]
For those of us in SEO (or aspiring to be), there are a lot of little details that fill our days. Server architecture, 301 redirects, 404 errors, title tags, and various other things.
Sometimes, we forget to sit back and figure out what it all means. Add to that the fact that most SEOs were never trained, but just picked things up “on the job,” and it’s no surprise that most SEOs don’t really know how search engines work.
When’s the last time you sat down and considered how search engines (like Google) really work? For me, it was last month, while writing the post about a recent Google Webmaster Hangout and the information about link disavowal that came out of it.
But before that, I think it honestly had been 8 or 10 years since I’d really thought about it. So let’s fix that. Here is a high level explanation of how one search engine (Google) works. While the terminology and order of operations may change slightly, Bing and Yahoo use a similar protocol.
Crawling Vs. Indexing
What does it mean when we say Google has “indexed” a site? For SEOs, we use that colloquially, to mean that we see the site in a [site:www.site.com] search on Google. This shows the pages in Google’s database that have been added to the database — but technically, they are not necessarily crawled, which is why you can see this from time to time:
A description for this result is not available because of this site’s robots.txt – learn more.
Indexing is something entirely different. If you want to simplify it, think of it this way: URLs have to be discovered before they can be crawled, and they have to be crawled before they can be “indexed” or more accurately, have some of the words in them associated with the words in Google’s index.
My new friend, Enrico Altavilla, described it this way, and I don’t think I can do any better than he did, so I’m giving it to you word-for-word:
An (inverted) index doesn’t contain documents but a list of words or phrases and, for each of them, a reference to all the documents that are related to that word or phrase.
We colloquially say “the document has been indexed” but that really means “some of the words related to the document now point to the document.” Documents, in their raw format, are archived elsewhere.
My old friend and former Googler, Vanessa Fox, had this to say on the subject:
Google learns about URLs… and then adds those URLs to its crawl scheduling system. It dedupes the list and then rearranges the list of URLs in priority order and crawls in that order.
The priority is based on all kinds of factors… Once a page is crawled, Google then goes through another algorithmic process to determine whether to store the page in their index.
What this means is that Google doesn’t crawl every page they know about and doesn’t index every page they crawl.
Below is a simplified version of the pipeline that was shared by Google:
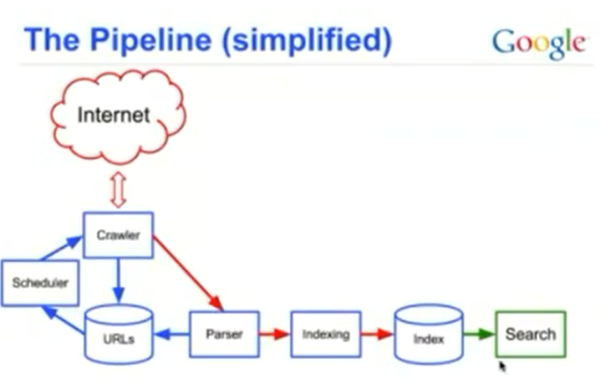
A couple of other important things to note:
• Robots.txt will only block a page from being crawled. That’s why Google sometimes has pages in its search results like the example above. Because, although Google was able to associate the page with words based on things like internal links, it wasn’t able to actually crawl the content of the page.
• Noindex commands at the page level are not definitive. Although Google can crawl the page and associate words on the page with the index, it is not supposed to include that page in search results.
However, I have seen cases where Google has included a noindexed page in their publicly available records, and Google has said it may disregard the command if other signals indicate strongly enough that the page should be indexed. This is one important area where Google differs from the rest. Yahoo and Bing will respect your noindex commands and they will not index the page or include it in search results.
One other important thing to note is that canonicals, parameter exclusion, and various other elements are also processed at some point between when Google learns about the page and when it crawls and/or indexes it.
Links And The Link Graph
The next thing SEOs need to understand are links and how they are processed. The most important thing to learn from this is that links (and, by extension, PageRank) are not processed during the crawl event. In other words, Google does the crawling as indicated above, but PageRank is not considered during the crawl — it’s done separately.
What does this mean?
- PageRank, despite what many may say, is a measure of the quantity and quality of links. It has no connection to the words on a page.
- Many SEOs believe that there are two elements of PageRank: a domain-level and a page-level PageRank. The belief is that the domain-level PageRank is the one that determines domain authority, a factor many believe is used in deciding how to rank sites. While I believe that Google likely uses some element of domain authority, this has never been confirmed by Google.
- Because PageRank is processed separately from the crawl, directives like “noindex,” “disallow,” and referrer-based blocking do not work to stop the flow of PageRank from one page to another.
- You can’t control PageRank with any kind of referrer-based tracking. In other words, you can’t block a referrer in .htaccess (for example) and expect it to work on Googlebot like a nofollow.
- Contrary to popular belief, a 302 redirect WILL pass PageRank.
- The only four things that work to stop the flow of PageRank are:
- A nofollow directive on the link at its source
- A disallow directive in the robots.txt on the page where the link originates. This works because the robots.txt command keeps the search engine from crawling the content of that page; therefore it never sees the link.
- A 404 error on the originating page.
- A 404 error on the destination page. The only reason 404s work is that both of these directives occur on the server side. When the link graph is processed, those pages are again inaccessible to the search engine. By contrast, a page blocked in robots.txt can continue to accrue PageRank, because it does exist; it just hasn’t been added to the index.
Here is a screenshot of a slide shared by Google in a Webmaster Hangout on August 20, 2012 that describes this:
![]()
The only other way to handle bad links is to disavow the link source. This has the same technical impact as adding a “nofollow” to the source link, if Google accepts it.
So That’s The Way It Works
Hopefully, how search engines work is now about as clear as mud. The key things to remember are:
- Crawling does not equal indexing.
- PageRank is separated from crawling.
- There are only four ways to block the flow of PageRank, and the only other option is disavow.
What surprised you the most? I’ll go first: I was working under the (wrong) assumption that I could block a referrer of a link in .htaccess to stop PageRank from flowing. What incorrect assumption have you been working under?
Many, many thanks to Enrico Altavilla for his invaluable assistance on fact checking for this article.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
New on Search Engine Land
About the author