Powerset Launches “Understanding Engine” For Wikipedia Content
After nearly two years in the making — and plenty of hype — Powerset has finally rolled out a "natural language" search engine. It’s not a Google killer. It’s barely a business model right now. But at least it’s something the world can finally play with, and under the hood, there’s lots of potential. By […]
After nearly two years in the making — and plenty of hype —
Powerset has
finally rolled out a "natural language" search engine. It’s not a Google killer.
It’s barely a business model right now. But at least it’s something the world
can finally play with, and under the hood, there’s lots of potential.
By the time you read this, the Powerset site should have changed into a tool
that allows you search
against material within Wikipedia. Why bother using Powerset rather than using Wikipedia’s own search tool or even Google
set to look only within Wikipedia
pages? The Powerset pitch is that you’ll get better results because
Powerset’s technology has read
and understood what every word within Wikipedia actually means.
An Understanding Engine, Not Natural Language Search
To understand that more, I beg that you forget you ever heard "natural language"
being associated with Powerset. That’s not really describing what they do in
comparison to regular search engines.
To explain, you have to understand that Google and the other major search
engines are largely stupid.
They don’t really understand the content on the pages that they "read." If they see the word "walk" in a sentence, they don’t know if walk is
being used as a verb or a noun. In very general terms, they don’t even know that
words are words. Words are more or less patterns to them — collections of
letters — and when someone
searches, they try to find the pages that have those patterns in them or in
links to those pages.
That’s VERY simplified, OK? The major search engines DO have some smarts, some
ability to know that walk is related to walking or that walk and run might be
similar words. But this is largely done through statistical guessing, rather
than comprehending what the individual words actually mean, especially in terms
of their exact grammatical usage.
Powerset is different. It says that its technology reads and comprehends each
word on a page. It looks at each sentence. It understand the words in each
sentence and how they related to each other. It works out what that sentence
really means, all the facts that are being presented. This means it knows what
any page is really about.
In lieu of a better phrase, call it an "understanding engine." Maybe that’s
not the right phrase, but natural language search isn’t it, either.
Understanding engines at least highlights the uniqueness of Powerset — that’s because
it actually
understands what pages are about — it can extract facts from those pages plus
comprehend how those facts, as well as those pages, relate to each other.
Wikipedia Discovery Tool
One of the chief uses for Powerset is employing it as a Wikipedia discovery
or query refinement tool. To use the Powerset example they gave me during a briefing last week, consider a
search for [henry viii]. What’s someone interested in in when they search on
that topic, given Henry did a lot of things during his reign?
Over at Google, we get query refinement suggestions at the bottom of the
page, like this:

At Yahoo
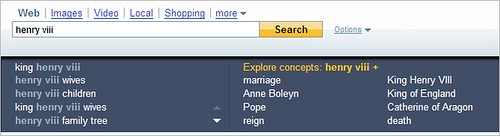
At Microsoft
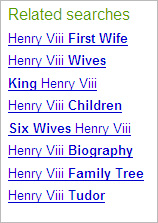
Most of these are generated by looking at the relationships between those who have
searched for one topic and then may have gone off and done another search. Yahoo
has the most sophisticated of the pack (see
Search Suggestions On
Steroids: Yahoo Search Assist), but it still hasn’t actually
"read" about Henry VIII and tried to group him into subtopics, in the way a human
might.
That’s what Powerset tries. Here’s what you get in a search for Henry VIII:
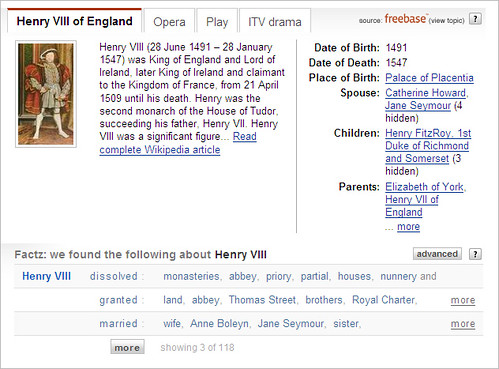
Notice the tabs at the top, where it recognizes Henry VIII could refer to the
person, the opera, the play, or even a television drama. OK, so not too amazing
when you think about it. But look further to the "Factz" area. Here you can see
that Powerset, after reading through Wikipedia, has figured out that Henry VIII
"dissolved" things like monasteries or that he "granted" things like land. And
yes, he "married" a few people.
There’s even more facts that can be found like this:
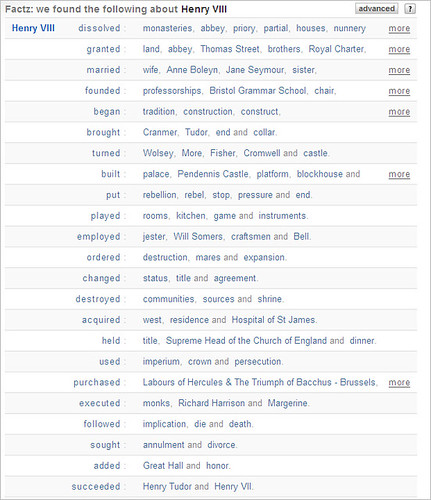
This is nice refinement. Running down the list, you can quickly scan the many
facts that define Henry’s life. And from the list, with a click, you can drill
in more about topics and jump right to particular pages within Wikipedia:
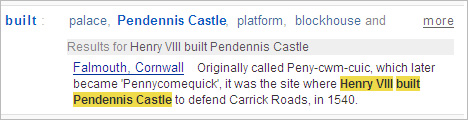
See how there’s a link to the
Falmouth, Cornwall
page? Powerset has seen that there’s something Henry VIII built mentioned on
that page, Pendennis Castle. That’s not covered on the main
Henry VIII page,
but because Powerset has read both pages and understands what they are about, it
can link the facts together.
Overkill For Now?
In short, the refinement is cool. What’s not to love about it? For one, it
might be overkill. During the demo, Powerset made a big deal on how Powerset
could build information from across various Wikipedia pages that isn’t written
on any single one of them. For example, a search for [hulk hogan]
brought this up:

See how those who Hulk Hogan has defeated are itemized? It’s nice — but do
you really trust that all the defeats have been captured? I wouldn’t. I’d
probably still go looking for an authoritative list that had been reviewed by a
human. Moreover, I can get lists
like that without great refinement. A search for
hulk hogan
victories on Google brings me to this
nice
page on About.com listing his world title victories.
In addition, while Powerset did a nice job of breaking down Henry VIII
according to Wikipedia, Wikipedia’s human editors do a pretty nice job right in
the opening paragraphs to the Henry VIII page:
Henry VIII (28
June 1491 –
28
January 1547)
was
King of England and
Lord of Ireland, later
King of Ireland and claimant to the
Kingdom of France, from
21 April
1509 until his
death. Henry was the second monarch of the
House of Tudor, succeeding his father,
Henry VII.Henry VIII was a significant figure in the history of the English monarchy.
Although in the first parts of his reign he energetically suppressed the
Reformation of the
Anglican Church, which had been building steam since
John Wycliffe of the fourteenth century, he is more often known for his
ecclesiastical struggles with Rome. These struggles ultimately led to him
separating the Anglican Church from Roman authority, the
Dissolution of the Monasteries, and establishing the English monarch as
the
Supreme Head of the Church of England. Although some claim he became a
Protestant on his death-bed, he advocated Catholic ceremony and doctrine
throughout his life; royal backing of the English Reformation was left to his
heirs,
Edward VI and
Elizabeth I. Henry also oversaw the legal union of
England and
Wales (see
Laws in Wales Acts 1535–1542). He is noted in popular culture for being
married six times.
I suspect most people hitting Wikipedia are already going to find an opening
paragraph like that, which does a
pretty good job guiding them in refining their topics about Henry VIII and pointing them to
facts.
That’s a problem for Powerset, which told me it hopes to attract lots of
those Wikipedia users to its own site, where they’ll be eventually shown ads
alongside the content (ads aren’t present at launch).
Powerset was at pains to explain how popular Wikipedia is and what a well
used resource it has become. Agreed — and plenty of those people wind up there
because they’ve done searches at Google. About 70 percent of Wikipedia users
come via search engines, according to Powerset itself. That’s a huge audience
that is NOT going to magically be routed to Powerset instead. Yes, some know to go directly
to Wikipedia. No doubt some of these users will hear of the new
Powerset tool and go there. However, it will be a
stunning achievement if these are more than a fraction of those who hit the main Wikipedia site.
Article Outlines
Powerset has another trick up its sleeve that might pull in the people. For
any page you visit, there’s an "Article Outline" box that appears within it,
like this:
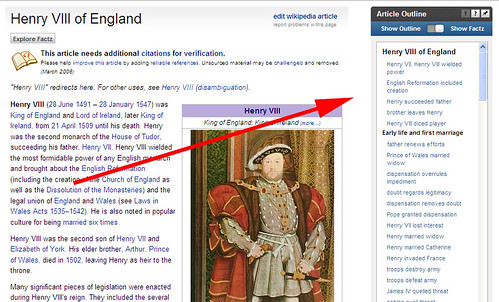
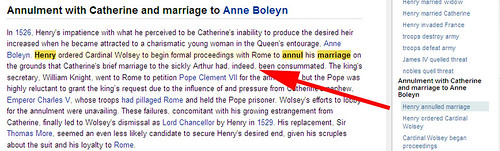
It’s very slick. Select an item, and you’re jumped to the spot within the
document related to it:
I think it’s self-evident that Powerset adds some nice value to Wikipedia.
Indeed, everyone would probably be smart to go to it directly rather than
Wikipedia itself. But as I’ve covered above, that’s not what I expect to happen.
Future In Site Search?
If Powerset fails to capture a wide audience, then what’s the way forward for
it? One area is to
provide better site-specific searching. Powerset’s technology can be applied to
any set of documents, to make it easier for people to find what they are looking
for within them. Site specific search allows those visiting a particular web
site to look just within that site. That market, along with enterprise search
(making intranets searchable) continues to grow. And the audience doing those
types of search are likely more inclined to seek out refinement options and
other exploratory tools than they are when performing general searches.
Powerset said this is a market they’re interested in, so perhaps we’ll see it
grow in that area. But for those expecting it to produce Google-wealth, keep in
mind that long-time and mature enterprise search player FAST
sold for $1.2
billion earlier this year. Yes, that’s a huge amount of money, but it’s not
the multibillions Yahoo was going to go for, and it’s much less than what Google’s valued at.
Speaking of Yahoo, it used to be the leading candidate in the past of who might
acquire Powerset, especially given some close ties between the companies (Powerset
has a number of former Yahoos on staff). Given Yahoo’s current troubles and
unstable state, I wouldn’t expect much here.
Could a tie-up with a major player like Google or Microsoft happen? Sure.
Aside from site search, the technology that allows machines to automatically
comprehend what text documents are about ought to have other applications and be
worth something. What those are and how much it is worth isn’t clear. Powerset’s
been smart to snap up many licenses and patents around the technology that
should make it attractive to a larger search player like Google or Microsoft to
acquire. Within one of these organizations, I suspect more innovative things
would come.
FYI, I wrote the above paragraph last Friday, before the rumors (see
here on News.com
and here on
Techmeme) that Microsoft might want to buy it came out over the weekend.
Actually, I started writing this article several months ago and in that, was
covering how it might be an acquisition target. It’s a fairly obvious move to
expect any of the majors to take a look, and when I talked to Powerset several
months ago, I was given the impression that all the majors had taken a look.
Since then, of course, no one has acquired it — plus the company went
through a management
shake-up last year. It was already under fire for not getting a product out
for so long. Add to these strikes as a potential Google killer the fact that it takes
Powerset about a month to comprehend Wikipedia’s 2.5 million topic pages. In
that time, many of those pages will have changed — thus needing to be reread
again. Powerset’s impressive, but with the web having in excess of 20 BILLION
constantly change pages, this is no overnight secret weapon that Microsoft might
buy and employ to take the search lead.
Indeed, what Powerset says it
has developed — along with patents locked up to protect it — is overkill for
what’s needed today. It will be more useful probably five years from now, in
ways we’re not even envisioning. For those players thinking long-term, which
include both Google and Microsoft, sure — it might well make sense to buy.
By the way, the Powerset launch will no doubt inspire interest in another
"natural language" search engine, Hakia. Someday I want to revisit Hakia and
explain more about why I also dislike the term "natural language" being applied
to it. In the meantime, you can read Vanessa Fox’s excellent article from last
October on the service,
Social Networking Through Search: Hakia Helps You Meet Others. And if you
need a deflation of natural language hype, see
The Google Challengers:
2008 Edition. In the section on Powerset, I summarize a long rant I did on
the history and hype of natural language search.
For related discussion, see Techmeme.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


