Why Google Cache lies to you and what to do about it (if anything)
You shouldn't panic if you see weirdness in the Google Cache. Still, it's worth investigating in case an odd display is a sign of a bigger problem.
 I regularly browse the SEO communities on Google Webmaster Forum, Reddit and Twitter, and I see headings like “Google Cache is empty!!!” and “404 error page in Google Cache” over and over again.
I regularly browse the SEO communities on Google Webmaster Forum, Reddit and Twitter, and I see headings like “Google Cache is empty!!!” and “404 error page in Google Cache” over and over again.
With so many people clearly afraid that Google isn’t rendering their pages correctly, I thought I’d write about the cache to help readers understand why checking Google Cache is not a reliable method of analyzing how Google sees the page.
I will also provide information on when Google Cache might be useful and what tools you should use to check how Google renders the page.
What is Google Cache?
In most cases, if you go to the Google Cache for your page, you will see the version of your page from when Google last crawled it. But what exactly are you seeing? Google Cache contains the snapshot of the raw HTML that Googlebot received from your server. Then the HTML captured by Google is rendered by your browser.
The idea behind Google storing cached pages is simple: it lets users browse a page when the page is down or in the event of a temporary timeout.
There are a few methods that will allow you to check Google Cache. The choice is yours:
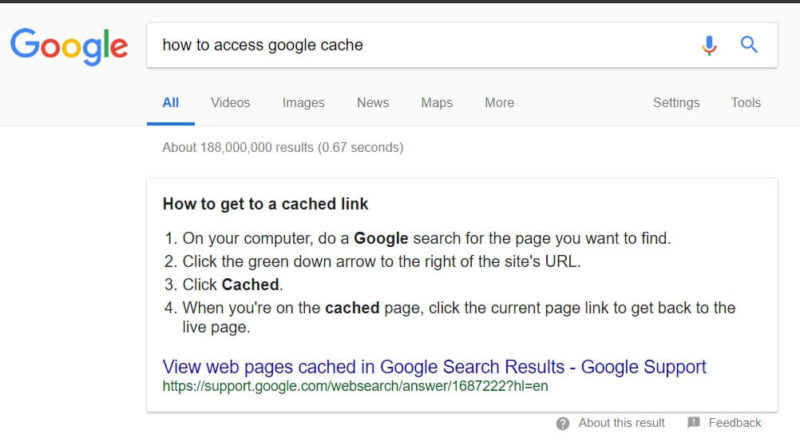
In Search results, click the arrow next to the URL in the search results and pick Google Cache. Google provides even better instructions:
You can also type the address directly in your browser. Use cache:URL and you’ll be redirected to the cache hosted by https://webcache.googleusercontent.com. Additionally, you can use one of the tools that allows for checking multiple URLs at once, such as Google Cache Checker.
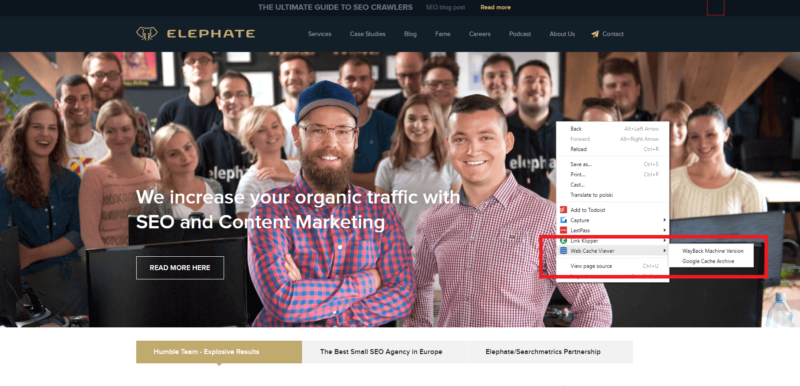
Browser plugins are also an option. For example, you can use Web Cache Viewer.
Now, go to a page you want to check. Click anywhere on the page and pick Web Cache Viewer > Google Cache Archive
Now, let’s slice and dice Google Cache. The cache view shows a few elements:
- Requested URL – this page is requested when Googlebot re-indexes the website.
- Date when the page was indexed or re-indexed by Google – keep in mind that sometimes they may use an older version of your page, so the date doesn’t provide significant information.
- 3 types of view – Full version, Text-only version and View source.
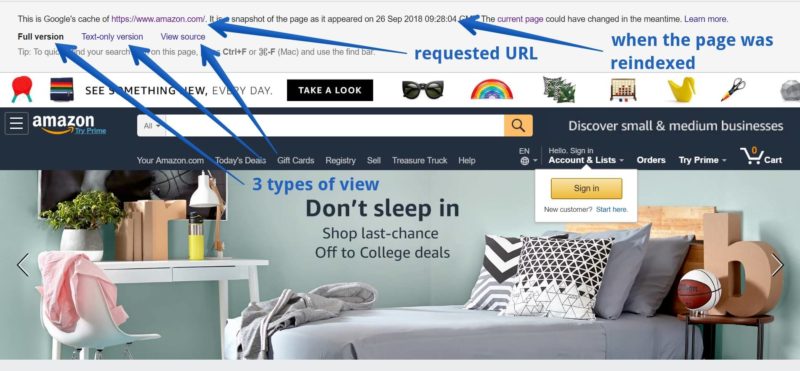
The full version shows a rendered view of the page. Keep in mind that what you see in the rendered view is the page rendered by YOUR browser, not by Google.
How do I know that this view was rendered by the browser installed on my computer rather than Web Rendering Service (WRS) used by Google? Here is a small experiment. If what I see in Google Cache is rendered by Google’s WRS, I would see the same content in the full version that Google captured while re-indexing the page.
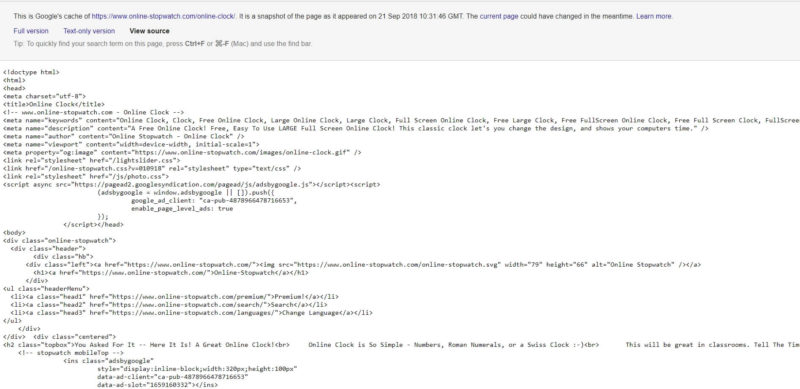
Check Google Cache for this page — Online-Stopwatch and compare the date of the last re-indexing and the time and date displayed in the cache.
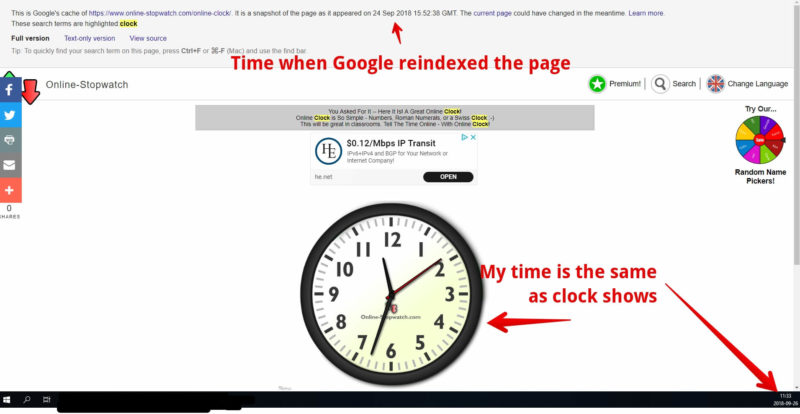
As you can see, the time and date when the site was re-indexed is different than what’s displayed on the clock. The clock shows when I checked the cache, so it is displaying the content in real time.
If the page was rendered by WRS, the time and date would be frozen and would display the same time as you see in the gray box.
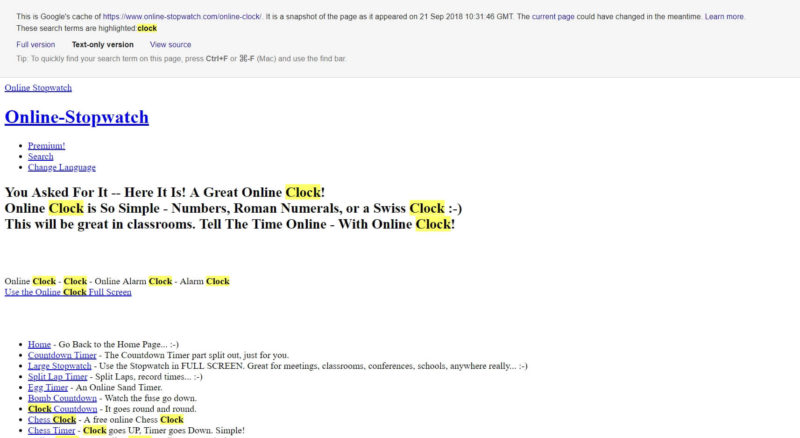
The text view is a version with CSS switched off and with no images displayed. Here you will see only the text and hyperlinks. The text view will not show the content loaded with JavaScript, so if you check the text-only version of Online-Stopwatch, the clock is gone.
The source code is nothing more the raw HTML sent by your server to Googlebot. Keep in mind that what you see in the source code view is not DOM (Document Object Model), so JavaScript is not executed.
It’s very easy to misinterpret the information presented in Google Cache. We should keep a healthy distance between what we are seeing there and how we use the data from Google Cache.
Why you shouldn’t rely on Google Cache
Now, it’s time to explain why Google Cache doesn’t show how Google “sees” your website.
As shown above, the view source in cache shows the raw HTML served to Googlebot. At the same time, the full version shows the rendered page, as rendered by your browser. These two pieces of information significantly impact how we should interpret what we see in Google Cache.
Let me guess. You probably more or less use the up-to-date version of the browser. You can check it by visiting this page. My browser is Chrome version 69.
Google, for rendering purposes, uses Web Rendering Service based on Chrome 41. Chrome 41 is a three-year-old browser and it doesn’t support all the modern features needed for proper rendering. The gap between these versions is huge, which you can see by simply comparing the supported and unsupported features in caniuse.
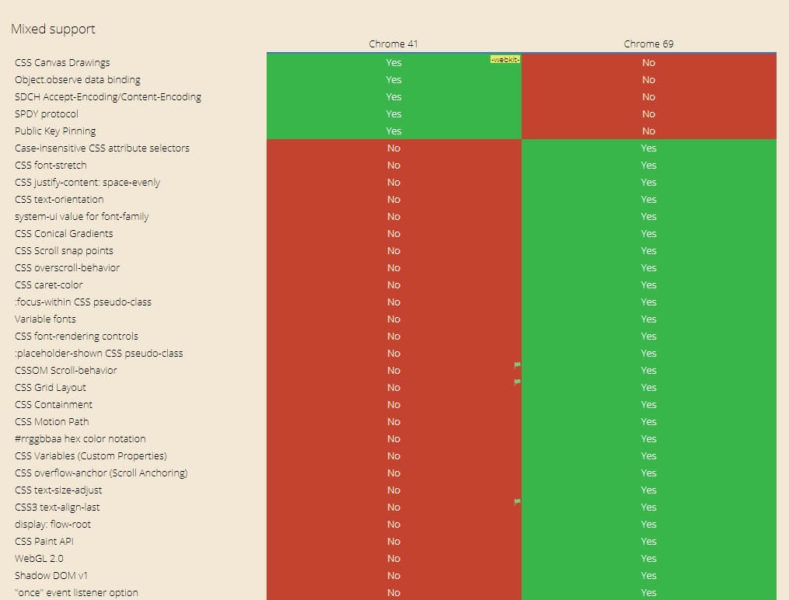
So rendering with Chrome 41 and a more up to date browser is incomparable. Even if you can see the correctly rendered version of the page in Google Cache, you can’t be sure that it also works in Chrome 41. And vice versa.
The second reason why you shouldn’t rely on Google Cache while auditing the website is content freshness. Google doesn’t always create a new snapshot while re-indexing the page. It may happen that they use an older version, even though the content may have changed twice since then. As a result, the content in the cache might be stale.
Google does not provide detailed information on how Google Cache works, but they give us hints on how we should interpret the issues discovered in Google Cache. Below you will find a review of the common issues and their causes.
Common issues observed in Google Cache
Important note: some of the anomalies observed in the cache are rather harmless, but it doesn’t mean that you should ignore them. If something isn’t working in the expected way, you should still dedicate some attention and perform a deeper investigation.
1. A page is not rendered properly
Possible reason: a resource like CSS or .js has changed.
When you visit a cached version of the page you may see that it has crashed. Some elements might not be rendered properly; some images might be missing; the fonts might differ from what you see on your website.
The reason this may occur is that the recent rendering is based on the cached version of the page, which may refer to resources that no longer exist. So if, for example, some resources — your stylesheet or some JavaScript code — have changed since the last Googlebot visit, the current rendering might not display as you’d like.
Google webmaster trends analyst John Mueller says that it happens sometimes, but it’s not something to worry about. 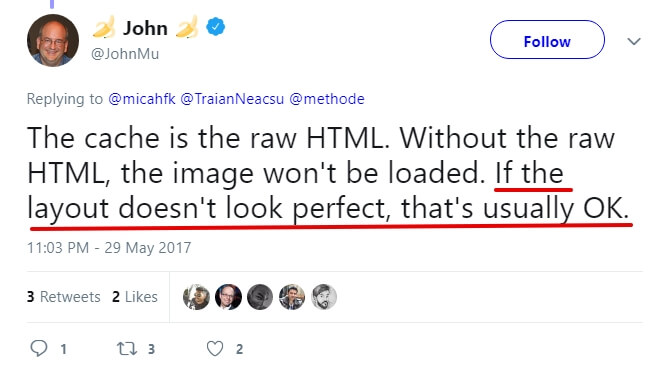
However, to make sure that Google doesn’t see a page that looks like a mess after a big party, I’d rather go into Google Search Console and perform a “fetch and render” function.
2. 404 error page in Google Cache
Reason: a website was switched to mobile-first indexing.
There was a lot of panic when Google started rolling out mobile-first indexing and it appeared that many websites were displaying 404 error pages in the cache.

It’s hard to explain why this issue occurs, because Google doesn’t provide details, but the Google Webmasters Twitter account clearly states that, although this may happen, the missing cache view won’t affect your rankings.
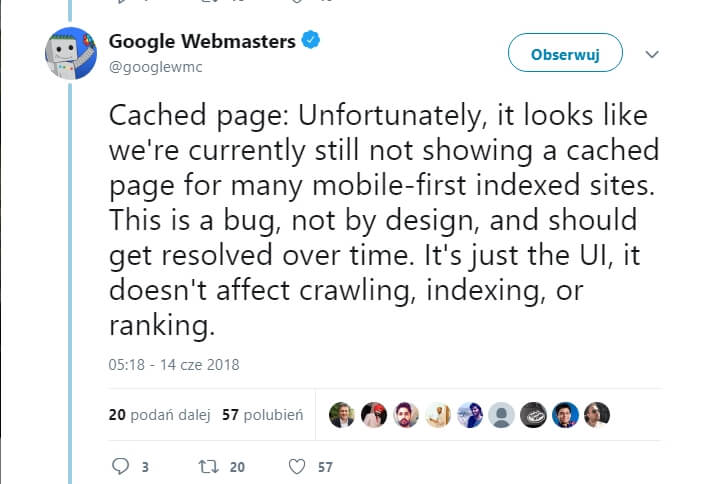
Note: some have noticed that you can use a workaround to see the correct results. Click in the address bar of the 404 page and then change the site name to something else — like “x.xyz,” for example — and then enter.
https://twitter.com/JohnMu/status/1049227580291862529
3. Cache displays a different subpage
Reason: internal duplication
One of the most confusing situations is when you open the cache view and you see a different page than expected.
You make a “site:” query to check the cached version, and the first strange symptom you can see in the search results is the meta title and meta description belonging to a different subpage.
When two pages are too similar to keep them separate in the index, Google may decide to fold the two pages together. If they don’t see significant differences between two pages and can’t understand what differentiates one from the other, they may keep only one version. This seems to be one of Google’s methods for dealing with duplicate pages.
If you want to have these two pages indexed separately, you need to review the content and answer the question: why are they marked as duplicates? In the next step, make sure that the content published in these pages is unique and responds to the users’ intent.
4. Google Cache displays a totally different domain
Reasons: external duplication, incorrect canonicalization.
When looking into Google Cache you may sometimes see a page belonging to a different domain. It might be really confusing.
Google conflates one site with another.
During one of the Google Hangouts, John Mueller mentioned a specific situation, when this may happen. Sometimes Google tries to assess the content uniqueness only by looking at the patterns in the URLs (and probably some other signals, but they don’t visit a given page). For example, if two e-commerce sites have almost the same URL structure and they share the same products IDs, Google may fold them together.

Google’s John Mueller speaking on a Webmaster hangout.
Incorrect rel=canonical tag.
Another scenario that leads to the same results is when someone has implemented a rel=canonical tag incorrectly. For example, if a developer accidentally adds a canonical tag pointing to a different domain on a page, it most probably results in the display of a different page in Google Cache view. In this case, you sent the signal to Google that these two pages are identical and they should fold them together.
My personal nightmare happened when I was diagnosing a similar issue. Apparently, before I started working on the website, some pages had an external canonical tag — only for a while, but long enough to be discovered by Google. After that, the canonical disappeared and there was no sign of their presence, but the Cache was still showing the page once cited as canonical.
Solving this mysterious issue was possible after an Inspect URL feature was added in GSC (Thank you, Google!). This allowed me to determine that Google picked an external URL as a canonical version, and it was the same URL as the user had declared. That user, a developer for the site, was in trouble.
International sites with the same content.
The last example of this issue may appear on international sites that use the same content on different domains (TLDs). For example, if you decide to publish the same content on both the German and Austrian versions of your site, Google may have problems with understanding what the relationship between them is. Even hreflang markup may not help, and Google will combine these URLs together.
In this example, take a look in the search results shown in the animated GIF below. The URL belongs to google.fr, but if you go to the cache view, you will see google.ca as the requested URL
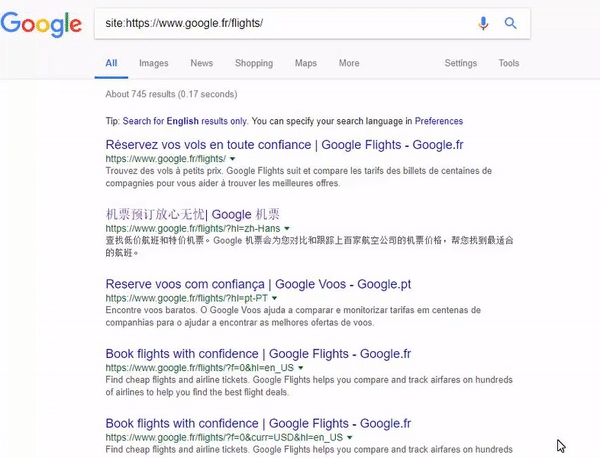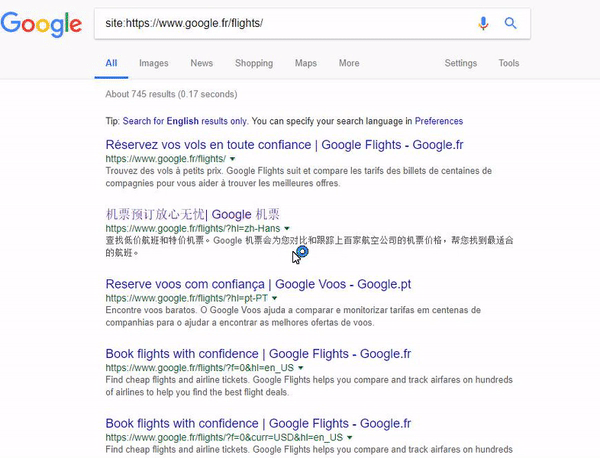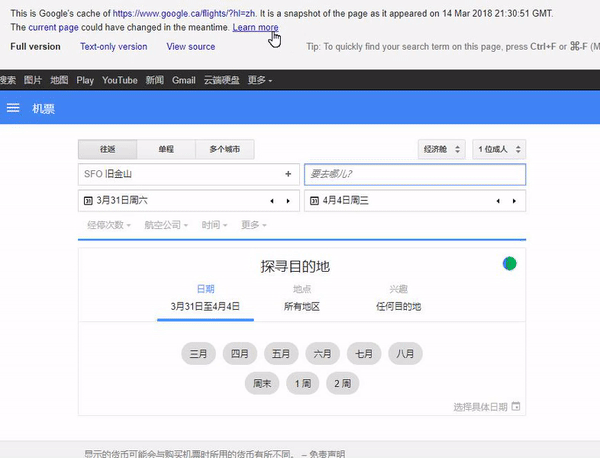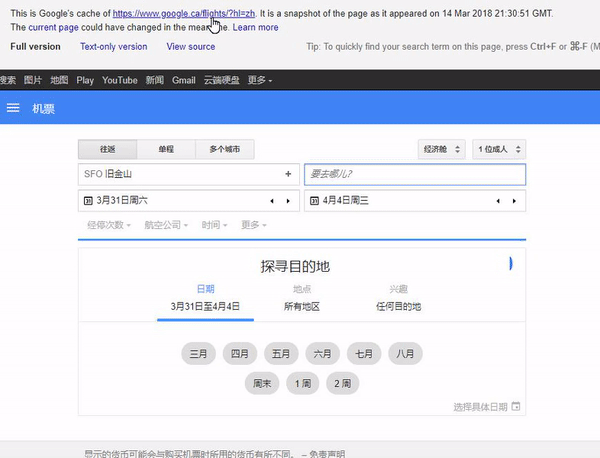
5. 404 Error page in Google Cache but the website wasn’t switched to the mobile
Reason: the page is not cached.
You can also see the 404 error page in Google Cache for a page, even if the site hasn’t yet been switched to mobile-first indexing. This may happen because Google doesn’t store a cached view for all the pages they crawl and index. Google has a huge amount of resources at its disposal, but they aren’t unlimited, so they may forego storing everything.
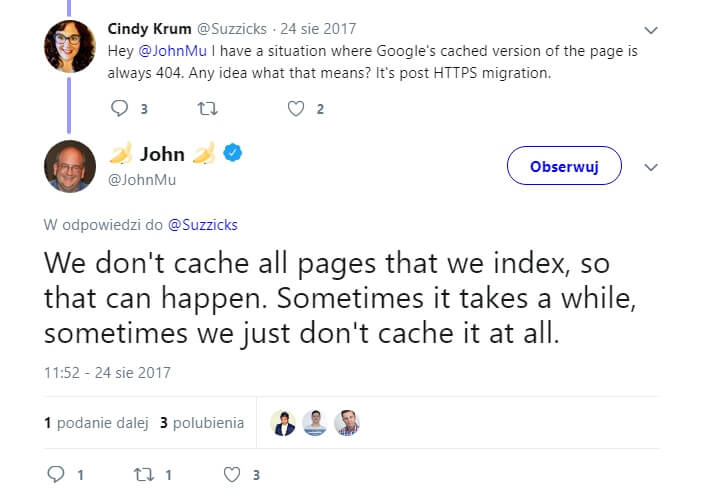
So just because a page is indexed, that doesn’t mean that the snapshot is taken. But if you have a snapshot in Google Cache, that definitely means that the page was indexed.
6. The cache is empty
Reason: the website is powered by JavaScript
If you have a JS-based website and you do not render the content in such a way to serve the rendered version to Google (e.g. with prerender or dynamic rendering), you probably will see an empty cache.
This is because the HTML of a JavaScript application may contain a few lines of code, and the rest is loaded after JavaScript execution. So if Google Cache displays the raw HTML, there is nothing to be displayed.
But even if you see an empty cache, that doesn’t mean that the content is not indexed. The rule regarding the two waves of indexing (see below) makes it so that whatever you want to load with JS probably will be indexed, but it might be deferred.
In the first wave, Google indexes the page without executing JavaScript. In the second wave, JS is executed so Google may index the content correctly.

From a technical point of view, it’s perfectly fine that the HTML of JS-powered websites don’t have too many elements to be displayed before executing JavaScript.
However, given all the issues with JS indexing, I wouldn’t rely on the rendering of my JavaScript website by Google, due to the delays in indexing. The indexing of the content may be deferred for a few days or even months!
7. There is no cache at all
Reason: noarchive meta tag is in use.

Using a noarchive meta tag prevents Google from creating snapshots that could be displayed in Google Cache. In most cases, it’s an intentional step. It’s instructing the tools or applications that they shouldn’t store the snapshots of the page.
This might be useful if the page presents sensitive data that shouldn’t be accessible. If you decide to use a noarchive meta tag, it doesn’t impact the rankings, only whether a snapshot is created and kept.
When it’s worth checking Google Cache
Google Cache shows so much information. But are they actionable? Not always. Yes, I check Google Cache while analyzing websites, but I’m not focused on solving the issues with Google Cache. I treat any problems I find there as symptoms of other issues.
Here is some information that is always valuable to me:
- In the case of JavaScript-powered websites, when I see that the cache is empty, I know that this website doesn’t serve the content to the search engines with pre-render or SSR (Server-Side Rendering). Likewise, when I see that a JS-powered website has a cache view, I know that they serve the content to Google somehow.
- When I see a different page than I expect, I know that this page may have problems with duplicate content. It’s a valuable hint while analyzing the content quality.
- Finally, while checking the cache, you can verify if Google respects your canonical tags. If yes, that’s great. If not, it’s time to take a closer look at the signals that you sent to Google relating to indexing.
Keep a healthy distance
I don’t want to discourage you from checking Google Cache while auditing websites. We can’t ignore the anomalies observed there, because we don’t know the mechanisms behind Google Cache. But we should keep calm.
Rather than panic I would recommend using one of these tools that could provide more actionable data:
- Fetch as Google in Google Search Console: here you can render the page in the same way Google does. Mobile and Desktop rendering is available.
- Mobile- Friendly Test: if you don’t have access to Google Search Console, you can always use this tool.
- Inspect URL in Google Search Console: a brilliant tool that allows for checking details on specific URLs — fetching status, date of crawling, canonicalization. In general, it provides information about what Google thinks of a given page.
- Crawlers: they will help with assessing the scale of duplicate content or thin pages — it’s a deeper analysis based on data
You should keep in mind that Google Cache is a feature for users and its ability to create and display snapshots has no impact on ranking. That said, a discrepancy that you see in Google Cache might be a symptom of other issues that may impact the ranking process, so it’s worth double checking.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author