Fetch and Horror: 3 examples of how fetch and render in GSC can reveal big SEO problems
Columnist Glenn Gabe demonstrates why discovering how Googlebot sees your desktop and mobile content is essential to any good SEO audit.

In May 2014, some powerful functionality debuted in the “fetch as Google” feature in Google Search Console — the ability to fetch and render.
When you ask Google to fetch and render, its crawler will fetch all necessary resources so it can accurately render a page, including images, CSS and JavaScript. Google then provides a preview snapshot of what Googlebot sees versus what a typical user sees. That’s important to know, since sites could be inadvertently blocking resources, which could impact how much content gets rendered.
Adding fetch and render was a big deal, since it helps reveal issues with how content is being indexed. With this functionality, webmasters can make sure Googlebot is able to fetch all necessary resources for an accurate render. With many webmasters disallowing important directories and files via robots.txt, it’s possible that Googlebot could be seeing a limited view of the page — yet the webmaster wouldn’t even know without fetch and render.
As former Googler Pierre Far said at the time, “By blocking crawling of CSS and JS, you’re actively harming the indexing of your pages.”
Therefore, a technical audit isn’t a technical audit if it doesn’t include testing pages using fetch and render. Using the tool in Google Search Console (GSC), you can test both Google’s desktop and smartphone crawlers to see how Googlebot is rendering each page on your site.
I’ll cover more about the mobile situation later in this post, but for now, I’ll focus on what can happen when you block resources. After checking your own pages, you might just look like this:

Credit: Giphy
Let’s take a closer look at three examples I’ve come across during my SEO travels.
Example 1: Whiteout conditions
There are situations when fetch and render can reveal some minor render issues, and then there are situations I call an “SEO whiteout.” That’s where little or no content is being rendered by Googlebot.
It’s a sinister situation, since typical users see a page with normal content. But Googlebot isn’t seeing much (or any) of it. So unless you are specifically looking to check what Googlebot can see, you can easily be tricked into thinking everything is fine. But it’s not.
The screen shot below is from a technical audit I performed for a larger brand. There was literally no content being rendered on certain category pages.

Initially disbelieving the result, I had to check this several times — it was literally an SEO whiteout. It turns out that all of the images, CSS and JavaScript were being blocked by robots.txt, so the render was completely breaking — and the content was not being rendered on the page.
How well do you think these pages were ranking?
Example 2: Big migration, half the content
The next example was from a large-scale CMS migration. With any large migration, there are gremlins that can cause big problems. (That’s why I wrote a post about Murphy’s Law for CMS Migrations.) It’s not uncommon for several gremlins to surface after pulling the trigger on a large-scale migration. And once they surface, you can end up trying to put out many fires (like this):

Credit: Giphy
I worked on a large-scale CMS migration recently where I noticed something strange when crawling the site as Googlebot for Smartphones. The content didn’t seem to match up well, so I headed over to GSC to use fetch and render to check out what was going on.
It took just a few seconds to surface a big problem. It turns out code was being blocked by robots.txt, so the site was mistakenly chopping off a chunk of important content for mobile users. The desktop render wasn’t great, but the mobile render was even worse.
Note: I’ll cover more about the impact of the impending mobile-first index soon, but needless to say, having a poor mobile render isn’t a good thing (as Google will be using the mobile content, rather than the desktop content, for ranking purposes).
This problem could have sat for a long time, since most business owners and webmasters check the desktop pages during audits, and not the mobile pages.
Here’s what the render looked like. No design, and chunks of main content missing:
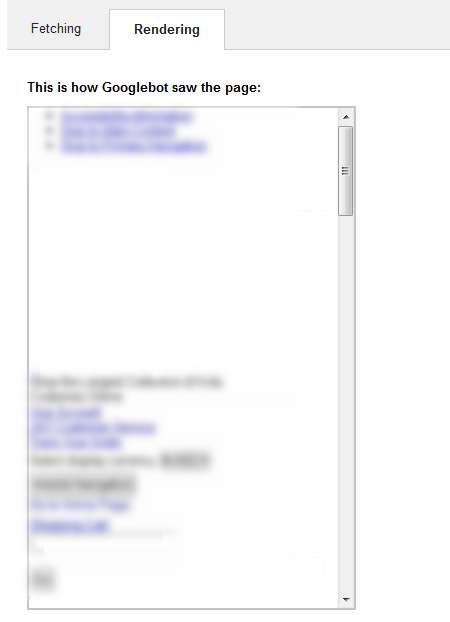
The fix was relatively easy and was implemented later that same day. The render problem was only in production for a short period of time before the company fixed the issue.
Example 3: Forbidden
The last example I’ll provide is an interesting one. The site I was auditing contains URLs that pull resources from other subdomains. But Googlebot was receiving 403 response codes when trying to fetch those resources (Forbidden: Access Denied).
The render for typical visitors was fine, but the Googlebot view had major gaps in content and 403 error messages showing up in the render.

I immediately sent the findings through to my client, and that was passed along to the dev team. If the company wanted that additional content crawled and indexed, then it’s important to make sure that Googlebot can fetch those resources (and doesn’t run into 403 errors when trying to do so). It’s just another example of the power of fetch and render.
Avoid SEO insanity: Screaming Frog now renders like Googlebot
OK, so now you have a feel for what can happen when Googlebot runs into problems when trying to accurately render your pages. But what about checking hundreds, thousands, or tens of thousands of pages? It would be crazy to manually check each page in GSC using fetch and render, right?
I totally agree, and it could lead to mild insanity. Add in the ridiculously annoying “I’m not a robot” captcha after just a few fetches in GSC, and you might start banging your head against your monitor.
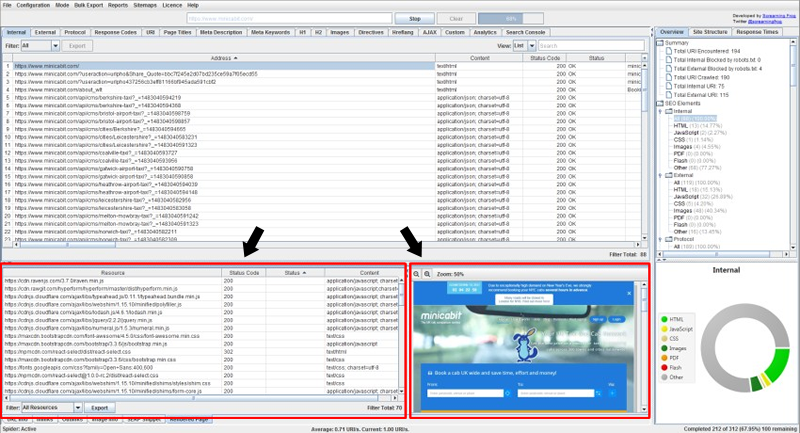
Well, the folks at Screaming Frog heard your head-banging and just added some killer functionality to an already outstanding crawling tool. Screaming Frog 7 now contains fetch and render functionality. That means you can crawl a site and view renders at scale. By the way, I’ve been looking for that option for a long time… a really long time. So it’s awesome that the crew at Screaming Frog decided to add it.
I’m not going to cover the step-by-step process, since that’s not the focus of my post; Screaming Frog recently published a post covering how to do this, so I’ll just point you there. I was part of the beta testing of fetch and render in Screaming Frog, and I have used it extensively since late fall. It’s awesome, and you can use it in staging, on a local server, on your production site and so on.
A note about Google’s mobile-first index: Use fetch and render to audit your mobile pages
I mentioned the mobile impact earlier, and it’s critically important that webmasters understand what’s coming with Google’s mobile-first index, which Google is actively testing now. (I covered this in my last column.)
Quickly breaking it down, Google is pulling a 180 for search and will begin using the mobile page as the canonical URL. That means the mobile page will be used to determine ranking (for both desktop and mobile SERPs). Therefore, I would make sure your mobile pages contain all of the content that your desktop pages contain, including any structured data being used. Up to now, the desktop page has been used for ranking purposes (for both desktop and mobile).
As we approach full rollout (possibly in Q2 of this year), you should absolutely use fetch and render using Googlebot’s smartphone crawler to see if your content is being rendered properly. As my second example above demonstrated, that’s not always the case. And if problems remain in place, then your rankings will be based on less content (or no content), depending on how bad the render situation is.
So use both Google’s fetch and render functionality and Screaming Frog’s render functionality to check all of your pages. You still have time to fix any problems, so test this NOW.

Summary: Turn ‘fetch and horror’ into ‘fetch and happiness’
In my opinion, fetch and render is one of the most powerful features in Google Search Console (GSC). With just a few clicks, you can see how Googlebot is rendering your content across both desktop and mobile. And that can shine a light on potential problems, especially in areas that might not be easy to check on a regular basis.
In addition, Screaming Frog 7 can check renders at scale. Between these two tools, you can identify and knock out render problems quickly. I recommend doing that before Google fully rolls out its mobile-first index.
Now go render some pages and make sure those snapshots look good!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Related stories
About the author