Yandex scrapes Google and other SEO learnings from the source code leak
Yandex isn't Google, but there is a lot SEOs can learn about how a modern search engine is built from reviewing this codebase.
“Fragments” of Yandex’s codebase leaked online last week. Much like Google, Yandex is a platform with many aspects such as email, maps, a taxi service, etc. The code leak featured chunks of all of it.
According to the documentation therein, Yandex’s codebase was folded into one large repository called Arcadia in 2013. The leaked codebase is a subset of all projects in Arcadia and we find several components in it related to the search engine in the “Kernel,” “Library,” “Robot,” “Search,” and “ExtSearch” archives.
The move is wholly unprecedented. Not since the AOL search query data of 2006 has something so material related to a web search engine entered the public domain.
Although we are missing the data and many files that are referenced, this is the first instance of a tangible look at how a modern search engine works at the code level.
Personally, I can’t get over how fantastic the timing is to be able to actually see the code as I finish my book “The Science of SEO” where I’m talking about Information Retrieval, how modern search engines actually work, and how to build a simple one yourself.
In any event, I’ve been parsing through the code since last Thursday and any engineer will tell you that is not enough time to understand how everything works. So, I suspect there will be several more posts as I keep tinkering.
Before we jump in, I want to give a shout-out to Ben Wills at Ontolo for sharing the code with me, pointing me in the initial direction of where the good stuff is, and going back and forth with me as we deciphered things. Feel free to grab the spreadsheet with all the data we’ve compiled about the ranking factors here.
Also, shout out to Ryan Jones for digging in and sharing some key findings with me over IM.
OK, let’s get busy!
It’s not Google’s code, so why do we care?
Some believe that reviewing this codebase is a distraction and that there is nothing that will impact how they make business decisions. I find that curious considering these are people from the same SEO community that used the CTR model from the 2006 AOL data as the industry standard for modeling across any search engine for many years to follow.
That said, Yandex is not Google. Yet the two are state-of-the-art web search engines that have continued to stay at the cutting edge of technology.
Software engineers from both companies go to the same conferences (SIGIR, ECIR, etc) and share findings and innovations in Information Retrieval, Natural Language Processing/Understanding, and Machine Learning. Yandex also has a presence in Palo Alto and Google previously had a presence in Moscow.
A quick LinkedIn search uncovers a few hundred engineers that have worked at both companies, although we don’t know how many of them have actually worked on Search at both companies.
In a more direct overlap, Yandex also makes usage of Google’s open source technologies that have been critical to innovations in Search like TensorFlow, BERT, MapReduce, and, to a much lesser extent, Protocol Buffers.
So, while Yandex is certainly not Google, it’s also not some random research project that we’re talking about here. There is a lot we can learn about how a modern search engine is built from reviewing this codebase.
At the very least, we can disabuse ourselves of some obsolete notions that still permeate SEO tools like text-to-code ratios and W3C compliance or the general belief that Google’s 200 signals are simply 200 individual on and off-page features rather than classes of composite factors that potentially use thousands of individual measures.
Some context on Yandex’s architecture
Without context or the ability to successfully compile, run, and step through it, source code is very difficult to make sense of.
Typically, new engineers get documentation, walk-throughs, and engage in pair programming to get onboarded to an existing codebase. And, there is some limited onboarding documentation related to setting up the build process in the docs archive. However, Yandex’s code also references internal wikis throughout, but those have not leaked and the commenting in the code is also quite sparse.
Luckily, Yandex does give some insights into its architecture in its public documentation. There are also a couple of patents they’ve published in the US that help shed a bit of light. Namely:
- Computer-implemented method of and system for searching an inverted index having a plurality of posting lists
- Search result ranker
As I’ve been researching Google for my book, I’ve developed a much deeper understanding of the structure of its ranking systems through various whitepapers, patents, and talks from engineers couched against my SEO experience. I’ve also spent a lot of time sharpening my grasp of general Information Retrieval best practices for web search engines. It comes as no surprise that there are indeed some best practices and similarities at play with Yandex.
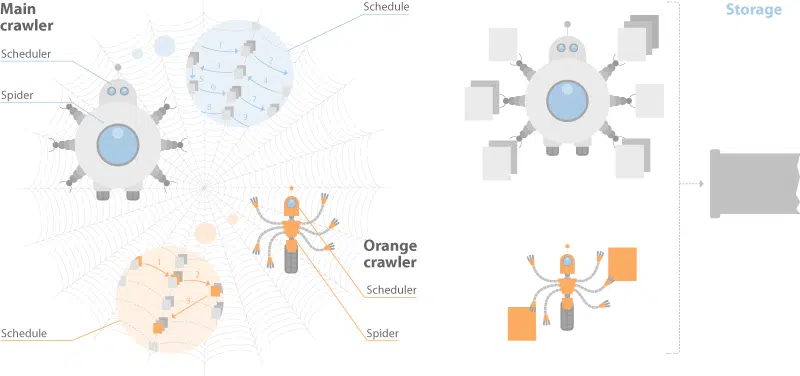
Yandex’s documentation discusses a dual-distributed crawler system. One for real-time crawling called the “Orange Crawler” and another for general crawling.
Historically, Google is said to have had an index stratified into three buckets, one for housing real-time crawl, one for regularly crawled and one for rarely crawled. This approach is considered a best practice in IR.
Yandex and Google differ in this respect, but the general idea of segmented crawling driven by an understanding of update frequency holds.
One thing worth calling out is that Yandex has no separate rendering system for JavaScript. They say this in their documentation and, although they have Webdriver-based system for visual regression testing called Gemini, they limit themselves to text-based crawl.
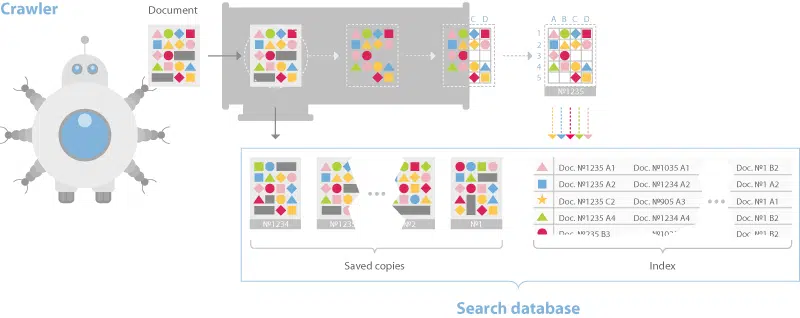
The documentation also discusses a sharded database structure that breaks pages down into an inverted index and a document server.
Just like most other web search engines the indexing process builds a dictionary, caches pages, and then places data into the inverted index such that bigrams and trigams and their placement in the document is represented.
This differs from Google in that they moved to phrase-based indexing, meaning n-grams that can be much longer than trigrams a long time ago.
However, the Yandex system uses BERT in its pipeline as well, so at some point documents and queries are converted to embeddings and nearest neighbor search techniques are employed for ranking.

The ranking process is where things begin to get more interesting.
Yandex has a layer called Metasearch where cached popular search results are served after they process the query. If the results are not found there, then the search query is sent to a series of thousands of different machines in the Basic Search layer simultaneously. Each builds a posting list of relevant documents then returns it to MatrixNet, Yandex’s neural network application for re-ranking, to build the SERP.
Based on videos wherein Google engineers have talked about Search’s infrastructure, that ranking process is quite similar to Google Search. They talk about Google’s tech being in shared environments where various applications are on every machine and jobs are distributed across those machines based on the availability of computing power.
One of the use cases is exactly this, the distribution of queries to an assortment of machines to process the relevant index shards quickly. Computing the posting lists is the first place that we need to consider the ranking factors.
There are 17,854 ranking factors in the codebase
On the Friday following the leak, the inimitable Martin MacDonald eagerly shared a file from the codebase called web_factors_info/factors_gen.in. The file comes from the “Kernel” archive in the codebase leak and features 1,922 ranking factors.
Naturally, the SEO community has run with that number and that file to eagerly spread news of the insights therein. Many folks have translated the descriptions and built tools or Google Sheets and ChatGPT to make sense of the data. All of which are great examples of the power of the community. However, the 1,922 represents just one of many sets of ranking factors in the codebase.

A deeper dive into the codebase reveals that there are numerous ranking factor files for different subsets of Yandex’s query processing and ranking systems.
Combing through those, we find that there are actually 17,854 ranking factors in total. Included in those ranking factors are a variety of metrics related to:
- Clicks.
- Dwell time.
- Leveraging Yandex’s Google Analytics equivalent, Metrika.
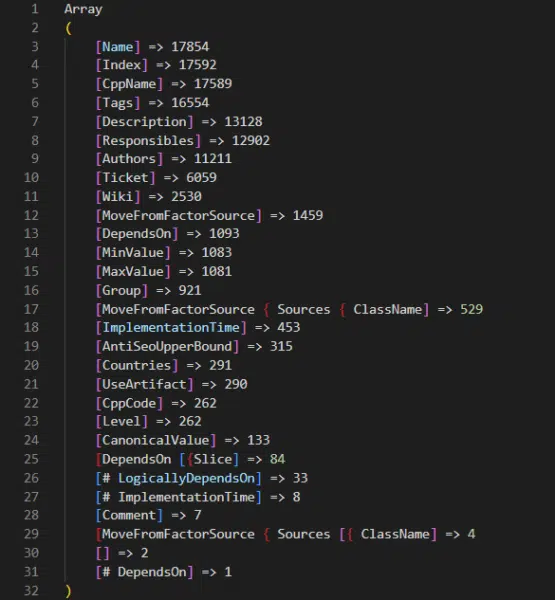
There is also a series of Jupyter notebooks that have an additional 2,000 factors outside of those in the core code. Presumably, these Jupyter notebooks represent tests where engineers are considering additional factors to add to the codebase. Again, you can review all of these features with metadata that we collected from across the codebase at this link.
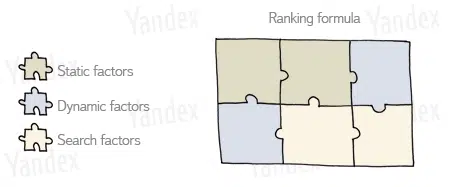
Yandex’s documentation further clarifies that they have three classes of ranking factors: Static, Dynamic, and those related specifically to the user’s search and how it was performed. In their own words:

In the codebase these are indicated in the rank factors files with the tags TG_STATIC and TG_DYNAMIC. The search related factors have multiple tags such as TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH, and TG_USER_SEARCH_ONLY.
While we have uncovered a potential 18k ranking factors to choose from, the documentation related to MatrixNet indicates that scoring is built from tens of thousands of factors and customized based on the search query.

This indicates that the ranking environment is highly dynamic, similar to that of Google environment. According to Google’s “Framework for evaluating scoring functions” patent, they have long had something similar where multiple functions are run and the best set of results are returned.
Finally, considering that the documentation references tens of thousands of ranking factors, we should also keep in mind that there are many other files referenced in the code that are missing from the archive. So, there is likely more going on that we are unable to see. This is further illustrated by reviewing the images in the onboarding documentation which shows other directories that are not present in the archive.
For instance, I suspect there is more related to the DSSM in the /semantic-search/ directory.
The initial weighting of ranking factors
I first operated under the assumption that the codebase didn’t have any weights for the ranking factors. Then I was shocked to see that the nav_linear.h file in the /search/relevance/ directory features the initial coefficients (or weights) associated with ranking factors on full display.
This section of the code highlights 257 of the 17,000+ ranking factors we’ve identified. (Hat tip to Ryan Jones for pulling these and lining them up with the ranking factor descriptions.)
For clarity, when you think of a search engine algorithm, you’re probably thinking of a long and complex mathematical equation by which every page is scored based on a series of factors. While that is an oversimplification, the following screenshot is an excerpt of such an equation. The coefficients represent how important each factor is and the resulting computed score is what would be used to score selecter pages for relevance.
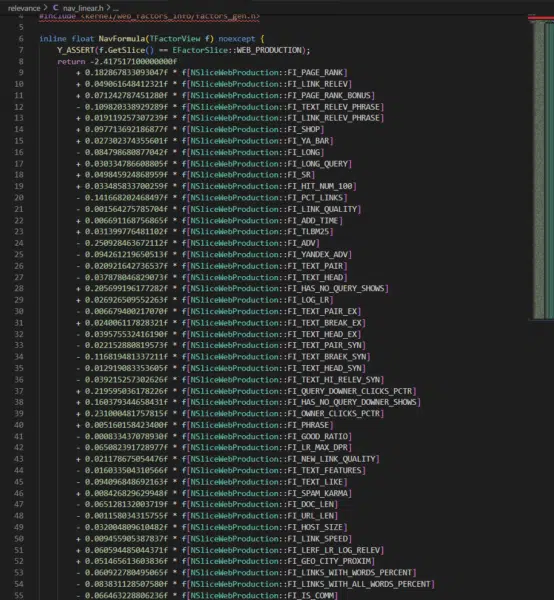
These values being hard-coded suggests that this is certainly not the only place that ranking happens. Instead, this function is most likely where the initial relevance scoring is done to generate a series of posting lists for each shard being considered for ranking. In the first patent listed above, they talk about this as a concept of query-independent relevance (QIR) which then limits documents prior to reviewing them for query-specific relevance (QSR).
The resulting posting lists are then handed off to MatrixNet with query features to compare against. So while we don’t know the specifics of the downstream operations (yet), these weights are still valuable to understand because they tell you the requirements for a page to be eligible for the consideration set.
However, that brings up the next question: what do we know about MatrixNet?
There is neural ranking code in the Kernel archive and there are numerous references to MatrixNet and “mxnet” as well as many references to Deep Structured Semantic Models (DSSM) throughout the codebase.
The description of one of the FI_MATRIXNET ranking factor indicates that MatrixNet is applied to all factors.
Factor {
Index: 160
CppName: “FI_MATRIXNET”
Name: “MatrixNet”
Tags: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHNESS_FROZEN_POOL]
Description: “MatrixNet is applied to all factors – the formula”
}
There’s also a bunch of binary files that may be the pre-trained models themselves, but it’s going to take me more time to unravel those aspects of the code.
What is immediately clear is that there are multiple levels to ranking (L1, L2, L3) and there is an assortment of ranking models that can be selected at each level.
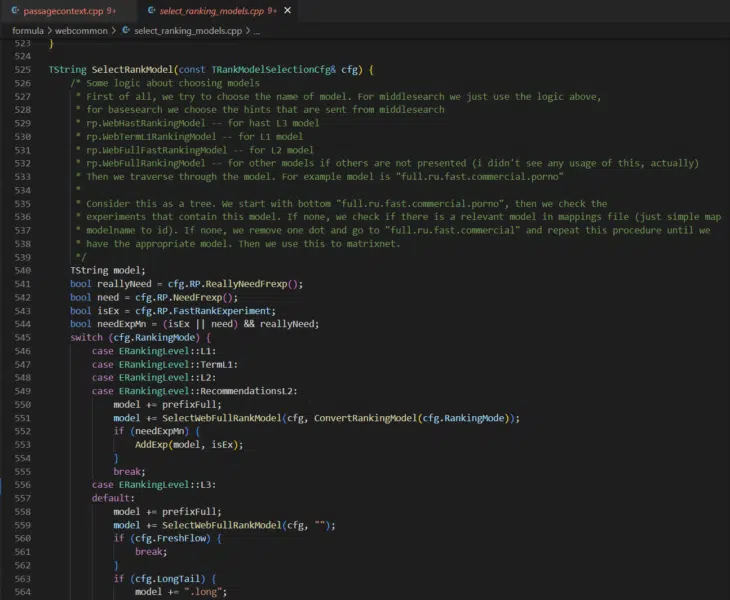
The selecting_rankings_model.cpp file suggests that different ranking models may be considered at each layer throughout the process. This is basically how neural networks work. Each level is an aspect that completes operations and their combined computations yield the re-ranked list of documents that ultimately appears as a SERP. I’ll follow up with a deep dive on MatrixNet when I have more time. For those that need a sneak peek, check out the Search result ranker patent.
For now, let’s take a look at some interesting ranking factors.
Top 5 negatively weighted initial ranking factors
The following is a list of the highest negatively weighted initial ranking factors with their weights and a brief explanation based on their descriptions translated from Russian.
- FI_ADV: -0.2509284637 -This factor determines that there is advertising of any kind on the page and issues the heaviest weighted penalty for a single ranking factor.
- FI_DATER_AGE: -0.2074373667 – This factor is the difference between the current date and the date of the document determined by a dater function. The value is 1 if the document date is the same as today, 0 if the document is 10 years or older, or if the date is not defined. This indicates that Yandex has a preference for older content.
- FI_QURL_STAT_POWER: -0.1943768768 – This factor is the number of URL impressions as it relates to the query. It seems as though they want to demote a URL that appears in many searches to promote diversity of results.
- FI_COMM_LINKS_SEO_HOSTS: -0.1809636391 – This factor is the percentage of inbound links with “commercial” anchor text. The factor reverts to 0.1 if the proportion of such links is more than 50%, otherwise, it’s set to 0.
- FI_GEO_CITY_URL_REGION_COUNTRY: -0.168645758 – This factor is the geographical coincidence of the document and the country that the user searched from. This one doesn’t quite make sense if 1 means that the document and the country match.
In summary, these factors indicate that, for the best score, you should:
- Avoid ads.
- Update older content rather than make new pages.
- Make sure most of your links have branded anchor text.
Everything else in this list is beyond your control.
Top 5 positively weighted initial ranking factors
To follow up, here’s a list of the highest weighted positive ranking factors.
- FI_URL_DOMAIN_FRACTION: +0.5640952971 – This factor is a strange masking overlap of the query versus the domain of the URL. The example given is Chelyabinsk lottery which abbreviated as chelloto. To compute this value, Yandex find three-letters that are covered (che, hel, lot, olo), see what proportion of all the three-letter combinations are in the domain name.
- FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 – The description of this factor is that is “cleverly combined of FRC and pseudo-CTR.” There is no immediate indication of what FRC is.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 – This factor is the clickability of the most important word in the domain. For example, for all queries in which there is the word “wikipedia” click on wikipedia pages.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 – The factor description says “the most characteristic query word corresponding to the site, according to the bar.” I’m assuming this means the keyword most searched for in Yandex Toolbar associated to the site.
- FI_IS_COM: +0.2762504972 – The factor is that the domain is a .COM.
In other words:
- Play word games with your domain.
- Make sure it’s a dot com.
- Encourage people to search for your target keywords in the Yandex Bar.
- Keep driving clicks.
There are plenty of unexpected initial ranking factors
What’s more interesting in the initial weighted ranking factors are the unexpected ones. The following is a list of seventeen factors that stood out.
- FI_PAGE_RANK: +0.1828678331 – PageRank is the 17th highest weighted factor in Yandex. They previously removed links from their ranking system entirely, so it’s not too shocking how low it is on the list.
- FI_SPAM_KARMA: +0.00842682963 – The Spam karma is named after “antispammers” and is the likelihood that the host is spam; based on Whois information
- FI_SUBQUERY_THEME_MATCH_A: +0.1786465163 – How closely the query and the document match thematically. This is the 19th highest weighted factor.
- FI_REG_HOST_RANK: +0.1567124399 – Yandex has a host (or domain) ranking factor.
- FI_URL_LINK_PERCENT: +0.08940421124 – Ratio of links whose anchor text is a URL (rather than text) to the total number of links.
- FI_PAGE_RANK_UKR: +0.08712279101 – There is a specific Ukranian PageRank
- FI_IS_NOT_RU: +0.08128946612 – It’s a positive thing if the domain is not a .RU. Apparently, the Russian search engine doesn’t trust Russian sites.
- FI_YABAR_HOST_AVG_TIME2: +0.07417219313 – This is the average dwell time as reported by YandexBar
- FI_LERF_LR_LOG_RELEV: +0.06059448504 – This is link relevance based on the quality of each link
- FI_NUM_SLASHES: +0.05057609417 – The number of slashes in the URL is a ranking factor.
- FI_ADV_PRONOUNS_PORTION: -0.001250755075 – The proportion of pronoun nouns on the page.
- FI_TEXT_HEAD_SYN: -0.01291908335 – The presence of [query] words in the header, taking into account synonyms
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – The percentage of the number of words, that are the 200 most frequent words of the language, from the number of all words of the text.
- FI_YANDEX_ADV: -0.09426121965 – Getting more specific with the distaste towards ads, Yandex penalizes pages with Yandex ads.
- FI_AURA_DOC_LOG_SHARED: -0.09768630485 – The logarithm of the number of shingles (areas of text) in the document that are not unique.
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – The logarithm of the number of shingles on which this owner of the document is recognized as the author.
- FI_CLASSIF_IS_SHOP: -0.1339319854 – Apparently, Yandex is going to give you less love if your page is a store.
The primary takeaway from reviewing these odd rankings factors and the array of those available across the Yandex codebase is that there are many things that could be a ranking factor.
I suspect that Google’s reported “200 signals” are actually 200 classes of signal where each signal is a composite built of many other components. In much the same way that Google Analytics has dimensions with many metrics associated, Google Search likely has classes of ranking signals composed of many features.
Yandex scrapes Google, Bing, YouTube and TikTok
The codebase also reveals that Yandex has many parsers for other websites and their respective services. To Westerners, the most notable of those are the ones I’ve listed in the heading above. Additionally, Yandex has parsers for a variety of services that I was unfamiliar with as well as those for its own services.
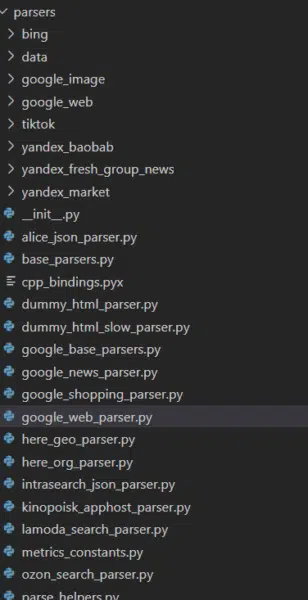
What is immediately evident, is that the parsers are feature complete. Every meaningful component of the Google SERP is extracted. In fact, anyone that might be considering scraping any of these services might do well to review this code.
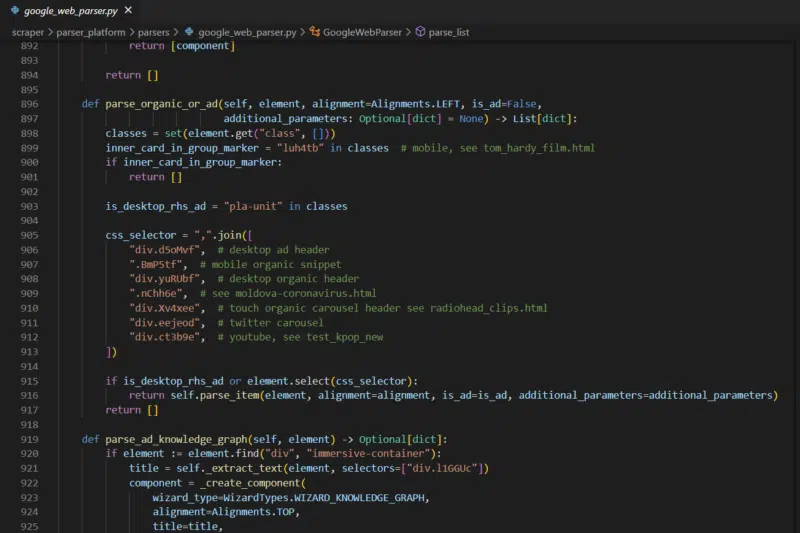
There is other code that indicates Yandex is using some Google data as part of the DSSM calculations, but the 83 Google named ranking factors themselves make it clear that Yandex has leaned on the Google’s results pretty heavily.
Obviously, Google would never pull the Bing move of copying another search engine’s results nor be reliant on one for core ranking calculations.
Yandex has anti-SEO upper bounds for some ranking factors
315 ranking factors have thresholds at which any computed value beyond that indicates to the system that that feature of the page is over-optimized. 39 of these ranking factors are part of the initially weighted factors that may keep a page from being included in the initial postings list. You can find these in the spreadsheet I’ve linked to above by filtering for the Rank Coefficient and the Anti-SEO column.

It’s not far-fetched conceptually to expect that all modern search engines set thresholds on certain factors that SEOs have historically abused such as anchor text, CTR, or keyword stuffing. For instance, Bing was said to leverage the abusive usage of the meta keywords as a negative factor.
Yandex boosts “Vital Hosts”
Yandex has a series of boosting mechanisms throughout its codebase. These are artificial improvements to certain documents to ensure they score higher when being considered for ranking.
Below is a comment from the “boosting wizard” which suggests that smaller files benefit best from the boosting algorithm.
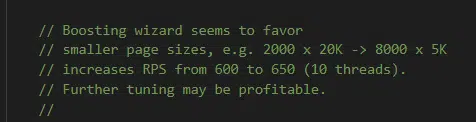
There are several types of boosts; I’ve seen one boost related to links and I’ve also seen a series of “HandJobBoosts” which I can only assume is a weird translation of “manual” changes.

One of these boosts I found particularly interesting is related to “Vital Hosts.” Where a vital host can be any site specified. Specifically mentioned in the variables is NEWS_AGENCY_RATING which leads me to believe that Yandex gives a boost that biases its results to certain news organizations.

Without getting into geopolitics, this is very different from Google in that they have been adamant about not introducing biases like this into their ranking systems.
The structure of the document server
The codebase reveals how documents are stored in Yandex’s document server. This is helpful in understanding that a search engine does not simply make a copy of the page and save it to its cache, it’s capturing various features as metadata to then use in the downstream rankings process.
The screenshot below highlights a subset of those features that are particularly interesting. Other files with SQL queries suggest that the document server has closer to 200 columns including the DOM tree, sentence lengths, fetch time, a series of dates, and antispam score, redirect chain, and whether or not the document is translated. The most complete list I’ve come across is in /robot/rthub/yql/protos/web_page_item.proto.

What’s most interesting in the subset here is the number of simhashes that are employed. Simhashes are numeric representations of content and search engines use them for lightning fast comparison for the determination of duplicate content. There are various instances in the robot archive that indicate duplicate content is explicitly demoted.

Also, as part of the indexing process, the codebase features TF-IDF, BM25, and BERT in its text processing pipeline. It’s not clear why all of these mechanisms exist in the code because there is some redundancy in using them all.
Link factors and prioritization
The codebase also reveals a lot of information about link factors and how links are prioritized.
Yandex’s link spam calculator has 89 factors that it looks at. Anything marked as SF_RESERVED is deprecated. Where provided, you can find the descriptions of these factors in the Google Sheet linked above.
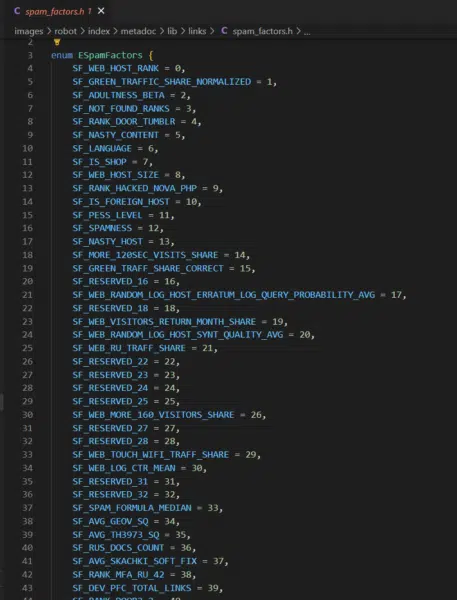
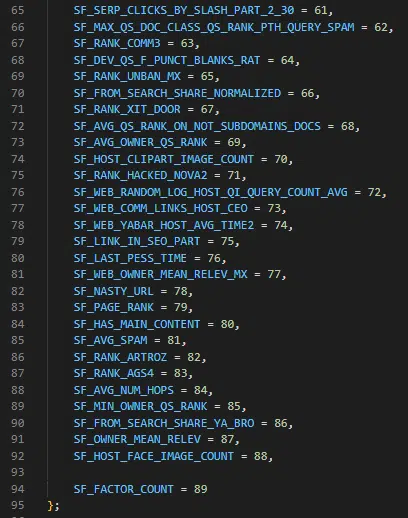
Notably, Yandex has a host rank and some scores that appear to live on long term after a site or page develops a reputation for spam.
Another thing Yandex does is review copy across a domain and determine if there is duplicate content with those links. This can be sitewide link placements, links on duplicate pages, or simply links with the same anchor text coming from the same site.

This illustrates how trivial it is to discount multiple links from the same source and clarifies how important it is to target more unique links from more diverse sources.
What can we apply from Yandex to what we know about Google?
Naturally, this is still the question on everyone’s mind. While there are certainly many analogs between Yandex and Google, truthfully, only a Google Software Engineer working on Search could definitively answer that question.
Yet, that is the wrong question.
Really, this code should help us expand our thinking about modern search. Much of the collective understanding of search is built from what the SEO community learned in the early 2000s through testing and from the mouths of search engineers when search was far less opaque. That unfortunately has not kept up with the rapid pace of innovation.
Insights from the many features and factors of the Yandex leak should yield more hypotheses of things to test and consider for ranking in Google. They should also introduce more things that can be parsed and measured by SEO crawling, link analysis, and ranking tools.
For instance, a measure of the cosine similarity between queries and documents using BERT embeddings could be valuable to understand versus competitor pages since it’s something that modern search engines are themselves doing.
Much in the way the AOL Search logs moved us from guessing the distribution of clicks on SERP, the Yandex codebase moves us away from the abstract to the concrete and our “it depends” statements can be better qualified.
To that end, this codebase is a gift that will keep on giving. It’s only been a weekend and we’ve already gleaned some very compelling insights from this code.
I anticipate some ambitious SEO engineers with far more time on their hands will keep digging and maybe even fill in enough of what’s missing to compile this thing and get it working. I also believe engineers at the different search engines are also going through and parsing out innovations that they can learn from and add to their systems.
Simultaneously, Google lawyers are probably drafting aggressive cease and desist letters related to all the scraping.
I’m eager to see the evolution of our space that’s driven by the curious people who will maximize this opportunity.
But, hey, if getting insights from actual code is not valuable to you, you’re welcome to go back to doing something more important like arguing about subdomains versus subdirectories.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. Search Engine Land is owned by Semrush. Contributor was not asked to make any direct or indirect mentions of Semrush. The opinions they express are their own.


